The Unreasonable Effectiveness of Discrete-Time Gaussian Process Mixtures for Robot Policy Learning
作者: Jan Ole von Hartz, Adrian Röfer, Joschka Boedecker, Abhinav Valada
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-05-06
备注: Submitted for publication to IEEE Transaction on Robotics
💡 一句话要点
提出MiDiGap,一种基于离散时间高斯过程混合模型的机器人策略学习方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人策略学习 模仿学习 高斯过程混合模型 小样本学习 机器人操作 跨机器人迁移 离散时间模型
📋 核心要点
- 现有机器人策略学习方法在处理复杂操作任务时,面临样本效率低、泛化能力差等问题,尤其是在小样本学习场景下。
- MiDiGap的核心思想是利用离散时间高斯过程混合模型,对机器人策略进行灵活表示,从而实现高效的模仿学习和泛化。
- 实验表明,MiDiGap在多种机器人操作任务上取得了显著的性能提升,尤其是在小样本学习和跨机器人迁移方面。
📝 摘要(中文)
本文提出了一种名为离散时间高斯过程混合模型(MiDiGap)的新方法,用于机器人操作中的灵活策略表示和模仿学习。MiDiGap仅使用摄像头观测,就能从少至五个的演示中进行学习,并能推广到各种具有挑战性的任务中。它擅长于长时程行为(如制作咖啡)、高度约束的运动(如开门)、动态动作(如用铲子舀东西)以及多模态任务(如挂马克杯)。MiDiGap在CPU上不到一分钟即可学习这些任务,并可线性扩展到大型数据集。我们还开发了一套丰富的工具,用于使用碰撞信号和机器人运动学约束等证据进行推理时引导。这种引导实现了新的泛化能力,包括避障和跨机器人策略迁移。MiDiGap在各种小样本操作基准测试中实现了最先进的性能。在受约束的RLBench任务中,它将策略成功率提高了76个百分点,并将轨迹成本降低了67%。在多模态任务中,它将策略成功率提高了48个百分点,并将样本效率提高了20倍。在跨机器人迁移中,它使策略成功率提高了一倍以上。代码已公开。
🔬 方法详解
问题定义:现有机器人策略学习方法,尤其是在模仿学习领域,通常需要大量的训练数据才能获得较好的性能。在复杂的操作任务中,例如需要长时程规划、精确控制或处理多模态行为的任务,现有方法的样本效率较低,泛化能力也较差。此外,如何利用先验知识(如碰撞信号、运动学约束)来引导策略学习也是一个挑战。
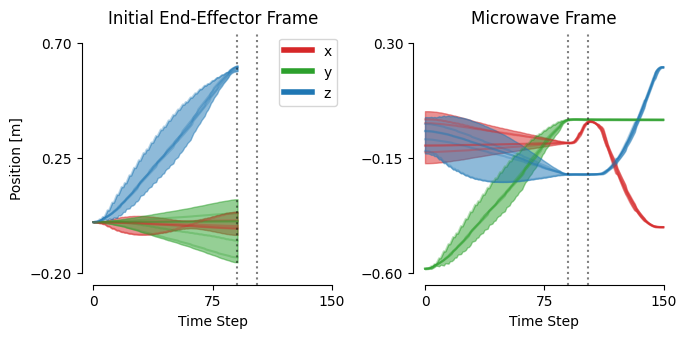
核心思路:MiDiGap的核心思路是使用离散时间高斯过程混合模型(Mixture of Discrete-time Gaussian Processes)来表示机器人策略。高斯过程具有非参数性,能够灵活地建模复杂的数据分布。通过混合多个高斯过程,MiDiGap可以表示多模态的策略行为。离散时间的设计使得模型更易于处理机器人控制中的时间序列数据。
技术框架:MiDiGap的学习过程主要包括以下几个阶段:1) 数据收集:通过人工示教或专家演示收集少量(例如5个)的轨迹数据。2) 模型训练:使用收集到的数据训练离散时间高斯过程混合模型。模型参数可以通过最大似然估计或其他优化方法进行学习。3) 策略执行:在执行阶段,MiDiGap根据当前的状态,预测下一步的动作。此外,MiDiGap还提供了一套工具,用于在推理时利用先验知识(如碰撞信号、运动学约束)来引导策略的执行。
关键创新:MiDiGap的关键创新在于将离散时间高斯过程混合模型应用于机器人策略学习。与传统的基于神经网络的策略学习方法相比,MiDiGap具有更高的样本效率和更好的泛化能力。此外,MiDiGap还提供了一套灵活的推理时引导机制,可以利用先验知识来提高策略的鲁棒性和安全性。
关键设计:MiDiGap的关键设计包括:1) 离散时间高斯过程的选择:使用离散时间高斯过程可以更好地建模机器人控制中的时间序列数据。2) 混合模型的选择:使用混合模型可以表示多模态的策略行为。3) 推理时引导机制:利用碰撞信号、运动学约束等先验知识来引导策略的执行,提高策略的鲁棒性和安全性。具体的参数设置和损失函数细节在论文中进行了详细描述(未知)。
🖼️ 关键图片


📊 实验亮点
MiDiGap在多个机器人操作基准测试中取得了显著的性能提升。在受约束的RLBench任务中,策略成功率提高了76个百分点,轨迹成本降低了67%。在多模态任务中,策略成功率提高了48个百分点,样本效率提高了20倍。在跨机器人迁移中,策略成功率提高了一倍以上。这些结果表明,MiDiGap是一种高效、鲁棒的机器人策略学习方法。
🎯 应用场景
MiDiGap具有广泛的应用前景,例如可应用于工业机器人自动化、家庭服务机器人、医疗机器人等领域。它可以帮助机器人快速学习各种复杂的操作任务,提高机器人的智能化水平和服务能力。通过跨机器人迁移,MiDiGap还可以降低机器人部署的成本和时间。
📄 摘要(原文)
We present Mixture of Discrete-time Gaussian Processes (MiDiGap), a novel approach for flexible policy representation and imitation learning in robot manipulation. MiDiGap enables learning from as few as five demonstrations using only camera observations and generalizes across a wide range of challenging tasks. It excels at long-horizon behaviors such as making coffee, highly constrained motions such as opening doors, dynamic actions such as scooping with a spatula, and multimodal tasks such as hanging a mug. MiDiGap learns these tasks on a CPU in less than a minute and scales linearly to large datasets. We also develop a rich suite of tools for inference-time steering using evidence such as collision signals and robot kinematic constraints. This steering enables novel generalization capabilities, including obstacle avoidance and cross-embodiment policy transfer. MiDiGap achieves state-of-the-art performance on diverse few-shot manipulation benchmarks. On constrained RLBench tasks, it improves policy success by 76 percentage points and reduces trajectory cost by 67%. On multimodal tasks, it improves policy success by 48 percentage points and increases sample efficiency by a factor of 20. In cross-embodiment transfer, it more than doubles policy success. We make the code publicly available at https://midigap.cs.uni-freiburg.de.