UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
作者: Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, Hongyang Li
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-05-09 (更新: 2025-11-03)
备注: Accepted to RSS 2025. Code is available at https://github.com/OpenDriveLab/UniVLA
💡 一句话要点
UniVLA:利用任务中心潜在动作学习跨环境机器人通用策略
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人学习 视觉语言动作 潜在动作模型 跨具身学习 通用策略
📋 核心要点
- 现有机器人学习方法依赖大量标注数据,难以跨不同机器人形态和环境泛化。
- UniVLA通过学习任务中心的潜在动作表示,从大规模异构视频数据中提取通用策略。
- 实验表明,UniVLA在多个基准测试中优于现有方法,且所需计算资源和数据量更少。
📝 摘要(中文)
本文提出UniVLA,一个用于学习跨具身视觉-语言-动作(VLA)策略的新框架,旨在解决现有方法依赖大量动作标注数据、泛化性差的问题。UniVLA的关键创新在于从视频中提取任务中心的潜在动作表示,从而利用各种具身和视角的数据。通过结合语言指令并在DINO特征空间中建立潜在动作模型,减轻了任务无关动态的影响。该通用策略从互联网规模的视频中学习,并通过高效的潜在动作解码部署到各种机器人上。实验结果表明,UniVLA在多个操作和导航基准测试以及真实机器人部署中取得了最先进的结果,且预训练计算量和下游数据量远低于OpenVLA。异构数据(包括人类视频)的加入进一步提升了性能,突显了UniVLA在促进可扩展和高效的机器人策略学习方面的潜力。
🔬 方法详解
问题定义:现有机器人学习方法严重依赖于带有动作标注的数据,这限制了它们在不同机器人形态和环境中的泛化能力。这些方法通常难以利用大规模的、未标注的视频数据,例如互联网上的视频,因为这些视频可能包含与机器人任务相关的丰富信息,但缺乏直接的动作标注。因此,如何有效地利用这些异构数据来学习通用的机器人策略是一个关键问题。
核心思路:UniVLA的核心思路是从视频数据中学习任务中心的潜在动作表示。通过将动作表示为潜在变量,模型可以学习到与具体机器人形态无关的通用动作模式。此外,利用语言指令作为任务的引导,可以帮助模型关注与任务相关的动态信息,从而减轻任务无关动态的影响。这种方法使得模型能够从各种具身和视角的数据中学习,并将其迁移到不同的机器人平台上。
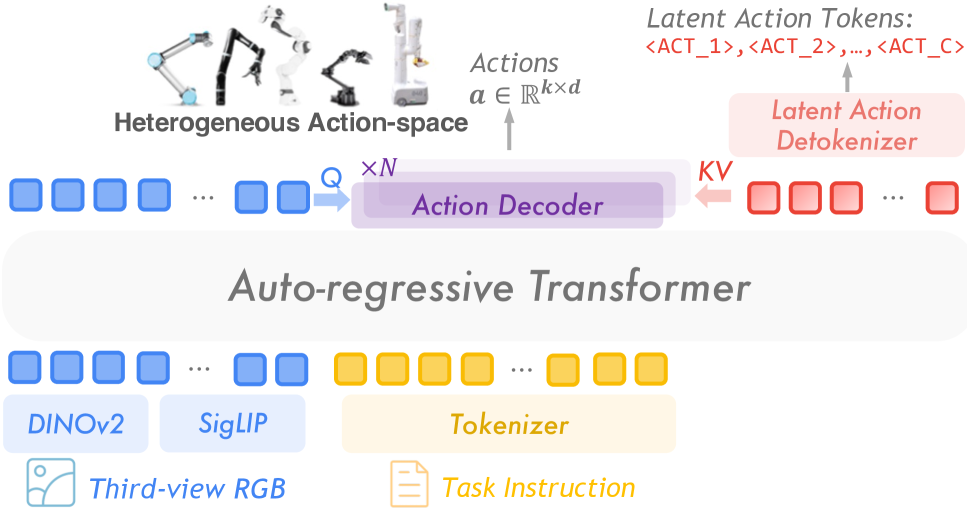
技术框架:UniVLA的整体框架包含以下几个主要模块:1) 视频编码器:用于提取视频帧的视觉特征。2) 语言编码器:用于提取语言指令的语义特征。3) 潜在动作模型:基于DINO特征空间,学习任务中心的潜在动作表示。4) 策略解码器:将潜在动作表示解码为具体的机器人动作。训练过程包括:首先,利用大规模的视频数据预训练潜在动作模型;然后,利用少量的下游数据微调策略解码器,使其能够将潜在动作映射到具体的机器人动作。
关键创新:UniVLA最重要的创新点在于提出了任务中心的潜在动作表示学习方法。与传统的直接学习动作的方法不同,UniVLA将动作表示为潜在变量,从而解耦了动作与具体的机器人形态和环境。此外,利用语言指令作为任务的引导,可以帮助模型关注与任务相关的动态信息。这种方法使得模型能够从各种异构数据中学习,并将其迁移到不同的机器人平台上。
关键设计:UniVLA的关键设计包括:1) 使用DINO特征空间作为潜在动作模型的表示空间,DINO特征具有良好的语义表达能力,可以有效地捕捉视频中的动作信息。2) 利用对比学习的目标函数来训练潜在动作模型,使得相似的动作在潜在空间中更接近,不同的动作在潜在空间中更远离。3) 使用Transformer网络作为策略解码器,将潜在动作表示映射到具体的机器人动作。4) 采用分阶段训练策略,首先预训练潜在动作模型,然后微调策略解码器,以提高模型的泛化能力。
🖼️ 关键图片

📊 实验亮点
UniVLA在多个操作和导航基准测试中取得了最先进的结果,例如在操作任务中,UniVLA的性能优于OpenVLA,且预训练计算量仅为OpenVLA的1/20,下游数据量仅为OpenVLA的1/10。此外,实验还表明,将人类视频加入到训练数据中可以进一步提升UniVLA的性能,这表明UniVLA具有很强的学习异构数据的能力。
🎯 应用场景
UniVLA具有广泛的应用前景,可应用于各种机器人操作和导航任务,例如家庭服务机器人、工业自动化机器人和自动驾驶汽车。通过利用大规模的互联网视频数据,UniVLA可以显著降低机器人学习的成本,并提高机器人的泛化能力。未来,UniVLA有望推动机器人技术的普及,使机器人能够更好地服务于人类社会。
📄 摘要(原文)
A generalist robot should perform effectively across various environments. However, most existing approaches heavily rely on scaling action-annotated data to enhance their capabilities. Consequently, they are often limited to single physical specification and struggle to learn transferable knowledge across different embodiments and environments. To confront these limitations, we propose UniVLA, a new framework for learning cross-embodiment vision-language-action (VLA) policies. Our key innovation is to derive task-centric action representations from videos with a latent action model. This enables us to exploit extensive data across a wide spectrum of embodiments and perspectives. To mitigate the effect of task-irrelevant dynamics, we incorporate language instructions and establish a latent action model within the DINO feature space. Learned from internet-scale videos, the generalist policy can be deployed to various robots through efficient latent action decoding. We obtain state-of-the-art results across multiple manipulation and navigation benchmarks, as well as real-robot deployments. UniVLA achieves superior performance over OpenVLA with less than 1/20 of pretraining compute and 1/10 of downstream data. Continuous performance improvements are observed as heterogeneous data, even including human videos, are incorporated into the training pipeline. The results underscore UniVLA's potential to facilitate scalable and efficient robot policy learning.