Characterizing the Robustness of Black-Box LLM Planners Under Perturbed Observations with Adaptive Stress Testing
作者: Neeloy Chakraborty, John Pohovey, Melkior Ornik, Katherine Driggs-Campbell
分类: cs.RO, cs.AI, cs.CL
发布日期: 2025-05-08 (更新: 2026-01-06)
备注: 30 pages, 24 figures, 6 tables
💡 一句话要点
提出基于自适应压力测试的MCTS方法,评估黑盒LLM规划器在扰动观测下的鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 规划器 鲁棒性 自适应压力测试 蒙特卡洛树搜索 扰动观测 安全关键系统
📋 核心要点
- 现有方法难以全面评估LLM规划器在传感器噪声和提示措辞变化下的鲁棒性,尤其是在安全关键场景中。
- 提出一种基于自适应压力测试(AST)和蒙特卡洛树搜索(MCTS)的新方法,高效搜索提示扰动空间,发现导致LLM失效的场景。
- 实验表明,该方法能够主动识别LLM在不同场景、传感器配置和提示措辞下的潜在故障,为离线分析提供支持。
📝 摘要(中文)
大型语言模型(LLMs)在规划、控制和预测等决策任务中取得了成功,但其产生不安全和不良输出的倾向带来了风险。在传感器嘈杂或不可靠的环境中,这种不良行为会进一步加剧。为了主动避免安全关键场景中的故障,有必要对LLM规划器对不同观测的响应进行表征。本文研究了LLM沿两个不同扰动维度的响应。一个维度像先前的工作一样,通过随机化细节顺序、修改少量样本的访问等方式生成具有不同措辞的语义相似提示。本文的独特之处在于,第二个维度模拟了对不同传感器和噪声的访问,以模拟原始传感器或检测算法的故障。初步的案例研究表明,这两个维度都会导致LLM在多智能体驾驶环境中产生幻觉。然而,手动覆盖多个场景的整个扰动空间是不可行的。因此,本文提出了一种新方法,利用基于蒙特卡洛树搜索(MCTS)的自适应压力测试(AST)来有效地搜索提示扰动空间。本文的AST公式能够发现导致语言模型以高度不确定性行事甚至崩溃的场景、传感器配置和提示措辞。通过生成跨不同场景的MCTS提示扰动树,本文通过广泛的实验表明,离线分析可用于主动理解运行时可能出现的潜在故障。
🔬 方法详解
问题定义:论文旨在解决黑盒大型语言模型(LLM)规划器在受到扰动观测(包括传感器噪声和提示措辞变化)时,其鲁棒性难以评估的问题。现有方法主要依赖于手动设计扰动或随机采样,无法有效覆盖整个扰动空间,难以发现导致LLM失效的极端情况,尤其是在安全关键场景下,这种失效可能造成严重后果。
核心思路:论文的核心思路是利用自适应压力测试(AST)的思想,结合蒙特卡洛树搜索(MCTS),构建一个能够智能探索提示扰动空间的框架。AST通过迭代地选择和评估扰动,逐步逼近导致LLM失效的区域。MCTS则用于指导AST的搜索过程,平衡探索和利用,从而更有效地发现关键的扰动组合。这种方法能够模拟真实世界中传感器故障和提示措辞变化带来的影响,从而更全面地评估LLM规划器的鲁棒性。
技术框架:整体框架包含以下几个主要模块:1) 环境模拟器:模拟多智能体驾驶环境,提供不同的场景和传感器配置。2) LLM规划器:作为黑盒,接收环境观测和提示,输出规划动作。3) 扰动模块:生成两种类型的扰动:传感器噪声扰动和提示措辞扰动。4) AST-MCTS搜索:利用MCTS算法,根据LLM的输出和环境反馈,选择下一个要探索的扰动组合。5) 评估模块:评估LLM在特定扰动下的表现,例如是否发生碰撞或偏离目标。
关键创新:论文的关键创新在于将AST和MCTS结合,用于搜索LLM规划器的提示扰动空间。与传统的随机采样或手动设计扰动相比,该方法能够更有效地发现导致LLM失效的极端情况。此外,论文还提出了两种类型的扰动:传感器噪声扰动和提示措辞扰动,更全面地模拟了真实世界中的不确定性。
关键设计:MCTS算法中的奖励函数设计至关重要,它直接影响搜索的效率和结果。论文中奖励函数的设计需要考虑LLM的输出置信度、规划动作的安全性以及是否达到目标。此外,扰动模块的设计也需要仔细考虑,例如传感器噪声的分布类型和强度,以及提示措辞变化的范围和方式。
🖼️ 关键图片
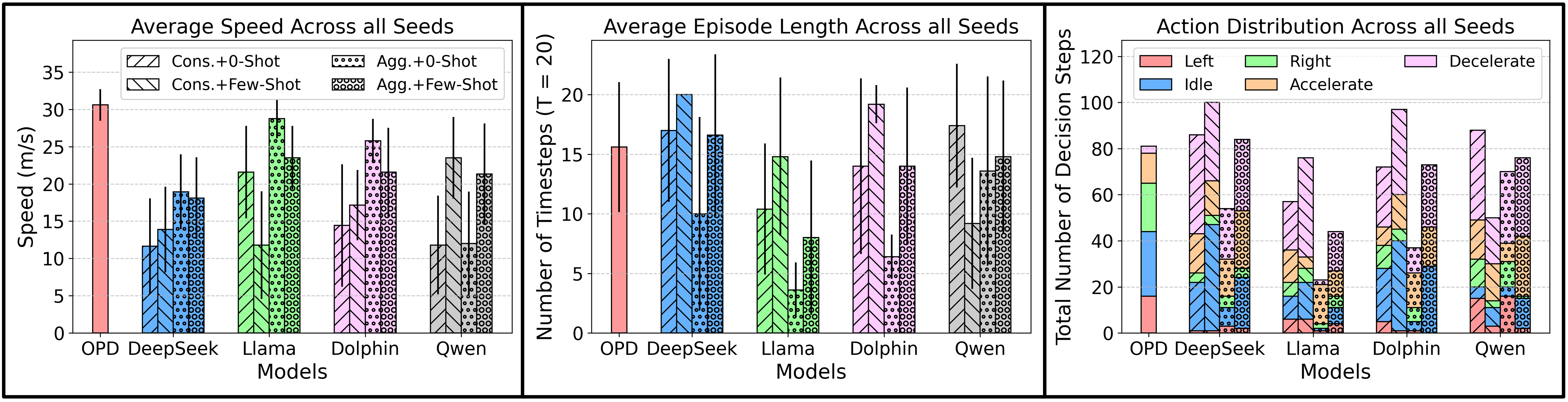

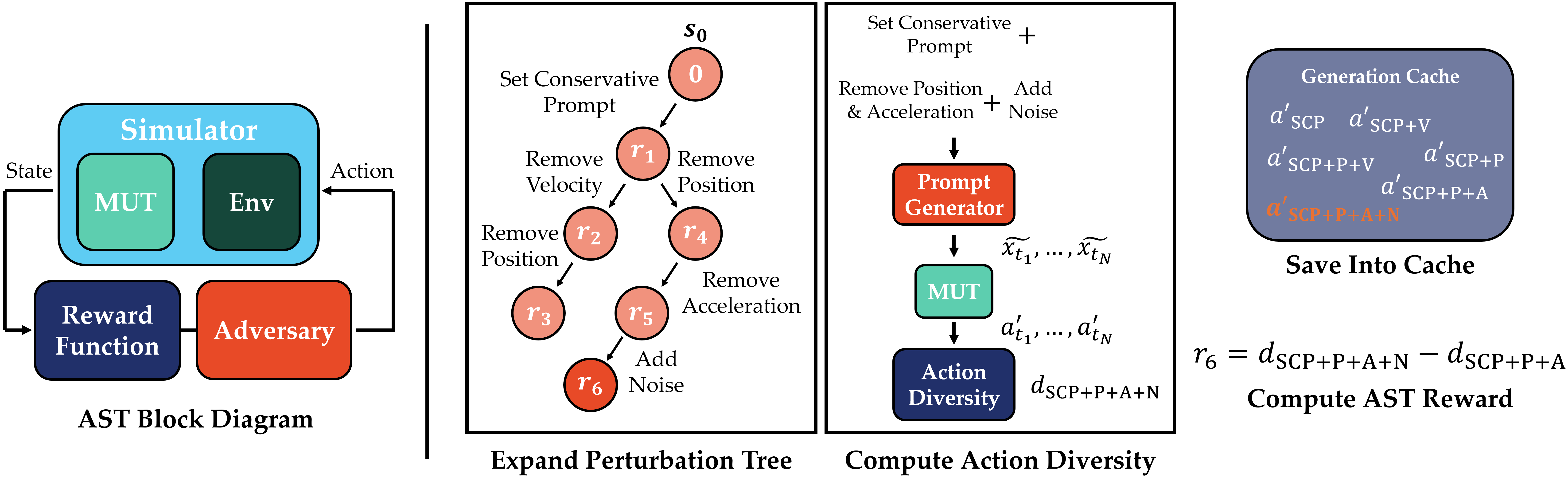
📊 实验亮点
实验结果表明,该方法能够有效地发现导致LLM规划器失效的场景和扰动组合。通过对比不同搜索策略,证明了AST-MCTS方法的优越性。此外,实验还揭示了LLM在特定传感器配置和提示措辞下容易出现幻觉和不安全行为,为改进LLM的设计提供了重要的参考依据。具体性能数据未知,但强调了该方法在发现潜在故障方面的有效性。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航等安全关键领域,帮助开发者在部署LLM规划器之前,主动发现潜在的故障模式,提高系统的安全性和可靠性。通过离线分析,可以针对性地改进LLM的提示设计和训练数据,从而提升其在复杂和不确定环境下的鲁棒性。未来,该方法还可以扩展到其他类型的LLM应用和扰动类型。
📄 摘要(原文)
Large language models (LLMs) have recently demonstrated success in decision-making tasks including planning, control, and prediction, but their tendency to hallucinate unsafe and undesired outputs poses risks. This unwanted behavior is further exacerbated in environments where sensors are noisy or unreliable. Characterizing the behavior of LLM planners to varied observations is necessary to proactively avoid failures in safety-critical scenarios. We specifically investigate the response of LLMs along two different perturbation dimensions. Like prior works, one dimension generates semantically similar prompts with varied phrasing by randomizing order of details, modifying access to few-shot examples, etc. Unique to our work, the second dimension simulates access to varied sensors and noise to mimic raw sensor or detection algorithm failures. An initial case study in which perturbations are manually applied show that both dimensions lead LLMs to hallucinate in a multi-agent driving environment. However, manually covering the entire perturbation space for several scenarios is infeasible. As such, we propose a novel method for efficiently searching the space of prompt perturbations using adaptive stress testing (AST) with Monte-Carlo tree search (MCTS). Our AST formulation enables discovery of scenarios, sensor configurations, and prompt phrasing that cause language models to act with high uncertainty or even crash. By generating MCTS prompt perturbation trees across diverse scenarios, we show through extensive experiments that offline analyses can be used to proactively understand potential failures that may arise at runtime.