Steerable Scene Generation with Post Training and Inference-Time Search
作者: Nicholas Pfaff, Hongkai Dai, Sergey Zakharov, Shun Iwase, Russ Tedrake
分类: cs.RO, cs.GR, cs.LG
发布日期: 2025-05-07 (更新: 2025-08-26)
备注: Project website: https://steerable-scene-generation.github.io/
💡 一句话要点
提出基于扩散模型的场景生成方法,通过后训练和推理时搜索实现可控场景生成。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 场景生成 扩散模型 机器人仿真 推理时搜索 蒙特卡洛树搜索 物理可行性 SE(3)姿势
📋 核心要点
- 机器人仿真训练需要多样化的3D场景,但人工创建满足严格任务要求的场景成本高昂且稀少。
- 本文提出一种基于扩散模型的场景生成方法,通过后训练、条件生成和推理时搜索来引导场景生成。
- 该方法通过MCTS搜索策略和物理可行性约束,实现了目标导向的场景合成,并发布了包含4400万场景的数据集。
📝 摘要(中文)
本文提出了一种利用程序化模型生成大规模场景数据,并将其适配到特定任务目标的方法,用于在模拟环境中训练机器人。该方法训练了一个统一的基于扩散的生成模型,用于预测从固定资源库中放置哪些对象及其SE(3)姿势。该模型作为一个灵活的场景先验,可以通过基于强化学习的后训练、条件生成或推理时搜索进行调整,从而将生成过程引导至下游目标,即使这些目标与原始数据分布不同。本文方法实现了尊重物理可行性的目标导向场景合成,并可跨场景类型进行扩展。此外,本文还提出了一种新颖的基于MCTS的扩散模型推理时搜索策略,通过投影和模拟来强制执行可行性,并发布了一个包含超过4400万个SE(3)场景的数据集,涵盖五个不同的环境。网站包含视频、代码、数据和模型权重。
🔬 方法详解
问题定义:论文旨在解决机器人仿真训练中,难以获取满足特定任务需求(例如高杂乱度、合理的空间排列)的3D场景的问题。现有方法依赖于手动创建或简单的程序化生成,前者成本高昂,后者难以保证场景的真实性和多样性。
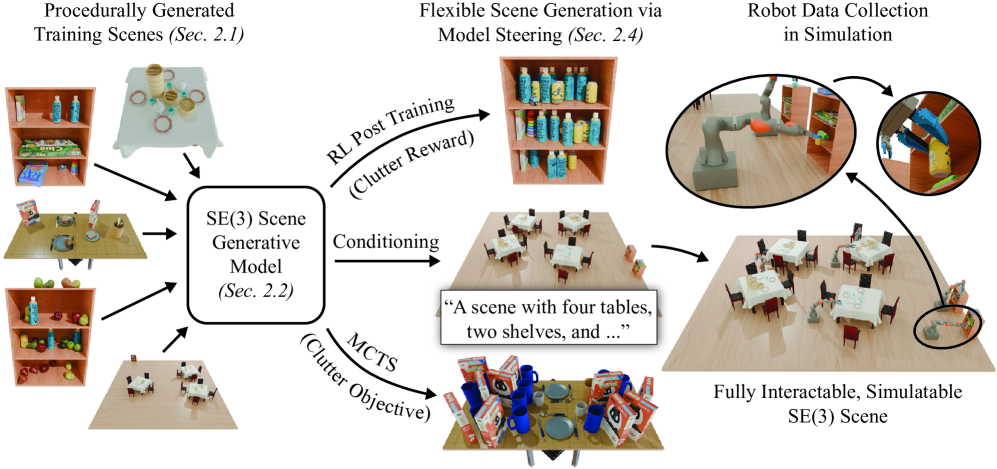
核心思路:论文的核心思路是利用扩散模型学习一个通用的场景先验,然后通过后训练、条件生成或推理时搜索等方式,将该先验知识引导到特定的任务目标。这样既可以利用程序化生成的大规模数据,又可以保证生成场景的质量和任务相关性。
技术框架:整体框架包含以下几个主要阶段:1) 使用程序化模型生成大规模的场景数据集,包含物体及其SE(3)姿势;2) 训练一个基于扩散模型的生成模型,该模型以场景描述作为输入,预测场景中物体的类别和姿势;3) 使用强化学习进行后训练,或者使用条件生成来调整生成模型的输出,使其更符合特定的任务目标;4) 在推理时,使用基于MCTS的搜索策略,在扩散模型的输出空间中搜索最优的场景配置。
关键创新:论文的关键创新在于:1) 提出了一种基于扩散模型的场景生成方法,能够生成高质量、多样化的3D场景;2) 提出了一种基于MCTS的推理时搜索策略,能够在扩散模型的输出空间中搜索最优的场景配置;3) 结合了后训练、条件生成和推理时搜索等多种方法,实现了对场景生成过程的精细控制。与现有方法相比,该方法能够更好地满足特定任务的需求。
关键设计:扩散模型采用U-Net结构,输入为场景描述(例如物体类别、姿势),输出为噪声预测。损失函数为标准的扩散模型损失函数,即预测噪声与真实噪声之间的均方误差。MCTS搜索策略使用扩散模型的输出作为状态,使用模拟器评估场景的物理可行性,并使用奖励函数来衡量场景与任务目标的匹配程度。后训练阶段使用强化学习算法(例如PPO)来优化生成模型的参数,使其能够生成更符合任务目标的场景。
🖼️ 关键图片


📊 实验亮点
论文发布了一个包含超过4400万个SE(3)场景的数据集,涵盖五个不同的环境。实验结果表明,该方法能够生成高质量、多样化的3D场景,并且可以通过后训练和推理时搜索等方式,将生成过程引导到特定的任务目标。与现有方法相比,该方法能够更好地满足特定任务的需求,例如在高杂乱度环境中进行物体抓取。
🎯 应用场景
该研究成果可广泛应用于机器人仿真训练、自动驾驶场景生成、游戏场景设计等领域。通过生成大量高质量、任务相关的3D场景,可以有效提高机器人和自动驾驶系统的性能和鲁棒性,降低开发成本。此外,该方法还可以用于生成各种虚拟环境,为游戏开发和虚拟现实应用提供丰富的素材。
📄 摘要(原文)
Training robots in simulation requires diverse 3D scenes that reflect the specific challenges of downstream tasks. However, scenes that satisfy strict task requirements, such as high-clutter environments with plausible spatial arrangement, are rare and costly to curate manually. Instead, we generate large-scale scene data using procedural models that approximate realistic environments for robotic manipulation, and adapt it to task-specific goals. We do this by training a unified diffusion-based generative model that predicts which objects to place from a fixed asset library, along with their SE(3) poses. This model serves as a flexible scene prior that can be adapted using reinforcement learning-based post training, conditional generation, or inference-time search, steering generation toward downstream objectives even when they differ from the original data distribution. Our method enables goal-directed scene synthesis that respects physical feasibility and scales across scene types. We introduce a novel MCTS-based inference-time search strategy for diffusion models, enforce feasibility via projection and simulation, and release a dataset of over 44 million SE(3) scenes spanning five diverse environments. Website with videos, code, data, and model weights: https://steerable-scene-generation.github.io/