LightEMMA: Lightweight End-to-End Multimodal Model for Autonomous Driving
作者: Zhijie Qiao, Haowei Li, Zhong Cao, Henry X. Liu
分类: cs.RO, cs.AI
发布日期: 2025-05-01 (更新: 2025-09-13)
🔗 代码/项目: GITHUB
💡 一句话要点
LightEMMA:用于自动驾驶的轻量级端到端多模态模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 视觉-语言模型 多模态学习 端到端模型 nuScenes 轻量级模型 模型评估
📋 核心要点
- 现有端到端自动驾驶方法缺乏动态更新、快速验证和公平比较的实用平台,阻碍了VLM在该领域的应用。
- LightEMMA提供了一个统一的VLM框架,无需定制即可集成各类VLM,方便研究人员快速构建和评估自动驾驶智能体。
- 实验表明,虽然VLM具备场景理解能力,但在自动驾驶任务中性能仍有提升空间,且模型复杂性与性能并非线性相关。
📝 摘要(中文)
本文介绍LightEMMA,一个用于自动驾驶的轻量级端到端多模态模型。当前领域缺乏一个实用的平台,以支持动态模型更新、快速验证、公平比较和直观的性能评估。LightEMMA提供了一个统一的、基于视觉-语言模型(VLM)的自动驾驶框架,无需专门的定制,能够轻松集成最先进的商业和开源模型。我们使用各种VLM构建了十二个自动驾驶智能体,并在具有挑战性的nuScenes预测任务上评估了它们的性能,全面评估了计算指标并提供了关键见解。结果表明,尽管VLM表现出强大的场景理解能力,但它们在自动驾驶任务中的实际性能仍然令人担忧。此外,增加模型复杂性和扩展推理并不一定带来更好的性能,这强调了进一步改进和特定于任务的设计的必要性。代码已在GitHub上开源。
🔬 方法详解
问题定义:现有端到端自动驾驶系统缺乏一个统一且易于扩展的平台,难以集成和评估不同的视觉-语言模型(VLMs)。这阻碍了VLM在自动驾驶领域的快速发展和应用。现有的方法通常需要针对特定的VLM进行定制,缺乏通用性和可比性。
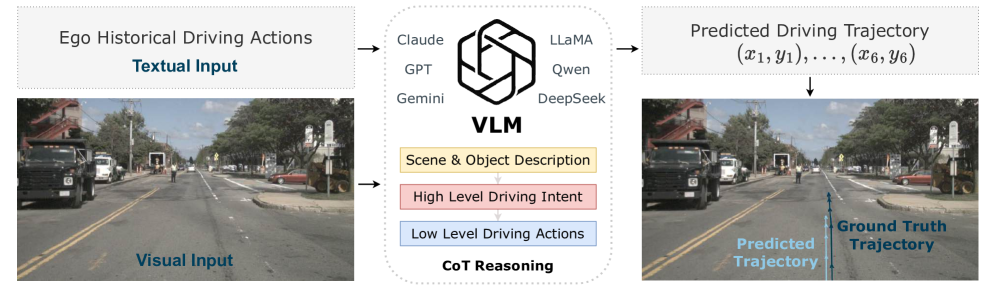
核心思路:LightEMMA的核心思路是构建一个轻量级的、端到端的、基于VLM的自动驾驶框架,该框架能够无缝集成各种VLM,并提供统一的接口进行模型更新、验证和性能评估。通过提供一个标准化的平台,LightEMMA旨在促进VLM在自动驾驶领域的研究和应用。
技术框架:LightEMMA框架主要包含以下几个模块:1) 感知模块:负责从传感器数据(如摄像头图像)中提取视觉特征;2) VLM模块:利用预训练的VLM对视觉特征进行理解和推理,生成驾驶决策;3) 控制模块:根据VLM的决策,控制车辆的运动;4) 评估模块:对自动驾驶智能体的性能进行评估,包括预测精度、安全性等。整个流程是端到端的,从传感器数据输入到车辆控制输出。
关键创新:LightEMMA的关键创新在于其统一的VLM集成框架,它允许研究人员轻松地将不同的VLM插入到自动驾驶系统中,而无需进行大量的定制工作。此外,LightEMMA还提供了一套全面的评估指标,用于评估自动驾驶智能体的性能。这使得研究人员可以更方便地比较不同VLM在自动驾驶任务中的表现。
关键设计:LightEMMA的关键设计包括:1) 轻量级的模型架构,以减少计算资源的需求;2) 标准化的VLM接口,方便集成不同的VLM;3) 可配置的参数设置,允许研究人员根据不同的任务需求进行调整;4) 详细的日志记录和可视化工具,方便分析和调试。
🖼️ 关键图片
📊 实验亮点
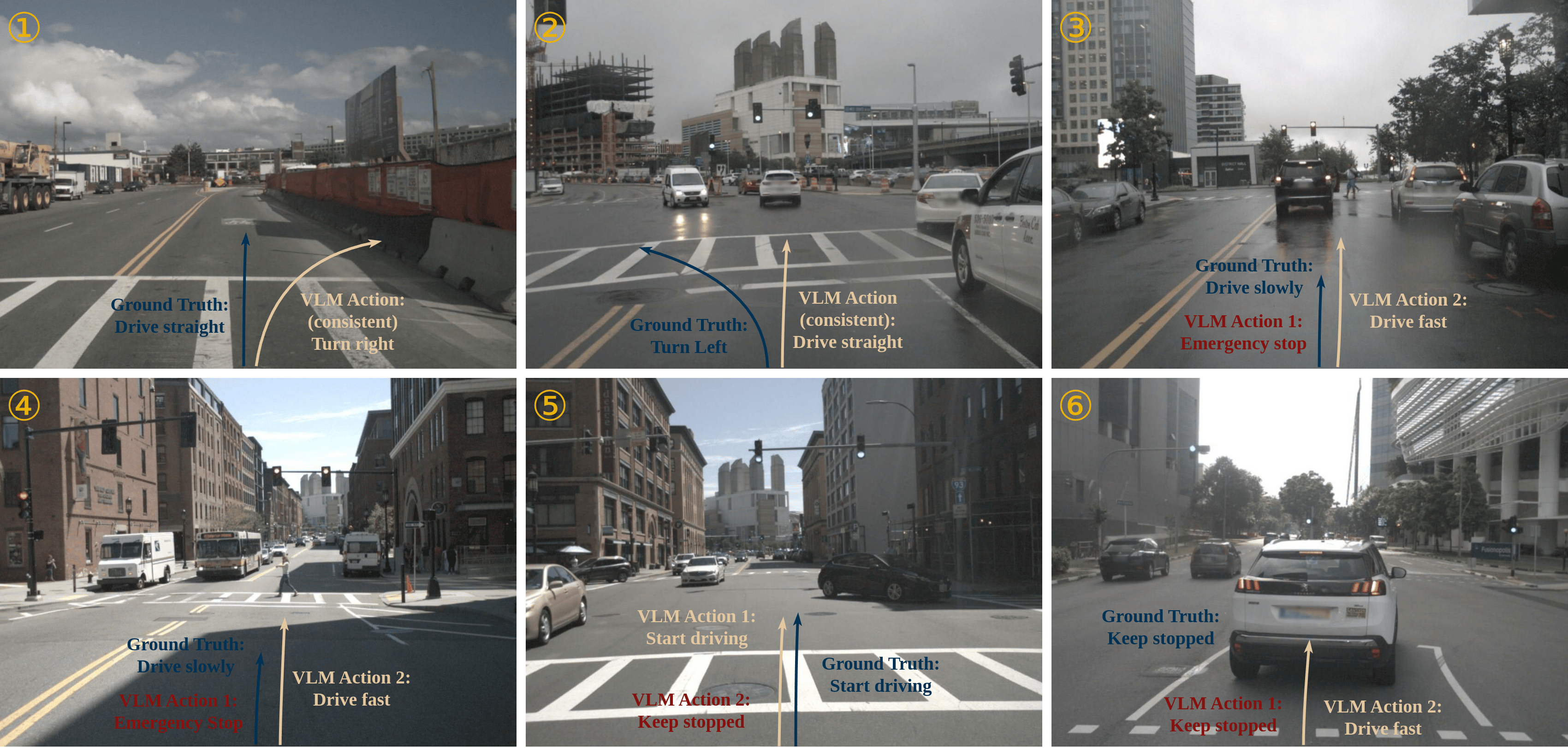
通过在nuScenes数据集上的实验,研究人员使用LightEMMA构建了12个基于不同VLM的自动驾驶智能体,并对其性能进行了全面评估。实验结果表明,尽管VLMs在场景理解方面表现出色,但其在自动驾驶任务中的实际性能仍有待提高。此外,研究还发现,增加模型复杂性和推理深度并不一定能带来更好的性能,这表明需要针对自动驾驶任务进行更精细的模型设计和优化。
🎯 应用场景
LightEMMA可应用于自动驾驶汽车、无人配送车、智能交通系统等领域。它提供了一个通用的VLM集成平台,加速了VLM在自动驾驶领域的应用研究。通过LightEMMA,研究人员可以更高效地开发和评估新的自动驾驶算法,从而提高自动驾驶系统的安全性、可靠性和智能化水平。未来,LightEMMA有望成为自动驾驶领域的重要基础设施。
📄 摘要(原文)
Vision-Language Models (VLMs) have demonstrated significant potential for end-to-end autonomous driving. However, the field still lacks a practical platform that enables dynamic model updates, rapid validation, fair comparison, and intuitive performance assessment. To that end, we introduce LightEMMA, a Lightweight End-to-End Multimodal Model for Autonomous driving. LightEMMA provides a unified, VLM-based autonomous driving framework without ad hoc customizations, enabling easy integration with evolving state-of-the-art commercial and open-source models. We construct twelve autonomous driving agents using various VLMs and evaluate their performance on the challenging nuScenes prediction task, comprehensively assessing computational metrics and providing critical insights. Illustrative examples show that, although VLMs exhibit strong scenario interpretation capabilities, their practical performance in autonomous driving tasks remains a concern. Additionally, increased model complexity and extended reasoning do not necessarily lead to better performance, emphasizing the need for further improvements and task-specific designs. The code is available at https://github.com/michigan-traffic-lab/LightEMMA.