UAV-VLN: End-to-End Vision Language guided Navigation for UAVs
作者: Pranav Saxena, Nishant Raghuvanshi, Neena Goveas
分类: cs.RO, cs.CV
发布日期: 2025-04-30
期刊: Proc. European Conference on Mobile Robots (ECMR), 2025, pp. 1-6
DOI: 10.1109/ECMR65884.2025.11163198
💡 一句话要点
提出UAV-VLN,用于无人机在复杂环境中基于自然语言指令的端到端视觉语言导航。
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 无人机导航 视觉语言导航 大型语言模型 跨模态融合 端到端学习
📋 核心要点
- 现有方法难以使智能体在未见环境中根据自然语言命令进行真实有效的导航。
- UAV-VLN框架融合大型语言模型和视觉感知,解析指令并规划无人机轨迹。
- 实验表明,UAV-VLN在指令遵循准确性和轨迹效率方面有显著提升。
📝 摘要(中文)
本文提出了一种新颖的端到端视觉语言导航(VLN)框架UAV-VLN,用于无人机(UAV),该框架无缝集成了大型语言模型(LLM)与视觉感知,以促进人机交互导航。该系统能够解释自由形式的自然语言指令,将其与视觉观察对齐,并在各种环境中规划可行的空中轨迹。UAV-VLN利用LLM的常识推理能力来解析高层语义目标,同时视觉模型检测并定位环境中语义相关的对象。通过融合这些模态,无人机可以推理空间关系,消除人类指令中的歧义,并以最少的任务特定监督来规划上下文感知的行为。为了确保鲁棒且可解释的决策,该框架包含一种跨模态对齐机制,将语言意图与视觉上下文对齐。在各种室内和室外导航场景中评估了UAV-VLN,证明了其推广到新的指令和环境的能力,且只需最少的任务特定训练。结果表明,指令遵循准确性和轨迹效率得到了显著提高,突出了LLM驱动的视觉语言界面在安全、直观和可推广的无人机自主性方面的潜力。
🔬 方法详解
问题定义:论文旨在解决无人机在复杂环境中,如何根据自然语言指令进行导航的问题。现有方法通常依赖于大量的任务特定数据或复杂的中间表示,泛化能力较弱,难以适应新的环境和指令。此外,如何将高层语义指令与底层视觉感知有效结合也是一个挑战。
核心思路:论文的核心思路是利用大型语言模型(LLM)的常识推理能力来理解自然语言指令,并将其与视觉信息融合,从而实现上下文感知的导航。通过跨模态对齐,使无人机能够理解指令中的空间关系和语义信息,并规划出可行的轨迹。
技术框架:UAV-VLN框架主要包含以下几个模块:1) 自然语言指令解析模块,利用LLM将自然语言指令解析为语义表示;2) 视觉感知模块,检测和定位环境中的语义相关对象;3) 跨模态融合模块,将语义表示和视觉信息融合,推理空间关系和上下文信息;4) 轨迹规划模块,根据融合后的信息规划无人机的可行轨迹。整个流程是端到端的,可以进行联合优化。
关键创新:该论文的关键创新在于将大型语言模型与视觉感知相结合,实现了一种端到端的无人机视觉语言导航框架。与传统方法相比,UAV-VLN能够更好地理解自然语言指令,并根据环境信息进行上下文感知的导航。此外,该框架具有较强的泛化能力,可以适应新的环境和指令,而无需大量的任务特定训练。
关键设计:论文中关键的设计包括:1) 使用预训练的LLM作为自然语言指令解析器,利用其强大的语义理解能力;2) 设计了一种跨模态对齐机制,将语言意图与视觉上下文对齐,从而实现更准确的导航;3) 采用端到端的训练方式,可以联合优化各个模块,提高整体性能。具体的参数设置、损失函数和网络结构等技术细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片
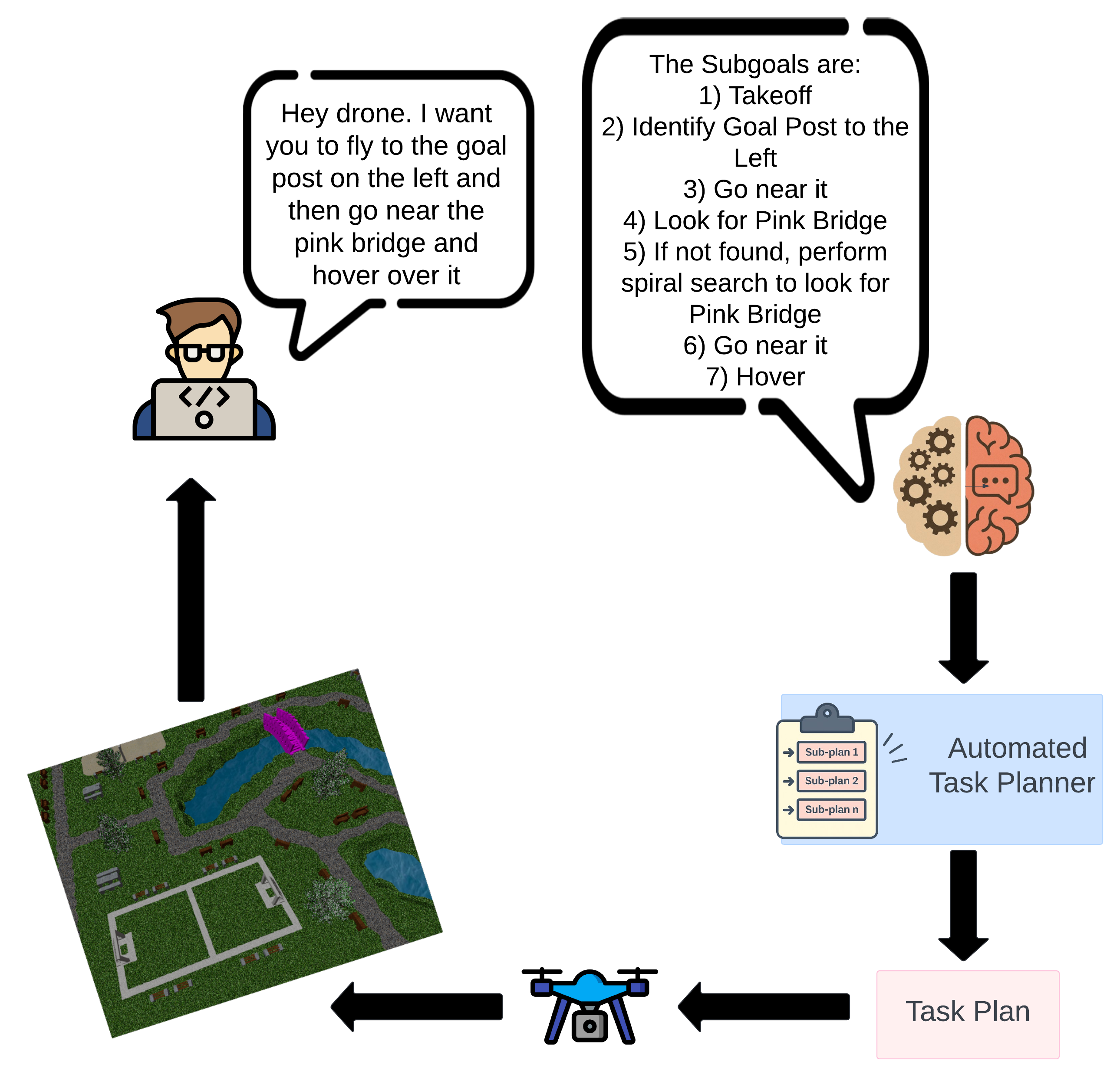


📊 实验亮点
UAV-VLN在各种室内和室外导航场景中进行了评估,结果表明,该方法能够推广到新的指令和环境,且只需最少的任务特定训练。实验结果显示,指令遵循准确性和轨迹效率得到了显著提高,证明了LLM驱动的视觉语言界面在无人机自主导航方面的潜力。具体的性能数据和提升幅度在摘要中未明确给出,属于未知信息。
🎯 应用场景
该研究成果可应用于物流配送、环境监测、灾害救援等领域。通过自然语言指令控制无人机,可以降低操作门槛,提高任务效率。未来,该技术有望实现更智能、更自主的无人机导航,为各行业带来便利。
📄 摘要(原文)
A core challenge in AI-guided autonomy is enabling agents to navigate realistically and effectively in previously unseen environments based on natural language commands. We propose UAV-VLN, a novel end-to-end Vision-Language Navigation (VLN) framework for Unmanned Aerial Vehicles (UAVs) that seamlessly integrates Large Language Models (LLMs) with visual perception to facilitate human-interactive navigation. Our system interprets free-form natural language instructions, grounds them into visual observations, and plans feasible aerial trajectories in diverse environments. UAV-VLN leverages the common-sense reasoning capabilities of LLMs to parse high-level semantic goals, while a vision model detects and localizes semantically relevant objects in the environment. By fusing these modalities, the UAV can reason about spatial relationships, disambiguate references in human instructions, and plan context-aware behaviors with minimal task-specific supervision. To ensure robust and interpretable decision-making, the framework includes a cross-modal grounding mechanism that aligns linguistic intent with visual context. We evaluate UAV-VLN across diverse indoor and outdoor navigation scenarios, demonstrating its ability to generalize to novel instructions and environments with minimal task-specific training. Our results show significant improvements in instruction-following accuracy and trajectory efficiency, highlighting the potential of LLM-driven vision-language interfaces for safe, intuitive, and generalizable UAV autonomy.