M2R2: MultiModal Robotic Representation for Temporal Action Segmentation
作者: Daniel Sliwowski, Dongheui Lee
分类: cs.RO, cs.AI
发布日期: 2025-04-25 (更新: 2025-11-24)
备注: 8 pages, 6 figures, 2 tables
💡 一句话要点
提出M2R2多模态机器人表征,用于时序动作分割,提升机器人操作性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时序动作分割 多模态融合 机器人操作 特征提取 预训练
📋 核心要点
- 现有机器人时序动作分割模型难以复用特征,且视觉特征提取器在低可见性下表现差。
- M2R2通过结合本体感受和外部感受信息,并采用新颖的预训练策略,实现特征复用。
- 在REASSEMBLE数据集上,M2R2超越现有机器人动作分割模型46.6%,性能显著提升。
📝 摘要(中文)
时序动作分割(TAS)一直是机器人和计算机视觉领域的研究重点。在机器人领域,算法主要侧重于利用本体感受信息来确定技能边界,最近的手术机器人方法也开始结合视觉信息。相比之下,计算机视觉通常依赖于外部传感器,如摄像头。现有的机器人多模态TAS模型在模型内部进行特征融合,使得学习到的特征难以在不同模型中复用。同时,计算机视觉中常用的预训练视觉特征提取器在物体可见性有限的情况下表现不佳。为了解决这些挑战,我们提出了M2R2,一种专为TAS设计的多模态特征提取器,它结合了本体感受和外部感受传感器的信息。我们引入了一种新颖的预训练策略,使得学习到的特征可以在多个TAS模型中复用。我们的方法在REASSEMBLE数据集上取得了最先进的性能,这是一个具有挑战性的多模态机器人组装数据集,超越了现有的机器人动作分割模型46.6%。此外,我们进行了广泛的消融研究,以评估不同模态在机器人TAS任务中的贡献。
🔬 方法详解
问题定义:论文旨在解决机器人时序动作分割任务中,现有方法存在的特征复用性差以及视觉信息在低可见性场景下表现不佳的问题。现有的多模态方法通常在模型内部进行特征融合,导致学习到的特征难以在不同任务或模型之间迁移。同时,依赖于视觉信息的模型在物体被遮挡或光照条件不佳时,性能会显著下降。
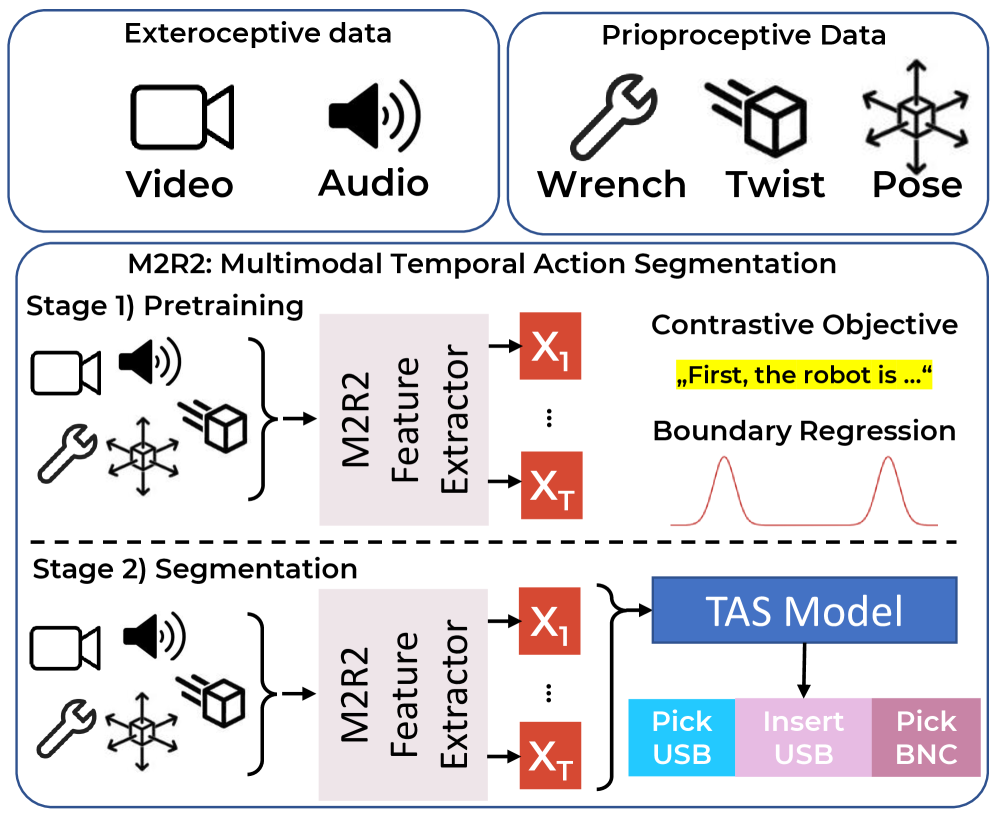
核心思路:论文的核心思路是设计一个独立于具体任务的多模态特征提取器M2R2,该提取器能够有效地融合来自本体感受和外部感受传感器的信息,并采用一种新颖的预训练策略,使得学习到的特征具有良好的泛化能力和可复用性。通过解耦特征提取和任务执行,可以方便地将学习到的特征应用于不同的时序动作分割模型。
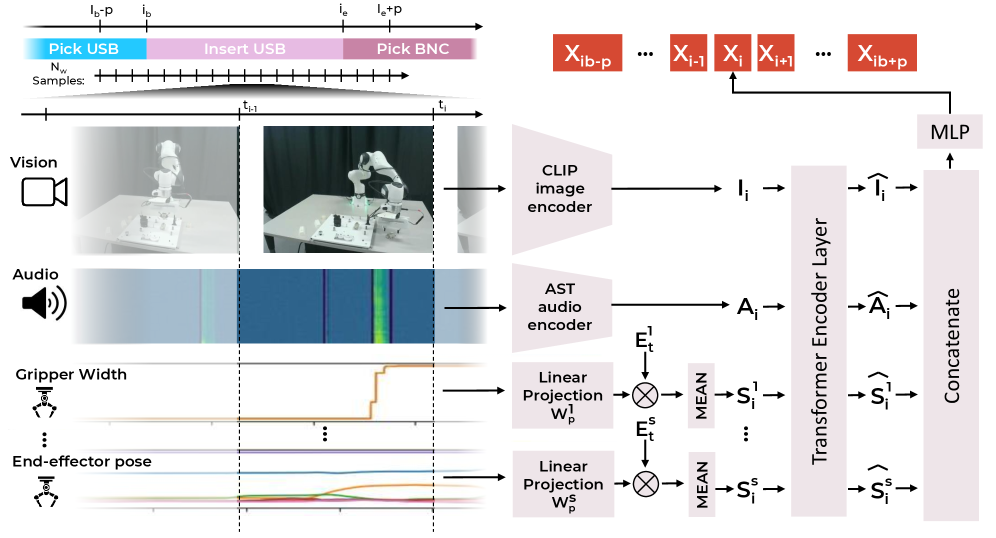
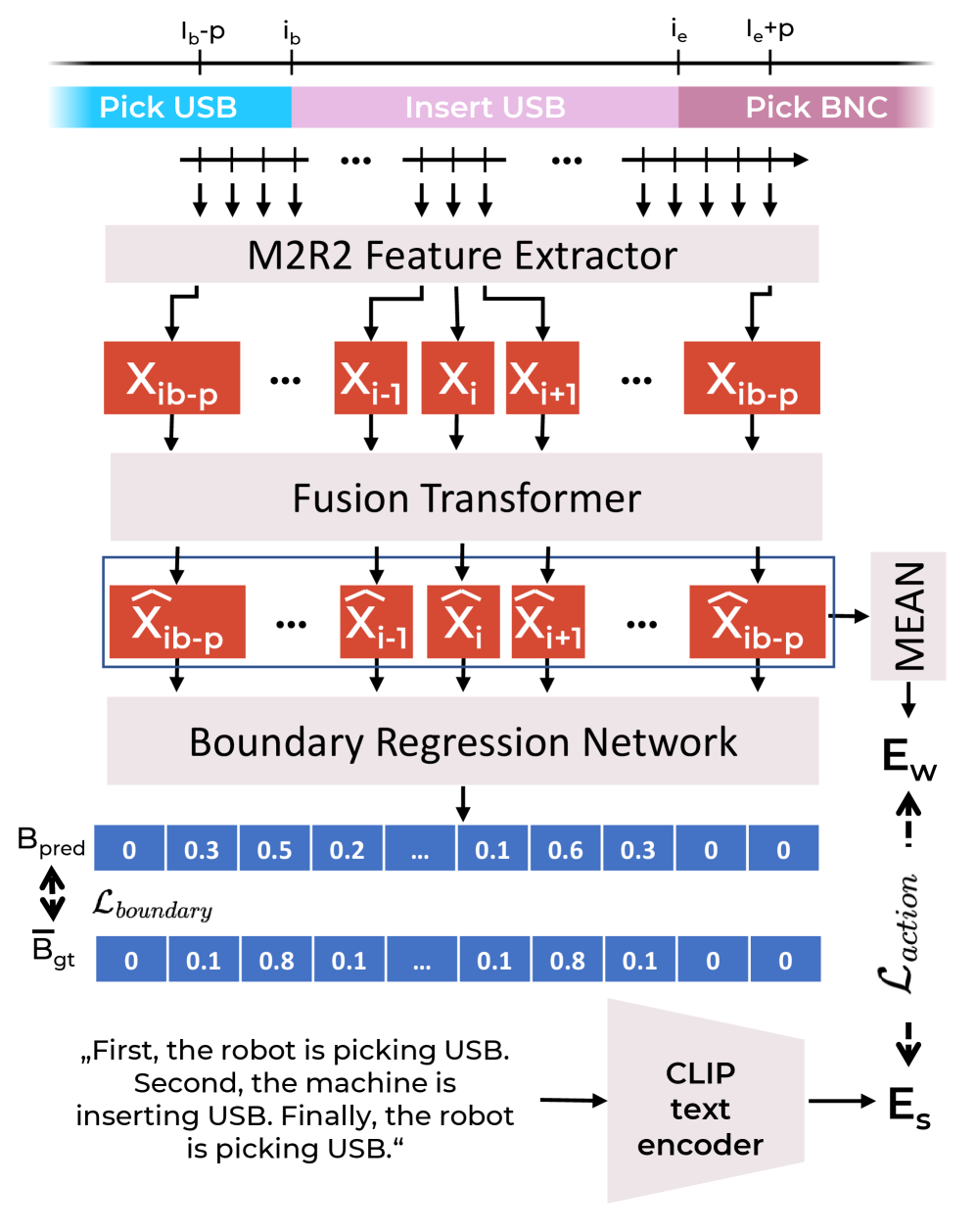
技术框架:M2R2的整体框架包含两个主要阶段:多模态特征提取和时序动作分割。首先,M2R2接收来自机器人本体感受传感器(如关节角度、力矩等)和外部感受传感器(如摄像头)的数据作为输入。然后,通过特定的网络结构(具体结构未知)对不同模态的数据进行编码,并将编码后的特征进行融合。最后,将提取到的多模态特征输入到下游的时序动作分割模型中进行训练和预测。
关键创新:论文的关键创新在于提出了一个独立的多模态特征提取器M2R2,以及一种新颖的预训练策略。M2R2能够有效地融合来自不同模态的信息,并学习到具有良好泛化能力的特征表示。预训练策略使得学习到的特征可以在多个TAS模型中复用,从而提高了模型的效率和性能。与现有方法相比,M2R2实现了特征提取和任务执行的解耦,提高了模型的灵活性和可扩展性。
关键设计:论文中关于M2R2的具体网络结构、融合策略以及预训练策略的细节描述不足,具体参数设置、损失函数和网络结构等未知。但可以推测,M2R2可能采用了某种注意力机制或Transformer结构来实现多模态特征的有效融合。预训练策略可能涉及到自监督学习或对比学习等技术,以提高特征的泛化能力。
🖼️ 关键图片
📊 实验亮点
M2R2在REASSEMBLE数据集上取得了显著的性能提升,超越了现有机器人动作分割模型46.6%,达到了state-of-the-art的水平。这一结果表明,M2R2能够有效地融合多模态信息,并学习到具有良好泛化能力的特征表示。消融实验进一步验证了不同模态对机器人TAS任务的贡献,为未来的研究提供了重要的参考。
🎯 应用场景
该研究成果可广泛应用于各种机器人操作任务中,例如工业自动化、医疗手术机器人、家庭服务机器人等。通过提高机器人对动作的理解和分割能力,可以使机器人更加智能、高效地完成复杂任务,并提升人机协作的安全性。未来,该研究有望推动机器人技术在更多领域的应用。
📄 摘要(原文)
Temporal action segmentation (TAS) has long been a key area of research in both robotics and computer vision. In robotics, algorithms have primarily focused on leveraging proprioceptive information to determine skill boundaries, with recent approaches in surgical robotics incorporating vision. In contrast, computer vision typically relies on exteroceptive sensors, such as cameras. Existing multimodal TAS models in robotics integrate feature fusion within the model, making it difficult to reuse learned features across different models. Meanwhile, pretrained vision-only feature extractors commonly used in computer vision struggle in scenarios with limited object visibility. In this work, we address these challenges by proposing M2R2, a multimodal feature extractor tailored for TAS, which combines information from both proprioceptive and exteroceptive sensors. We introduce a novel pretraining strategy that enables the reuse of learned features across multiple TAS models. Our method achieves state-of-the-art performance on the REASSEMBLE dataset, a challenging multimodal robotic assembly dataset, outperforming existing robotic action segmentation models by 46.6%. Additionally, we conduct an extensive ablation study to evaluate the contribution of different modalities in robotic TAS tasks.