Visual Imitation Enables Contextual Humanoid Control
作者: Arthur Allshire, Hongsuk Choi, Junyi Zhang, David McAllister, Anthony Zhang, Chung Min Kim, Trevor Darrell, Pieter Abbeel, Jitendra Malik, Angjoo Kanazawa
分类: cs.RO, cs.CV
发布日期: 2025-05-06 (更新: 2025-08-29)
备注: Project website: https://www.videomimic.net/
💡 一句话要点
VIDEOMIMIC:通过视觉模仿实现人型机器人的环境感知控制
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 视觉模仿学习 人型机器人 环境感知 全身控制 强化学习
📋 核心要点
- 现有方法难以让人型机器人利用环境上下文信息,执行复杂操作,例如上下楼梯、坐立等。
- VIDEOMIMIC通过从视频中联合重建人类和环境,学习全身控制策略,实现环境感知的机器人控制。
- 实验表明,该方法在真实机器人上实现了稳健的楼梯上下、坐立等复杂动作,展示了其有效性。
📝 摘要(中文)
本文提出了一种名为VIDEOMIMIC的real-to-sim-to-real流程,旨在利用周围环境的上下文信息,教会人型机器人执行诸如爬楼梯、坐在椅子上等任务。该流程从日常视频中挖掘数据,联合重建人类和环境,并生成全身控制策略,使人型机器人能够执行相应的技能。实验结果表明,该流程可以在真实的人型机器人上实现稳健、可重复的上下文控制,例如楼梯的上下、从椅子和长凳上的坐立,以及其他动态的全身技能——所有这些都来自一个单一的策略,该策略以环境和全局根命令为条件。VIDEOMIMIC为扩展人型机器人在各种真实世界环境中操作提供了一条可扩展的路径。
🔬 方法详解
问题定义:论文旨在解决如何让人型机器人能够像人类一样,利用视觉信息理解周围环境,并在此基础上执行复杂的全身运动控制任务,例如上下楼梯、坐在椅子上等。现有方法通常需要手动设计复杂的控制策略,或者依赖于大量的机器人数据进行训练,泛化性较差,难以适应真实世界中复杂多变的环境。
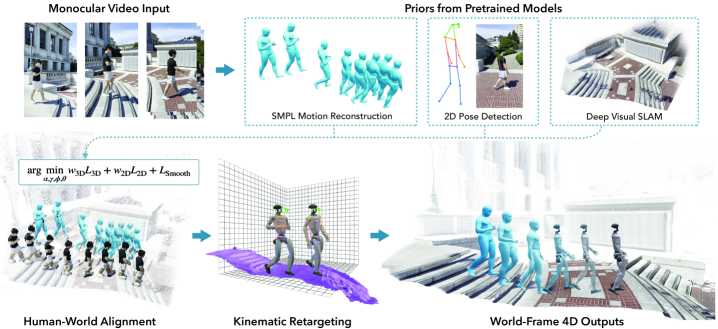
核心思路:论文的核心思路是通过视觉模仿学习,从人类的日常视频中学习控制策略。具体来说,首先从视频中重建人类的运动和周围环境的三维模型,然后利用这些信息训练一个控制策略,使机器人能够模仿人类的运动,并适应周围的环境。这种方法的优势在于可以利用大量的、易于获取的人类视频数据,避免了手动设计控制策略的复杂性,并提高了机器人的泛化能力。
技术框架:VIDEOMIMIC的整体框架是一个real-to-sim-to-real的流程。首先,从真实世界的视频中提取人类的运动和环境信息,并重建三维模型。然后,将这些三维模型导入到仿真环境中,训练一个控制策略。最后,将训练好的控制策略部署到真实的机器人上。该框架主要包含以下几个模块:1) 视频数据采集与处理模块;2) 人类运动和环境重建模块;3) 仿真环境搭建模块;4) 控制策略训练模块;5) 机器人部署模块。
关键创新:该论文的关键创新在于提出了一种基于视觉模仿学习的上下文感知机器人控制方法。与传统的机器人控制方法相比,该方法可以直接从人类的视频数据中学习控制策略,无需手动设计复杂的控制规则。此外,该方法还能够利用周围环境的信息,使机器人能够更好地适应真实世界中的复杂环境。
关键设计:在人类运动和环境重建模块中,论文采用了一种基于深度学习的三维重建方法,可以从单目视频中重建出人类的运动和周围环境的三维模型。在控制策略训练模块中,论文采用了一种强化学习算法,以机器人的运动轨迹与人类运动轨迹之间的差异作为奖励函数,训练一个能够模仿人类运动的控制策略。此外,论文还设计了一种环境编码器,用于将周围环境的信息编码成一个向量,作为控制策略的输入。
🖼️ 关键图片


📊 实验亮点
实验结果表明,VIDEOMIMIC可以在真实的人型机器人上实现稳健、可重复的上下文控制,例如楼梯的上下、从椅子和长凳上的坐立。该方法仅使用一个单一的策略,并以环境和全局根命令为条件,即可完成多种不同的任务。相较于传统方法,VIDEOMIMIC具有更强的泛化能力和适应性。
🎯 应用场景
该研究成果可应用于各种需要人型机器人与环境交互的场景,例如家庭服务、医疗辅助、工业自动化等。通过模仿人类在真实环境中的行为,机器人可以更好地理解和适应周围环境,从而完成更加复杂的任务。未来,该技术有望推动人型机器人在真实世界中的广泛应用。
📄 摘要(原文)
How can we teach humanoids to climb staircases and sit on chairs using the surrounding environment context? Arguably, the simplest way is to just show them-casually capture a human motion video and feed it to humanoids. We introduce VIDEOMIMIC, a real-to-sim-to-real pipeline that mines everyday videos, jointly reconstructs the humans and the environment, and produces whole-body control policies for humanoid robots that perform the corresponding skills. We demonstrate the results of our pipeline on real humanoid robots, showing robust, repeatable contextual control such as staircase ascents and descents, sitting and standing from chairs and benches, as well as other dynamic whole-body skills-all from a single policy, conditioned on the environment and global root commands. VIDEOMIMIC offers a scalable path towards teaching humanoids to operate in diverse real-world environments.