Learning to Drive Anywhere with Model-Based Reannotation
作者: Noriaki Hirose, Lydia Ignatova, Kyle Stachowicz, Catherine Glossop, Sergey Levine, Dhruv Shah
分类: cs.RO, cs.CV, cs.LG, eess.SY
发布日期: 2025-05-08 (更新: 2025-11-21)
备注: 9 pages, 8 figures, 6 tables
期刊: IEEE Robotics and Automation Letters 2025
💡 一句话要点
提出基于模型重标注的MBRA框架,提升机器人泛化导航能力。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 机器人导航 模型重标注 泛化能力 长时程导航 模仿学习
📋 核心要点
- 现有机器人导航策略受限于高质量训练数据的规模,难以实现广泛的泛化能力。
- MBRA框架利用模型预测为大规模低质量数据重标注,生成高质量的训练数据。
- 实验表明,基于MBRA训练的LogoNav在真实环境中实现了优异的导航性能。
📝 摘要(中文)
为解决机器人视觉导航策略泛化性难题,受限于大规模多样化训练数据的匮乏,本文提出了一种基于模型重标注(MBRA)的框架。该框架利用学习到的短时程、基于模型的专家模型,为海量的众包遥操作数据和未标注的YouTube视频等被动收集的数据重新标注或生成高质量的动作标签。然后,将这些重新标注的数据提炼到LogoNav中,这是一个以视觉目标或GPS航点为条件的长时程导航策略。实验结果表明,使用MBRA处理的数据训练的LogoNav实现了最先进的性能,能够在以前未见过的室内和室外环境中实现超过300米的稳健导航。在六个城市、三大洲的机器人(包括四足机器人)上进行的广泛真实世界评估,验证了该策略的泛化能力,即使在拥挤环境中也能有效地导航。
🔬 方法详解
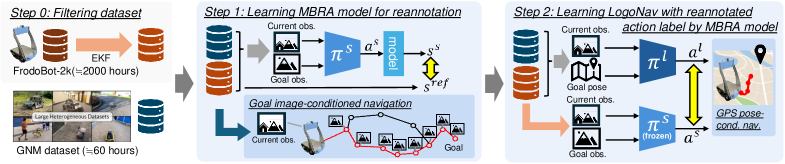
问题定义:论文旨在解决机器人视觉导航策略在真实世界中的泛化性问题。现有方法依赖于人工标注的高质量数据集,但这些数据集的规模有限,难以覆盖真实世界中各种复杂的场景和环境,导致导航策略在未见过的环境中表现不佳。此外,大量存在的众包遥操作数据和未标注视频数据虽然蕴含丰富的信息,但由于质量参差不齐或缺乏动作标签,难以直接用于训练。
核心思路:论文的核心思路是利用一个学习到的短时程、基于模型的专家模型,对大规模的低质量或未标注数据进行重标注,从而生成高质量的训练数据。通过这种方式,可以充分利用海量数据,提高导航策略的泛化能力。重标注后的数据被用于训练一个长时程导航策略,使其能够根据视觉目标或GPS航点进行导航。
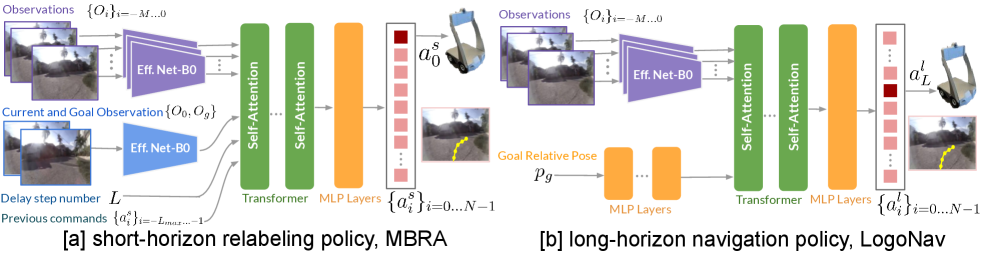
技术框架:MBRA框架包含以下几个主要模块:1) 短时程模型学习模块:学习一个能够预测未来状态和奖励的短时程模型。2) 数据重标注模块:利用学习到的短时程模型,为低质量或未标注数据生成高质量的动作标签。具体而言,对于每个状态,模型预测多个可能的动作序列,并选择能够最大化累积奖励的动作序列作为重标注的动作。3) 长时程导航策略学习模块:使用重标注后的数据训练一个长时程导航策略(LogoNav),该策略以视觉目标或GPS航点为输入,输出导航动作。
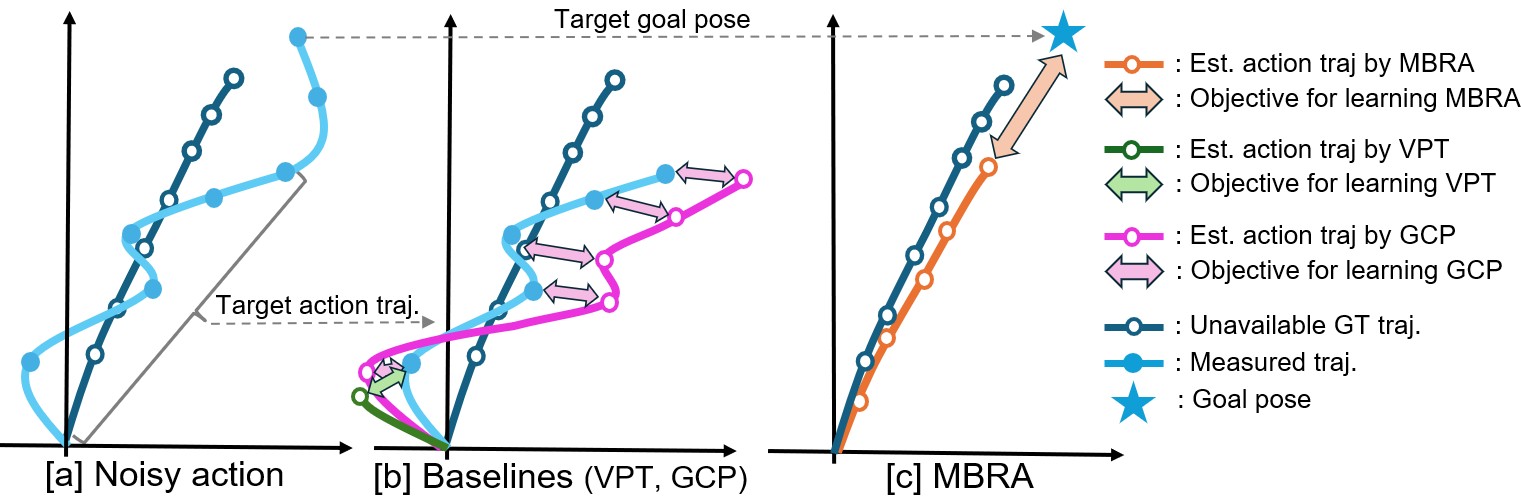
关键创新:论文的关键创新在于提出了基于模型重标注(MBRA)的框架,该框架能够有效地利用大规模的低质量或未标注数据来提高机器人导航策略的泛化能力。与传统的监督学习方法相比,MBRA不需要人工标注大量数据,降低了数据收集和标注的成本。与直接使用低质量数据训练相比,MBRA通过模型预测生成高质量的动作标签,提高了训练数据的质量。
关键设计:短时程模型采用循环神经网络(RNN)结构,以历史状态和动作作为输入,预测未来的状态和奖励。奖励函数的设计至关重要,需要能够反映导航任务的目标,例如,接近目标位置、避免碰撞等。长时程导航策略(LogoNav)采用分层结构,包含一个高层规划器和一个低层控制器。高层规划器根据视觉目标或GPS航点生成一系列中间目标,低层控制器根据中间目标生成具体的导航动作。损失函数包括模仿学习损失和强化学习损失,以提高导航策略的鲁棒性和泛化能力。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用MBRA处理的数据训练的LogoNav在真实世界环境中实现了最先进的导航性能,能够在以前未见过的室内和室外环境中实现超过300米的稳健导航。在六个城市、三大洲的机器人(包括四足机器人)上进行的广泛真实世界评估,验证了该策略的泛化能力,即使在拥挤环境中也能有效地导航。
🎯 应用场景
该研究成果可广泛应用于自动驾驶、机器人导航等领域。例如,可以利用该方法训练出能够在复杂城市环境中安全行驶的自动驾驶汽车,或者训练出能够在仓库、工厂等环境中高效搬运货物的机器人。此外,该方法还可以应用于虚拟现实、游戏等领域,提高虚拟角色的智能性和交互性。
📄 摘要(原文)
Developing broadly generalizable visual navigation policies for robots is a significant challenge, primarily constrained by the availability of large-scale, diverse training data. While curated datasets collected by researchers offer high quality, their limited size restricts policy generalization. To overcome this, we explore leveraging abundant, passively collected data sources, including large volumes of crowd-sourced teleoperation data and unlabeled YouTube videos, despite their potential for lower quality or missing action labels. We propose Model-Based ReAnnotation (MBRA), a framework that utilizes a learned short-horizon, model-based expert model to relabel or generate high-quality actions for these passive datasets. This relabeled data is then distilled into LogoNav, a long-horizon navigation policy conditioned on visual goals or GPS waypoints. We demonstrate that LogoNav, trained using MBRA-processed data, achieves state-of-the-art performance, enabling robust navigation over distances exceeding 300 meters in previously unseen indoor and outdoor environments. Our extensive real-world evaluations, conducted across a fleet of robots (including quadrupeds) in six cities on three continents, validate the policy's ability to generalize and navigate effectively even amidst pedestrians in crowded settings.