Close-Fitting Dressing Assistance Based on State Estimation of Feet and Garments with Semantic-based Visual Attention
作者: Takuma Tsukakoshi, Tamon Miyake, Tetsuya Ogata, Yushi Wang, Takumi Akaishi, Shigeki Sugano
分类: cs.RO
发布日期: 2025-05-06 (更新: 2026-01-26)
备注: Accepted at RA-L, 2026
💡 一句话要点
提出基于语义视觉注意的足部和衣物状态估计方法,辅助机器人完成贴身衣物穿戴
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting)
关键词: 机器人辅助 穿戴辅助 多模态融合 语义分割 状态估计 视觉注意力 深度学习
📋 核心要点
- 贴身衣物穿戴需要精细的力调整,以应对摩擦和阻碍,同时考虑衣物的形状和位置,对机器人辅助穿戴构成挑战。
- 该方法融合多模态信息,并引入基于语义信息的视觉注意力机制,以提升对未见过的足部和背景的泛化能力。
- 实验表明,该方法在人类受试者身上成功穿袜,且成功率高于现有方法,验证了其在贴身衣物穿戴辅助方面的有效性。
📝 摘要(中文)
本文提出了一种辅助机器人穿戴贴身衣物的方法,旨在解决老龄化社会护理人员短缺的问题。该方法利用多模态信息,包括机器人的相机图像、关节角度、关节扭矩以及触觉力,以实现适当的力交互,从而适应个体差异。通过引入基于对象概念的语义信息,而非仅依赖RGB数据,该方法可以泛化到未见过的足部和背景。此外,结合深度数据有助于推断袜子和足部之间的相对空间关系。为了验证语义对象概念化的能力并确保安全性,使用人体模型收集训练数据,并在人类受试者身上进行后续实验。实验结果表明,该模型能够适应以前未见过的人类足部,并成功地为10名参与者穿上袜子,成功率高于Action Chunking with Transformer和Diffusion Policy。这些结果表明,所提出的模型可以估计衣物和足部的状态,从而实现精确的贴身衣物穿戴辅助。
🔬 方法详解
问题定义:论文旨在解决机器人辅助穿戴贴身衣物,特别是袜子时,由于个体差异、衣物形变和环境变化带来的挑战。现有方法通常依赖于精确的视觉信息或预编程的动作序列,难以适应未见过的足部形状和背景,并且缺乏对力反馈的有效利用,容易造成不适或损伤。
核心思路:论文的核心思路是利用多模态信息融合和基于语义的视觉注意力机制,提升机器人对足部和衣物状态的估计能力,从而实现更安全、更有效的穿戴辅助。通过引入语义信息,模型可以更好地理解场景,并泛化到新的足部和背景。
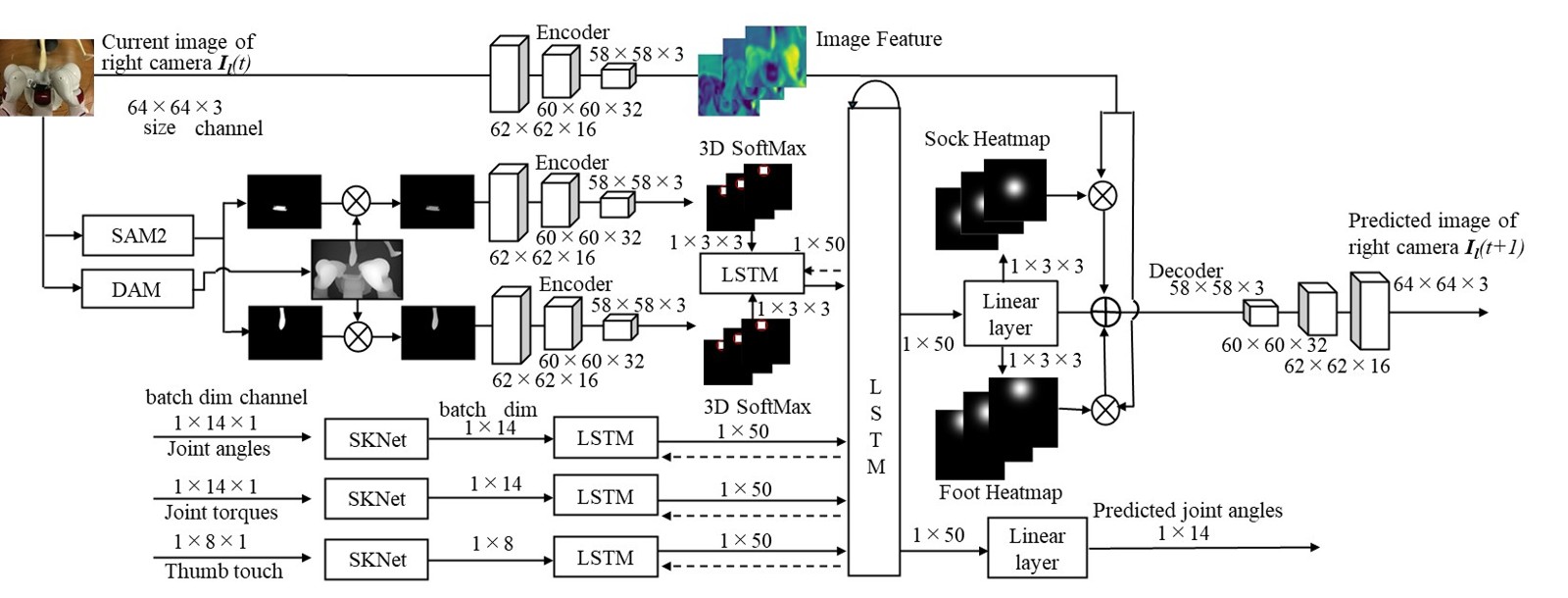
技术框架:该方法的技术框架包含以下几个主要模块:1) 多模态数据采集模块,负责收集机器人的相机图像、关节角度、关节扭矩和触觉力等信息;2) 语义分割模块,利用深度学习模型对图像进行语义分割,提取足部和衣物的语义信息;3) 状态估计模块,融合多模态数据和语义信息,估计足部和衣物的状态,包括位置、姿态和形变;4) 动作规划与控制模块,根据状态估计结果,规划机器人的动作,并控制机器人执行穿戴动作。
关键创新:该论文的关键创新在于:1) 引入了基于语义信息的视觉注意力机制,提升了模型对未见过的足部和背景的泛化能力;2) 融合了多模态信息,包括视觉、触觉和力觉信息,提高了状态估计的准确性和鲁棒性;3) 提出了一种适应个体差异的力交互方法,降低了穿戴过程中的不适感和损伤风险。
关键设计:在语义分割模块中,使用了预训练的深度学习模型,并针对足部和衣物进行了微调。在状态估计模块中,使用了卡尔曼滤波器等方法,融合多模态数据。在动作规划与控制模块中,使用了基于力反馈的阻抗控制方法,以实现更柔顺的力交互。具体的损失函数和网络结构等技术细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法能够成功地为10名参与者穿上袜子,成功率高于Action Chunking with Transformer和Diffusion Policy。这表明该方法在贴身衣物穿戴辅助方面具有显著的优势,能够适应不同个体差异,并实现更安全、更有效的穿戴过程。具体的成功率数据和提升幅度在摘要中未给出,属于未知信息。
🎯 应用场景
该研究成果可应用于养老院、医院和家庭等场景,为行动不便的老年人或残疾人提供穿衣辅助,提高他们的生活质量和独立性。此外,该技术还可以扩展到其他需要精细操作的机器人辅助任务,例如康复训练、医疗手术等,具有广阔的应用前景。
📄 摘要(原文)
As the population continues to age, a shortage of caregivers is expected in the future. Dressing assistance, in particular, is crucial for opportunities for social participation. Especially dressing close-fitting garments, such as socks, remains challenging due to the need for fine force adjustments to handle the friction or snagging against the skin, while considering the shape and position of the garment. This study introduces a method uses multi-modal information including not only robot's camera images, joint angles, joint torques, but also tactile forces for proper force interaction that can adapt to individual differences in humans. Furthermore, by introducing semantic information based on object concepts, rather than relying solely on RGB data, it can be generalized to unseen feet and background. In addition, incorporating depth data helps infer relative spatial relationship between the sock and the foot. To validate its capability for semantic object conceptualization and to ensure safety, training data were collected using a mannequin, and subsequent experiments were conducted with human subjects. In experiments, the robot successfully adapted to previously unseen human feet and was able to put socks on 10 participants, achieving a higher success rate than Action Chunking with Transformer and Diffusion Policy. These results demonstrate that the proposed model can estimate the state of both the garment and the foot, enabling precise dressing assistance for close-fitting garments.