RL-Driven Data Generation for Robust Vision-Based Dexterous Grasping
作者: Atsushi Kanehira, Naoki Wake, Kazuhiro Sasabuchi, Jun Takamatsu, Katsushi Ikeuchi
分类: cs.RO
发布日期: 2025-04-25
💡 一句话要点
提出基于强化学习的数据生成方法,提升灵巧抓取视觉-动作模型的鲁棒性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 灵巧抓取 强化学习 数据增强 视觉-动作模型 机器人操作
📋 核心要点
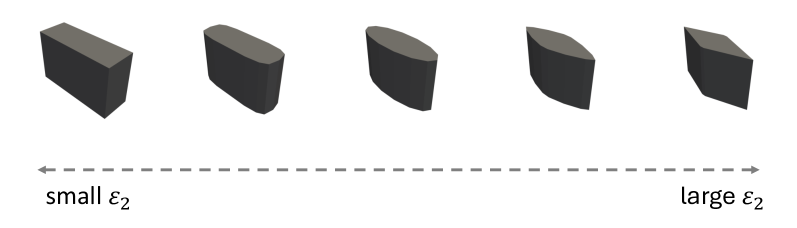
- 现有灵巧抓取视觉-动作模型在泛化性方面存在不足,难以在不同物体形状上获得稳定的多指接触。
- 利用强化学习生成具有丰富接触的抓取数据,并结合参数化参考轨迹和残差策略,实现对不同几何形状的适应。
- 实验结果表明,通过模拟增强数据训练的视觉条件策略,对未见物体表现出强大的泛化能力。
📝 摘要(中文)
本文提出了一种基于强化学习(RL)驱动的数据增强方法,旨在提高视觉-动作(VA)模型在灵巧抓取任务中的泛化能力。虽然real-to-sim-to-real框架,即少量真实数据引导大规模模拟数据,已被证明对VA模型有效,但将其应用于灵巧操作仍然具有挑战性:在不同的物体形状上获得稳定的多指接触并非易事。为了解决这个问题,我们利用强化学习生成具有丰富接触的抓取数据,覆盖各种几何形状。与real-to-sim-to-real范式一致,抓取技能被公式化为参数化和可调的参考轨迹,并通过强化学习学习到的残差策略进行优化。这种模块化设计实现了轨迹级别的控制,既与真实演示一致,又能适应不同的物体几何形状。在模拟增强数据上训练的视觉条件策略表现出对未见物体的强大泛化能力,突出了我们的方法在缓解训练VA模型中的数据瓶颈方面的潜力。
🔬 方法详解
问题定义:论文旨在解决灵巧抓取任务中,视觉-动作(VA)模型泛化性不足的问题。现有方法,特别是依赖于少量真实数据和大量模拟数据的real-to-sim-to-real框架,在灵巧操作中面临挑战,因为难以在各种物体形状上获得稳定的多指接触。这导致模型在真实环境中对未见物体的抓取性能下降。
核心思路:论文的核心思路是利用强化学习(RL)自动生成高质量的抓取数据,以增强训练数据的多样性,从而提高VA模型的泛化能力。通过RL,可以探索不同的抓取策略,并生成包含丰富接触信息的抓取数据,弥补了传统方法在处理复杂物体形状时的不足。
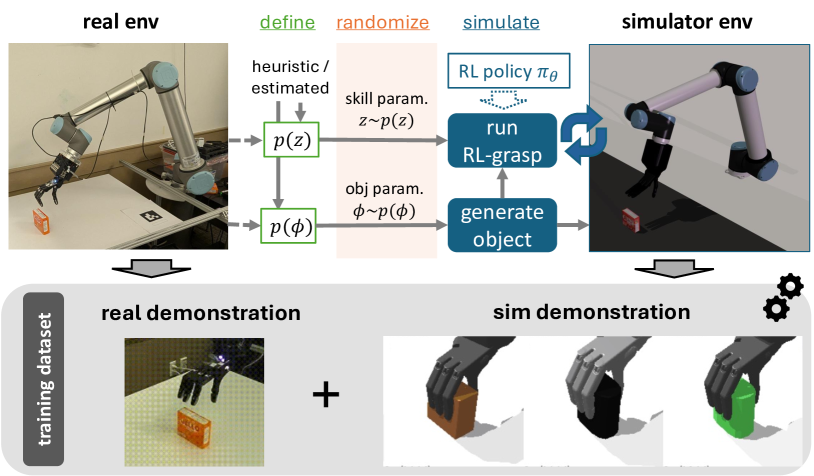
技术框架:整体框架遵循real-to-sim-to-real范式。首先,利用少量真实数据作为初始演示。然后,在模拟环境中,使用RL训练一个残差策略,该策略用于优化一个参数化的参考轨迹。这个参考轨迹定义了抓取技能的基本运动模式。RL策略的目标是最大化抓取的成功率,并鼓励产生丰富的接触。最后,使用生成的模拟数据训练一个视觉条件策略,该策略将视觉输入映射到抓取动作。
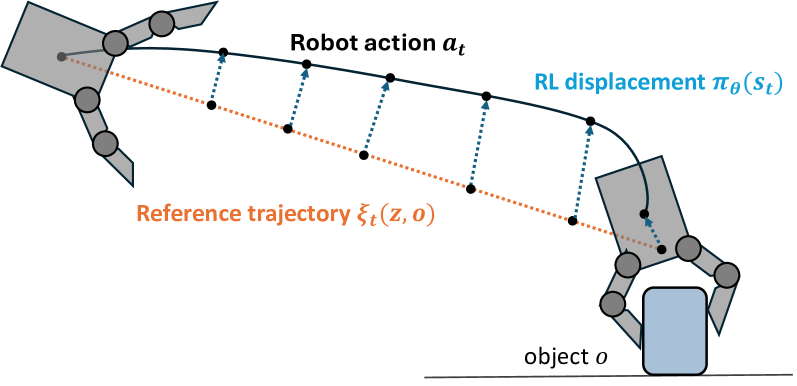
关键创新:论文的关键创新在于使用RL驱动的数据生成方法,自动生成具有丰富接触信息的抓取数据。与传统的手动设计或基于规则的数据生成方法相比,RL能够更有效地探索抓取策略空间,并生成更具多样性和挑战性的数据。此外,将抓取技能分解为参数化参考轨迹和残差策略,实现了轨迹级别的控制,既保证了与真实演示的一致性,又允许模型适应不同的物体几何形状。
关键设计:抓取技能被建模为参数化的参考轨迹,该轨迹定义了手指的运动模式。残差策略是一个神经网络,它接收视觉输入和当前轨迹状态,并输出对轨迹的修正。RL的目标函数包括抓取成功率和接触奖励,鼓励模型产生稳定的多指接触。具体的网络结构和参数设置在论文中进行了详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,通过RL驱动的数据增强方法,VA模型在未见物体上的抓取成功率得到了显著提升。具体性能数据和对比基线在论文中进行了详细描述(未知),但总体而言,该方法有效地缓解了数据瓶颈,提高了模型的泛化能力。
🎯 应用场景
该研究成果可应用于机器人自动化领域,例如工业抓取、家庭服务机器人等。通过提高机器人抓取操作的鲁棒性和泛化能力,可以实现更灵活、更可靠的自动化生产线和更智能的家庭服务。此外,该方法还可以扩展到其他灵巧操作任务,例如装配、操作工具等。
📄 摘要(原文)
This work presents reinforcement learning (RL)-driven data augmentation to improve the generalization of vision-action (VA) models for dexterous grasping. While real-to-sim-to-real frameworks, where a few real demonstrations seed large-scale simulated data, have proven effective for VA models, applying them to dexterous settings remains challenging: obtaining stable multi-finger contacts is nontrivial across diverse object shapes. To address this, we leverage RL to generate contact-rich grasping data across varied geometries. In line with the real-to-sim-to-real paradigm, the grasp skill is formulated as a parameterized and tunable reference trajectory refined by a residual policy learned via RL. This modular design enables trajectory-level control that is both consistent with real demonstrations and adaptable to diverse object geometries. A vision-conditioned policy trained on simulation-augmented data demonstrates strong generalization to unseen objects, highlighting the potential of our approach to alleviate the data bottleneck in training VA models.