3D CAVLA: Leveraging Depth and 3D Context to Generalize Vision Language Action Models for Unseen Tasks
作者: Vineet Bhat, Yu-Hsiang Lan, Prashanth Krishnamurthy, Ramesh Karri, Farshad Khorrami
分类: cs.RO, cs.CV
发布日期: 2025-05-09
备注: Accepted at the 1st Workshop on 3D LLM/VLA, CVPR 2025
💡 一句话要点
提出3D-CAVLA模型,利用深度信息和3D上下文提升VLM在机器人操作任务中的泛化能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 视觉语言模型 深度学习 3D场景理解 零样本学习
📋 核心要点
- 现有视觉-语言-动作模型在机器人操作中缺乏足够的场景上下文感知能力,限制了其在复杂和未见任务中的泛化性能。
- 3D-CAVLA模型通过引入深度信息、思维链推理和任务导向的区域检测,增强了模型对3D场景的理解,从而提升了操作的准确性和鲁棒性。
- 实验结果表明,3D-CAVLA在LIBERO仿真环境中取得了显著的性能提升,尤其是在未见任务上的零样本学习能力方面。
📝 摘要(中文)
本文提出了一种名为3D-CAVLA的模型,旨在提升视觉-语言-动作模型(VLM)在3D机器人操作中的场景上下文感知能力。该模型通过整合思维链推理、深度感知和面向任务的感兴趣区域检测,改进了现有VLM模型。3D-CAVLA以RGB图像和语言指令作为输入,学习工作空间到低层控制的映射。在LIBERO仿真环境中的实验结果表明,3D-CAVLA在多个任务套件中均提高了成功率,平均成功率达到98.1%。此外,该模型在零样本学习能力方面也表现出色,证明了3D场景感知能够增强模型对全新任务的鲁棒学习和适应性,在未见任务上的成功率绝对提升了8.8%。代码和未见任务数据集将开源。
🔬 方法详解
问题定义:现有基于视觉-语言模型的机器人操作方法主要依赖RGB图像作为输入,缺乏对场景深度信息的有效利用,导致模型难以准确理解3D空间关系,泛化能力受限。尤其是在面对未见任务时,模型难以适应新的场景和目标,操作成功率较低。
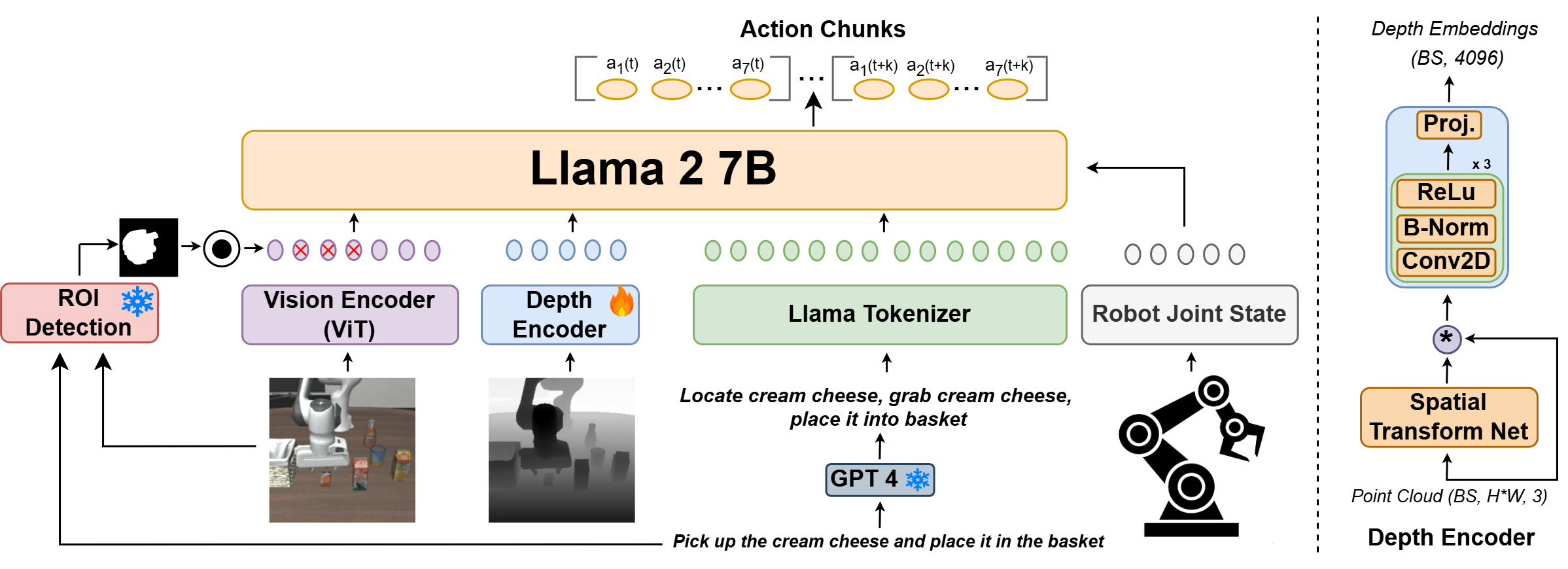
核心思路:3D-CAVLA的核心思路是通过融合深度信息和3D上下文推理,增强模型对场景的理解能力。具体来说,模型利用深度图像提取场景的几何信息,并通过思维链推理模拟人类的决策过程,从而更好地理解任务目标和规划操作步骤。此外,任务导向的区域检测可以帮助模型聚焦于与任务相关的关键区域,减少干扰,提高操作精度。
技术框架:3D-CAVLA模型主要包含以下几个模块:1) 深度感知模块:利用深度相机获取场景的深度图像,并将其与RGB图像融合,形成RGB-D图像;2) 思维链推理模块:通过prompting技术,引导模型进行逐步推理,明确任务目标和操作步骤;3) 任务导向的区域检测模块:根据语言指令,自动检测场景中与任务相关的区域,并将其作为模型的输入;4) 视觉-语言-动作模型:将RGB-D图像、语言指令和区域检测结果作为输入,预测机器人的关节空间轨迹。
关键创新:3D-CAVLA的关键创新在于将深度信息、思维链推理和任务导向的区域检测有效地结合起来,从而显著提升了视觉-语言-动作模型在机器人操作中的泛化能力。与现有方法相比,3D-CAVLA能够更好地理解3D场景,更准确地规划操作步骤,并更有效地适应未见任务。
关键设计:在深度感知模块中,使用了深度补全技术来提高深度图像的质量。在思维链推理模块中,设计了特定的prompt模板,引导模型进行有效的推理。在任务导向的区域检测模块中,使用了基于Transformer的目标检测器,能够准确地检测出与任务相关的区域。损失函数方面,使用了关节空间轨迹的L2损失和动作分类的交叉熵损失。
🖼️ 关键图片


📊 实验亮点
实验结果表明,3D-CAVLA在LIBERO仿真环境中取得了显著的性能提升。在多个任务套件中,3D-CAVLA的平均成功率达到了98.1%。更重要的是,在未见任务上,3D-CAVLA的成功率绝对提升了8.8%,证明了其强大的零样本学习能力和泛化性能。这些结果表明,深度信息和3D上下文感知对于提升视觉-语言-动作模型的性能至关重要。
🎯 应用场景
该研究成果可应用于各种需要机器人进行复杂操作的场景,例如智能制造、仓储物流、家庭服务等。通过提升机器人对3D环境的理解和操作能力,可以实现更高效、更智能的自动化生产和服务,降低人工成本,提高生产效率,并为人类提供更便捷的生活体验。
📄 摘要(原文)
Robotic manipulation in 3D requires learning an $N$ degree-of-freedom joint space trajectory of a robot manipulator. Robots must possess semantic and visual perception abilities to transform real-world mappings of their workspace into the low-level control necessary for object manipulation. Recent work has demonstrated the capabilities of fine-tuning large Vision-Language Models (VLMs) to learn the mapping between RGB images, language instructions, and joint space control. These models typically take as input RGB images of the workspace and language instructions, and are trained on large datasets of teleoperated robot demonstrations. In this work, we explore methods to improve the scene context awareness of a popular recent Vision-Language-Action model by integrating chain-of-thought reasoning, depth perception, and task-oriented region of interest detection. Our experiments in the LIBERO simulation environment show that our proposed model, 3D-CAVLA, improves the success rate across various LIBERO task suites, achieving an average success rate of 98.1$\%$. We also evaluate the zero-shot capabilities of our method, demonstrating that 3D scene awareness leads to robust learning and adaptation for completely unseen tasks. 3D-CAVLA achieves an absolute improvement of 8.8$\%$ on unseen tasks. We will open-source our code and the unseen tasks dataset to promote community-driven research here: https://3d-cavla.github.io