AMO: Adaptive Motion Optimization for Hyper-Dexterous Humanoid Whole-Body Control
作者: Jialong Li, Xuxin Cheng, Tianshu Huang, Shiqi Yang, Ri-Zhao Qiu, Xiaolong Wang
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-05-06
备注: website: https://amo-humanoid.github.io
💡 一句话要点
提出自适应运动优化(AMO)框架,用于超灵巧人形机器人全身控制。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人形机器人 全身控制 强化学习 轨迹优化 Sim-to-Real 自适应控制 运动规划 机器人操作
📋 核心要点
- 人形机器人全身运动控制面临高自由度和非线性动力学挑战,现有方法难以实现超灵巧运动。
- AMO框架融合强化学习和轨迹优化,通过混合数据集训练网络,实现对新命令的自适应控制。
- 实验表明,AMO在稳定性和工作空间方面优于现有方法,并支持自主任务执行。
📝 摘要(中文)
本文提出自适应运动优化(AMO)框架,该框架结合了sim-to-real强化学习(RL)与轨迹优化,用于实时、自适应的全身控制。为了缓解运动模仿强化学习中的分布偏差,构建了一个混合AMO数据集,并训练了一个网络,该网络能够对潜在的O.O.D.命令进行鲁棒的、按需的自适应。在仿真和29自由度宇树G1人形机器人上验证了AMO,与强大的基线相比,AMO表现出卓越的稳定性和更大的工作空间。最后,证明了AMO的一致性能支持通过模仿学习进行自主任务执行,突出了系统的通用性和鲁棒性。
🔬 方法详解
问题定义:人形机器人全身控制,尤其是在需要大工作空间的任务中(例如从地面拾取物体),面临着高自由度、非线性动力学以及实际机器人与仿真环境差异带来的挑战。现有的方法往往难以在真实机器人上实现稳定、鲁棒的超灵巧运动。
核心思路:AMO的核心思路是将强化学习的泛化能力与轨迹优化的精确控制相结合。通过强化学习训练一个能够适应不同命令的策略,然后利用轨迹优化对策略生成的运动轨迹进行精细调整,从而提高运动的稳定性和准确性。同时,使用混合数据集来缓解sim-to-real的分布偏差。
技术框架:AMO框架主要包含以下几个模块:1) 混合数据集构建:结合仿真数据和真实数据,构建一个包含各种运动命令和环境条件的混合数据集。2) 强化学习策略训练:使用混合数据集训练一个强化学习策略,该策略能够根据输入的命令生成相应的运动轨迹。3) 轨迹优化:利用轨迹优化算法对强化学习策略生成的运动轨迹进行优化,以提高运动的稳定性和准确性。4) 自适应控制:根据机器人的状态和环境条件,对运动轨迹进行实时调整,以实现自适应控制。
关键创新:AMO的关键创新在于将强化学习和轨迹优化相结合,并使用混合数据集来缓解sim-to-real的分布偏差。这种方法既能利用强化学习的泛化能力,又能利用轨迹优化的精确控制,从而在真实机器人上实现稳定、鲁棒的超灵巧运动。此外,按需适应O.O.D命令的能力也是一个重要的创新点。
关键设计:混合数据集包含仿真数据和真实数据,其中仿真数据用于提供大量的训练样本,真实数据用于减小sim-to-real的分布偏差。强化学习策略采用Actor-Critic结构,Actor网络用于生成运动轨迹,Critic网络用于评估运动轨迹的质量。轨迹优化采用iLQR算法,损失函数包括位置误差、速度误差和力矩误差。网络结构和超参数的选择需要根据具体的机器人平台和任务进行调整。
🖼️ 关键图片
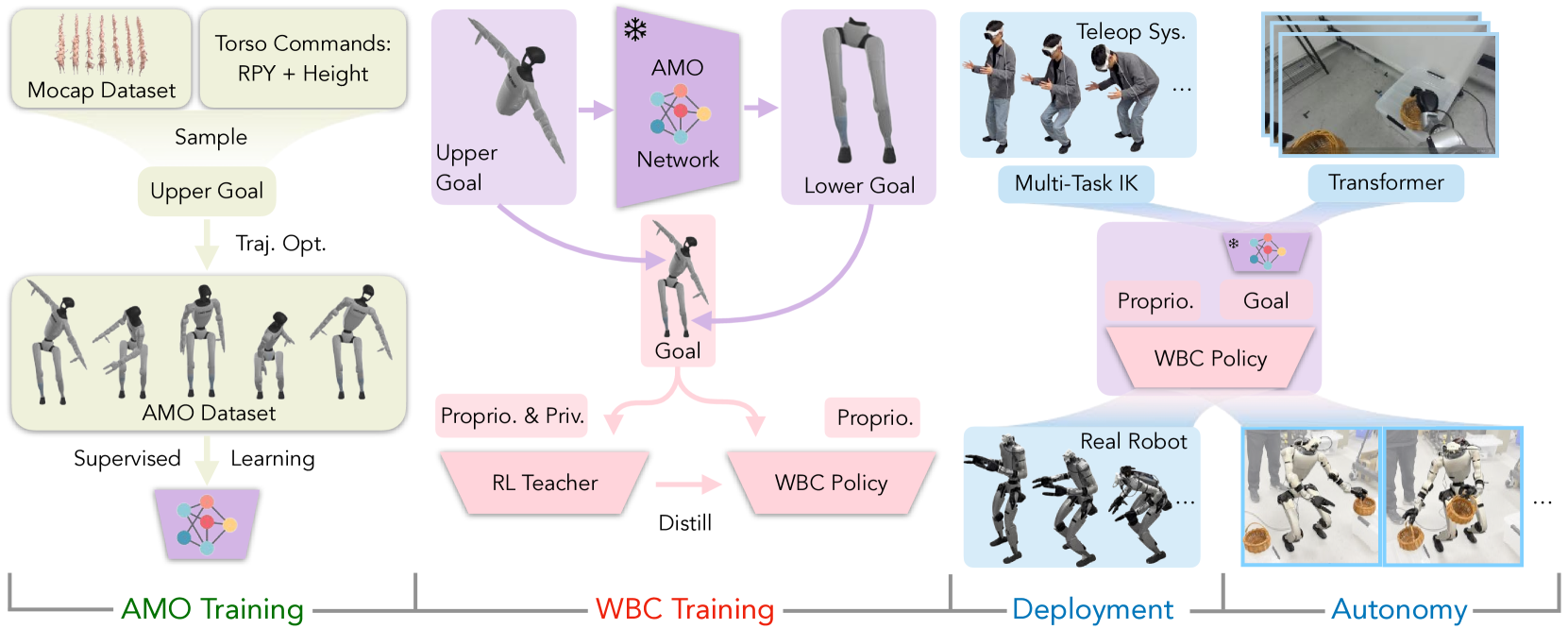
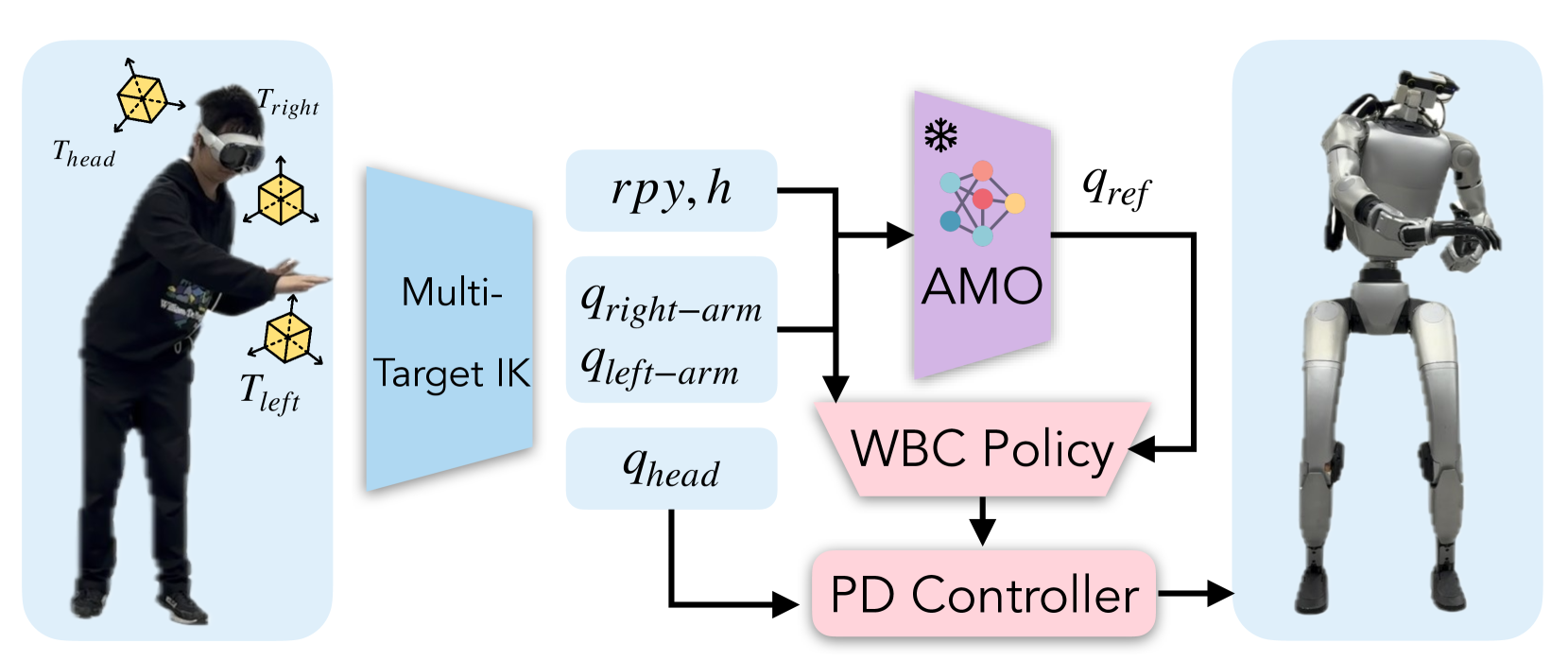

📊 实验亮点
在29自由度宇树G1人形机器人上的实验表明,AMO在稳定性和工作空间方面优于现有的方法。与基线方法相比,AMO能够实现更稳定的运动,并且能够到达更大的工作空间。此外,实验还证明了AMO能够支持通过模仿学习进行自主任务执行,表明了AMO的通用性和鲁棒性。
🎯 应用场景
该研究成果可应用于人形机器人在复杂环境中的操作任务,如搜救、物流、医疗等。通过提升机器人的运动灵活性和适应性,使其能够在非结构化环境中完成各种精细操作,具有重要的实际应用价值和广阔的应用前景。未来,该技术有望进一步推广到其他类型的机器人,例如四足机器人和机械臂。
📄 摘要(原文)
Humanoid robots derive much of their dexterity from hyper-dexterous whole-body movements, enabling tasks that require a large operational workspace: such as picking objects off the ground. However, achieving these capabilities on real humanoids remains challenging due to their high degrees of freedom (DoF) and nonlinear dynamics. We propose Adaptive Motion Optimization (AMO), a framework that integrates sim-to-real reinforcement learning (RL) with trajectory optimization for real-time, adaptive whole-body control. To mitigate distribution bias in motion imitation RL, we construct a hybrid AMO dataset and train a network capable of robust, on-demand adaptation to potentially O.O.D. commands. We validate AMO in simulation and on a 29-DoF Unitree G1 humanoid robot, demonstrating superior stability and an expanded workspace compared to strong baselines. Finally, we show that AMO's consistent performance supports autonomous task execution via imitation learning, underscoring the system's versatility and robustness.