Deep Reinforcement Learning Policies for Underactuated Satellite Attitude Control
作者: Matteo El Hariry, Andrea Cini, Giacomo Mellone, Alessandro Balossino
分类: cs.RO
发布日期: 2025-04-30
备注: Originally presented at the NeurIPS 2021 Workshop on Deployable Decision-Making in Embodied Systems
期刊: NeurIPS 2021 Workshop on Deployable Decision-Making in Embodied Systems
💡 一句话要点
提出基于深度强化学习的卫星姿态控制策略,解决欠驱动场景下的再定向问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 卫星姿态控制 深度强化学习 欠驱动系统 近端策略优化 自主控制
📋 核心要点
- 未来太空探索的关键挑战是自主性,现有方法难以应对复杂环境和执行器故障。
- 利用深度强化学习,通过与环境交互学习复杂行为,实现卫星姿态控制策略。
- 实验表明,该方法能快速收敛到工业标准精度,并在硬件测试中表现良好。
📝 摘要(中文)
本文研究了使用强化学习解决卫星姿态控制问题,即航天器相对于惯性参考系的角重新定向。提出了一种方法,将一组控制策略实现为神经网络,并使用近端策略优化算法的自定义版本进行训练,以将小型卫星从随机起始角度操纵到给定的指向目标。特别地,本文解决了两种工作条件下的问题:标称情况,其中所有执行器(一组3个反作用轮)正常工作;以及欠驱动情况,其中沿一个轴随机模拟执行器故障。结果表明,智能体学会有效地执行大角度回转机动,具有快速收敛性和工业标准指向精度。此外,本文在代表性硬件上测试了所提出的方法,表明通过采取适当的措施,在仿真中训练的控制器可以在实际系统中表现良好。
🔬 方法详解
问题定义:论文旨在解决卫星姿态控制问题,特别是在欠驱动情况下(即部分反作用轮失效)的大角度快速再定向问题。现有的姿态控制方法可能难以适应执行器故障,或者需要复杂的模型和参数调整,缺乏自主性和鲁棒性。
核心思路:论文的核心思路是利用深度强化学习(DRL)训练智能体,使其能够通过与环境的交互学习最优的控制策略。通过奖励函数引导智能体学习如何利用剩余的执行器完成姿态调整,从而实现对执行器故障的自适应。
技术框架:整体框架包括以下几个主要部分:1)环境建模:建立卫星动力学模型,包括姿态、角速度、执行器(反作用轮)等;2)智能体设计:使用神经网络作为策略函数,输入状态(如姿态、角速度),输出控制指令(反作用轮力矩);3)强化学习算法:采用近端策略优化(PPO)算法的自定义版本进行训练,PPO算法是一种常用的策略梯度算法,能够保证训练的稳定性和收敛性;4)奖励函数设计:设计合适的奖励函数,引导智能体学习期望的行为,例如快速到达目标姿态、减少控制能量消耗等。
关键创新:论文的关键创新在于将深度强化学习应用于欠驱动卫星姿态控制问题,并证明了其有效性。与传统的控制方法相比,DRL方法能够自动学习控制策略,无需人工设计复杂的控制律,并且能够适应执行器故障等不确定性。此外,论文还针对卫星姿态控制问题,对PPO算法进行了定制,提高了训练效率和性能。
关键设计:论文中一些关键的设计包括:1)奖励函数的设计,需要平衡快速到达目标姿态和控制能量消耗之间的关系;2)神经网络结构的选择,需要考虑计算复杂度和表达能力之间的平衡;3)PPO算法的参数调整,例如学习率、裁剪参数等,需要根据具体问题进行优化;4)为了提高在真实硬件上的性能,论文采取了在仿真环境中进行训练,然后将训练好的策略迁移到真实硬件上的方法。为了弥补仿真环境和真实环境之间的差异,可能需要进行一些额外的调整和优化。
🖼️ 关键图片
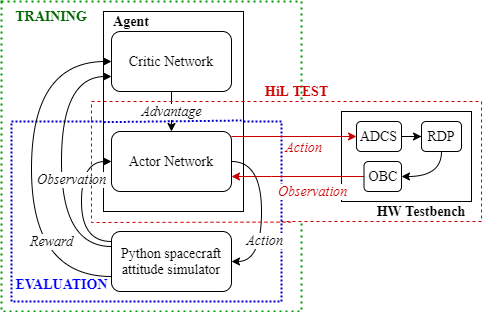


📊 实验亮点
实验结果表明,所提出的方法能够有效地控制卫星姿态,即使在存在执行器故障的情况下也能实现快速和精确的再定向。智能体能够学习执行大角度回转机动,并达到工业标准的指向精度。此外,在代表性硬件上的测试表明,通过适当的措施,在仿真中训练的控制器可以在实际系统中表现良好,验证了该方法的实用性。
🎯 应用场景
该研究成果可应用于各种航天任务,例如地球观测、空间科学、通信等。特别是在需要高自主性和容错能力的场景下,例如深空探测、编队飞行等,基于深度强化学习的姿态控制策略具有重要的应用价值。此外,该方法还可以推广到其他欠驱动系统的控制问题,例如水下机器人、无人机等。
📄 摘要(原文)
Autonomy is a key challenge for future space exploration endeavours. Deep Reinforcement Learning holds the promises for developing agents able to learn complex behaviours simply by interacting with their environment. This paper investigates the use of Reinforcement Learning for the satellite attitude control problem, namely the angular reorientation of a spacecraft with respect to an in- ertial frame of reference. In the proposed approach, a set of control policies are implemented as neural networks trained with a custom version of the Proximal Policy Optimization algorithm to maneuver a small satellite from a random starting angle to a given pointing target. In particular, we address the problem for two working conditions: the nominal case, in which all the actuators (a set of 3 reac- tion wheels) are working properly, and the underactuated case, where an actuator failure is simulated randomly along with one of the axes. We show that the agents learn to effectively perform large-angle slew maneuvers with fast convergence and industry-standard pointing accuracy. Furthermore, we test the proposed method on representative hardware, showing that by taking adequate measures controllers trained in simulation can perform well in real systems.