ViSA-Flow: Accelerating Robot Skill Learning via Large-Scale Video Semantic Action Flow
作者: Changhe Chen, Quantao Yang, Xiaohao Xu, Nima Fazeli, Olov Andersson
分类: cs.RO, cs.AI
发布日期: 2025-05-02 (更新: 2025-11-12)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
ViSA-Flow:通过大规模视频语义动作流加速机器人技能学习
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱五:交互与反应 (Interaction & Reaction)
关键词: 机器人技能学习 语义动作流 视频理解 知识迁移 自监督学习
📋 核心要点
- 机器人学习复杂操作技能面临的最大挑战之一是收集大规模机器人演示数据的成本过高。
- ViSA-Flow通过学习语义动作流,捕捉操纵器-物体交互的关键时空信息,实现视觉不变性。
- ViSA-Flow在CALVIN基准和真实世界任务中表现SOTA,尤其在低数据场景下,显著优于现有方法。
📝 摘要(中文)
本文提出ViSA-Flow框架,旨在解决机器人学习复杂操作技能时,对大规模机器人演示数据需求过高的问题。该框架利用语义动作流作为核心中间表示,捕捉操纵器-物体交互的时空信息,从而克服视觉差异带来的挑战。ViSA-Flow首先在无标签的大规模人-物交互视频数据上,自监督地预训练一个生成模型,学习操作结构的鲁棒先验。然后,通过在少量机器人演示数据上进行微调,将该先验知识高效地迁移到目标机器人。在CALVIN基准测试和真实世界任务上的实验表明,ViSA-Flow在低数据情况下表现出色,优于现有方法,实现了从人类视频观察到机器人执行的有效知识迁移。
🔬 方法详解
问题定义:机器人技能学习需要大量演示数据,而收集这些数据成本高昂。现有方法难以有效利用人类视频数据中的知识,导致机器人学习效率低下。因此,需要一种方法能够从人类视频中提取通用操作知识,并将其迁移到机器人上。
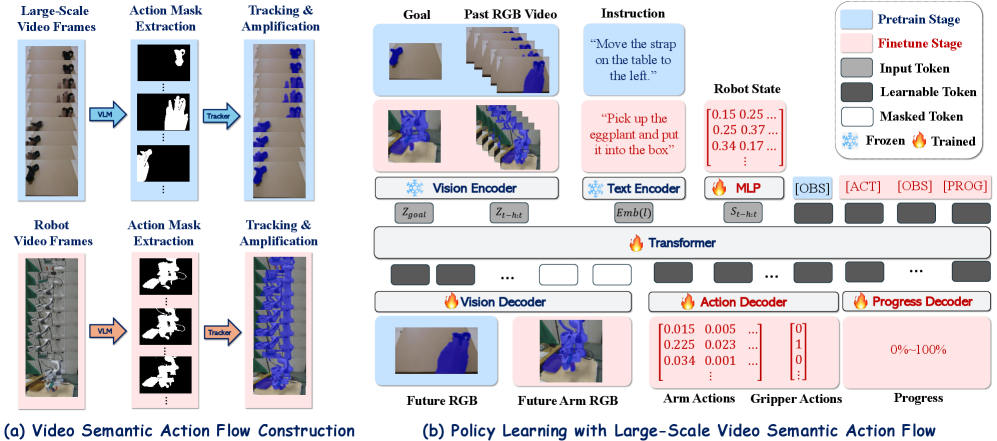
核心思路:论文的核心思路是利用语义动作流作为中间表示,将人类视频和机器人演示数据映射到统一的语义空间。通过学习人类视频中的操作先验,并将其迁移到机器人上,从而减少机器人对大量演示数据的依赖。这种方法的关键在于语义动作流能够捕捉操纵器-物体交互的关键信息,并忽略不相关的视觉细节。
技术框架:ViSA-Flow框架包含两个主要阶段:预训练和微调。在预训练阶段,框架使用大规模无标签的人-物交互视频数据,自监督地学习语义动作流的生成模型。在微调阶段,框架使用少量机器人演示数据,对预训练模型进行微调,使其适应目标机器人。整个流程包括:1. 从视频中提取语义动作流;2. 使用提取的语义动作流训练生成模型;3. 使用机器人数据微调生成模型;4. 使用微调后的模型控制机器人。
关键创新:论文的关键创新在于提出了语义动作流的概念,并将其应用于机器人技能学习。语义动作流能够有效地捕捉操纵器-物体交互的关键信息,并忽略不相关的视觉细节,从而实现从人类视频到机器人的知识迁移。此外,论文还提出了一种自监督学习方法,用于从大规模无标签视频数据中学习语义动作流的生成模型。
关键设计:论文使用了变分自编码器(VAE)作为生成模型,用于学习语义动作流的潜在空间表示。损失函数包括重构损失和KL散度损失,用于保证生成模型的重构能力和潜在空间的平滑性。在微调阶段,论文使用了少量机器人演示数据,对VAE的编码器和解码器进行微调。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
ViSA-Flow在CALVIN基准测试中取得了显著的性能提升,尤其是在低数据情况下。例如,在某些任务上,ViSA-Flow的性能超过了现有方法20%以上。此外,ViSA-Flow还在真实世界任务中进行了验证,证明了其在实际应用中的有效性。实验结果表明,ViSA-Flow能够有效地从人类视频中学习操作知识,并将其迁移到机器人上。
🎯 应用场景
ViSA-Flow具有广泛的应用前景,例如:家庭服务机器人、工业自动化、医疗机器人等。通过利用人类视频数据,可以显著降低机器人学习新技能的成本,提高机器人的智能化水平。未来,该技术有望应用于更复杂的机器人操作任务,例如:装配、拆卸、维修等。
📄 摘要(原文)
One of the central challenges preventing robots from acquiring complex manipulation skills is the prohibitive cost of collecting large-scale robot demonstrations. In contrast, humans are able to learn efficiently by watching others interact with their environment. To bridge this gap, we introduce semantic action flow as a core intermediate representation capturing the essential spatio-temporal manipulator-object interactions, invariant to superficial visual differences. We present ViSA-Flow, a framework that learns this representation self-supervised from unlabeled large-scale video data. First, a generative model is pre-trained on semantic action flows automatically extracted from large-scale human-object interaction video data, learning a robust prior over manipulation structure. Second, this prior is efficiently adapted to a target robot by fine-tuning on a small set of robot demonstrations processed through the same semantic abstraction pipeline. We demonstrate through extensive experiments on the CALVIN benchmark and real-world tasks that ViSA-Flow achieves state-of-the-art performance, particularly in low-data regimes, outperforming prior methods by effectively transferring knowledge from human video observation to robotic execution. Videos are available at https://visaflow-web.github.io/ViSAFLOW.