Demystifying Diffusion Policies: Action Memorization and Simple Lookup Table Alternatives
作者: Chengyang He, Xu Liu, Gadiel Sznaier Camps, Guillaume Sartoretti, Mac Schwager
分类: cs.RO
发布日期: 2025-05-09
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
揭示扩散策略的本质:动作记忆与简单查找表替代方案
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 扩散策略 机器人操作 动作查找表 对比学习 分布外检测
📋 核心要点
- 扩散策略在机器人操作中表现出色,但其原因尚不明确,尤其是在数据稀疏的情况下。
- 论文提出扩散策略实际上是在记忆动作查找表,通过在潜在空间中寻找最近邻训练数据来执行动作。
- 实验表明,简单的动作查找表(ALT)在小数据集上可以匹配扩散策略的性能,同时显著降低计算成本。
📝 摘要(中文)
扩散策略在复杂、高维机器人操作任务中表现出卓越的灵活性和鲁棒性,尤其是在少量演示数据下训练时。然而,这种性能背后的原因仍然未知。本文提出了一个令人惊讶的假设:扩散策略本质上是在记忆一个动作查找表,并且这种记忆是有益的。我们认为,在运行时,扩散策略在潜在空间中找到与测试图像最接近的训练图像,并回忆相关的训练动作序列,从而提供反应性,而无需动作泛化。这在稀疏数据情况下非常有效,因为数据密度不足以让模型学习动作泛化。我们用系统的经验证据支持这一观点。即使以猫和狗的极端分布外(OOD)图像为条件,扩散策略仍然输出训练数据中的动作序列。基于此,我们提出了一种简单的策略,即动作查找表(ALT),作为扩散策略的轻量级替代方案。我们的ALT策略使用对比图像编码器作为哈希函数来索引最接近的相应训练动作序列,显式地执行扩散策略隐式学习的计算。实验表明,对于相对较小的数据集,ALT的性能与扩散模型相匹配,同时只需要0.0034的推理时间和0.0085的内存占用,从而允许在资源受限的机器人上进行更快的闭环推理。我们还训练了ALT策略,以便在运行时图像在潜在空间中与训练图像的距离太远时,给出明确的OOD标志,从而提供一个简单但有效的运行时监控器。
🔬 方法详解
问题定义:现有扩散策略在机器人操作任务中表现出色,但其内在机制尚不明确,尤其是在数据稀疏的情况下,模型如何泛化到新的状态是一个挑战。此外,扩散策略的计算成本较高,限制了其在资源受限的机器人上的应用。
核心思路:论文的核心思路是揭示扩散策略实际上是在记忆动作查找表。在运行时,扩散策略通过在潜在空间中寻找与当前状态最相似的训练状态,并直接复用对应的动作序列,从而实现控制。这种“记忆”而非“泛化”的策略在数据稀疏时反而有效。
技术框架:论文提出了动作查找表(ALT)策略,作为扩散策略的替代方案。ALT策略包含以下几个主要模块:1) 对比图像编码器:将图像编码到潜在空间中,作为哈希函数的输入。2) 动作查找表:存储训练数据中的状态(潜在空间编码)和对应的动作序列。3) 最近邻搜索:在运行时,使用对比图像编码器将当前状态编码到潜在空间,并在动作查找表中寻找最近邻。4) 动作执行:执行与最近邻状态对应的动作序列。
关键创新:论文最重要的技术创新点在于揭示了扩散策略的“动作记忆”本质,并提出了显式的动作查找表(ALT)策略作为替代方案。与扩散策略相比,ALT策略更加简单、高效,且易于理解和调试。此外,ALT策略还可以通过设置距离阈值来检测分布外(OOD)状态,从而提高系统的鲁棒性。
关键设计:ALT策略的关键设计包括:1) 对比图像编码器的选择和训练,需要保证潜在空间能够有效区分不同的状态。2) 最近邻搜索算法的选择,需要在计算效率和精度之间进行权衡。3) OOD检测阈值的设置,需要根据具体任务和数据集进行调整。论文中使用了对比损失函数来训练图像编码器,并使用简单的欧氏距离作为最近邻搜索的度量。
🖼️ 关键图片
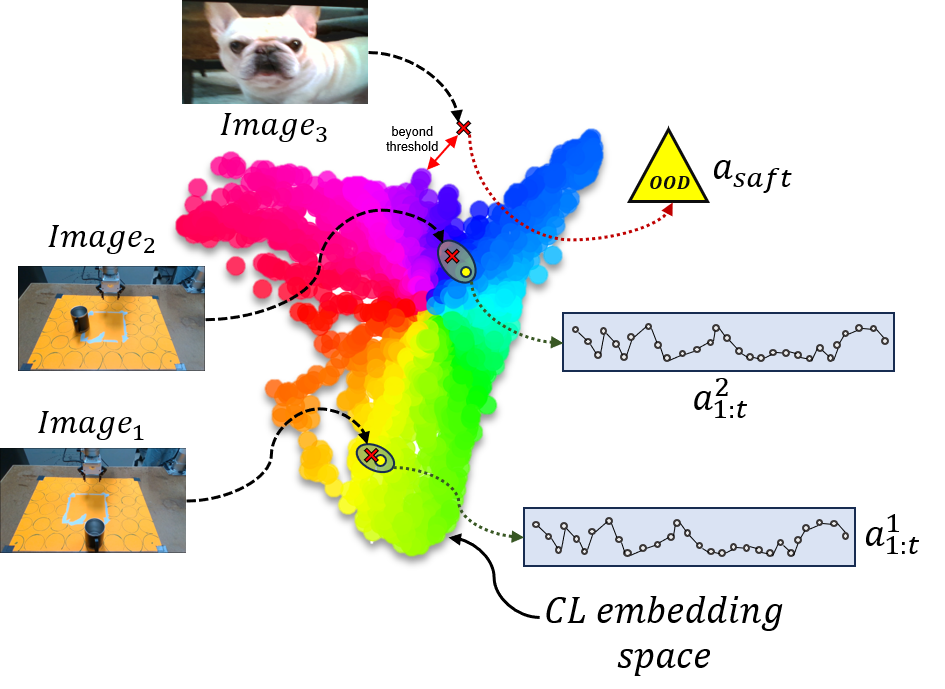

📊 实验亮点
实验结果表明,在相对较小的数据集上,动作查找表(ALT)策略的性能与扩散模型相匹配,同时只需要0.0034的推理时间和0.0085的内存占用。这表明ALT策略是一种有效的扩散策略替代方案,尤其适用于资源受限的机器人。
🎯 应用场景
该研究成果可应用于资源受限的机器人操作任务中,例如微型机器人、无人机等。通过使用轻量级的动作查找表(ALT)策略,可以在保证性能的同时,显著降低计算成本和内存占用,从而实现更快的闭环控制。此外,ALT策略的OOD检测功能可以提高系统的鲁棒性,使其能够更好地应对未知的环境和任务。
📄 摘要(原文)
Diffusion policies have demonstrated remarkable dexterity and robustness in intricate, high-dimensional robot manipulation tasks, while training from a small number of demonstrations. However, the reason for this performance remains a mystery. In this paper, we offer a surprising hypothesis: diffusion policies essentially memorize an action lookup table -- and this is beneficial. We posit that, at runtime, diffusion policies find the closest training image to the test image in a latent space, and recall the associated training action sequence, offering reactivity without the need for action generalization. This is effective in the sparse data regime, where there is not enough data density for the model to learn action generalization. We support this claim with systematic empirical evidence. Even when conditioned on wildly out of distribution (OOD) images of cats and dogs, the Diffusion Policy still outputs an action sequence from the training data. With this insight, we propose a simple policy, the Action Lookup Table (ALT), as a lightweight alternative to the Diffusion Policy. Our ALT policy uses a contrastive image encoder as a hash function to index the closest corresponding training action sequence, explicitly performing the computation that the Diffusion Policy implicitly learns. We show empirically that for relatively small datasets, ALT matches the performance of a diffusion model, while requiring only 0.0034 of the inference time and 0.0085 of the memory footprint, allowing for much faster closed-loop inference with resource constrained robots. We also train our ALT policy to give an explicit OOD flag when the distance between the runtime image is too far in the latent space from the training images, giving a simple but effective runtime monitor. More information can be found at: https://stanfordmsl.github.io/alt/.