Grasping Deformable Objects via Reinforcement Learning with Cross-Modal Attention to Visuo-Tactile Inputs
作者: Yonghyun Lee, Sungeun Hong, Min-gu Kim, Gyeonghwan Kim, Changjoo Nam
分类: cs.RO
发布日期: 2025-04-22 (更新: 2025-10-12)
💡 一句话要点
提出基于跨模态注意力强化学习方法,解决软体抓取问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 软体抓取 深度强化学习 跨模态注意力 视觉触觉融合 机器人操作
📋 核心要点
- 软体抓取面临物体形变和动态重心变化的挑战,传统方法难以有效控制。
- 提出基于跨模态注意力的强化学习方法,融合视觉和触觉信息,提升抓取性能。
- 实验表明,该方法在不同环境和物体上优于其他融合方法,验证了有效性。
📝 摘要(中文)
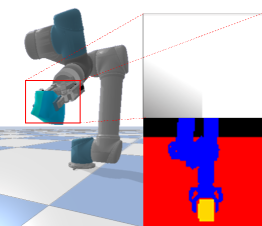
本文研究了使用机器人夹爪抓取具有柔软外壳的可变形物体的问题。这类物体的重心动态变化且易碎,因此机器人难以生成适当的控制输入,以避免在操作过程中掉落或损坏物体。多模态传感数据可以通过视觉数据的全局信息(如形状、姿态)和触觉数据的接触局部信息(如压力)来帮助理解抓取状态。尽管它们具有互补信息,但由于其不同的属性,融合它们很困难。本文提出了一种基于深度强化学习(DRL)的方法,该方法从视觉-触觉传感信息生成简单夹爪的控制输入。我们的方法在编码器网络中采用跨模态注意力模块,并使用RL代理的损失函数以自监督方式对其进行训练。通过多模态融合,该方法可以从视觉-触觉传感数据中学习DRL代理的表征。实验结果表明,跨模态注意力在不同的环境中(包括未见过的机器人运动和物体)优于其他早期和晚期数据融合方法。
🔬 方法详解
问题定义:论文旨在解决机器人抓取软壳可变形物体的问题。这类物体由于其动态变化的重心和易碎性,使得机器人难以生成合适的控制策略,从而容易导致抓取失败或物体损坏。现有的方法要么依赖于单一模态的信息,要么采用简单的融合策略,无法充分利用视觉和触觉数据的互补性。
核心思路:论文的核心思路是利用深度强化学习(DRL)框架,结合跨模态注意力机制,学习一个能够根据视觉和触觉信息生成抓取控制策略的智能体。通过跨模态注意力,模型可以自适应地关注不同模态中与抓取任务相关的特征,从而实现更鲁棒和有效的抓取。
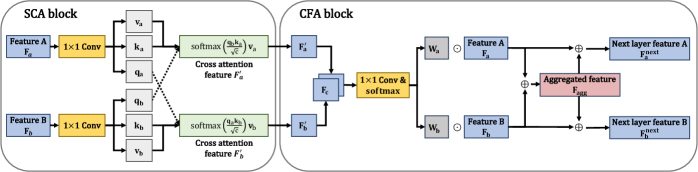
技术框架:整体框架包含一个DRL智能体和一个编码器网络。编码器网络接收视觉和触觉输入,通过跨模态注意力模块进行特征融合,然后将融合后的特征传递给DRL智能体。DRL智能体根据这些特征生成夹爪的控制指令。整个系统通过强化学习进行端到端训练,目标是最大化抓取成功率。
关键创新:最重要的技术创新点在于跨模态注意力模块的设计。该模块能够学习不同模态之间的相关性,并根据当前状态动态地调整各个模态的权重。这使得模型能够更好地利用视觉和触觉数据的互补信息,从而提高抓取性能。与传统的早期或晚期融合方法相比,跨模态注意力能够更灵活地处理不同模态之间的差异。
关键设计:论文使用了一种自监督的方式来训练跨模态注意力模块,即利用RL agent的loss function来指导注意力权重的学习。具体来说,注意力模块的目标是最小化RL agent的loss,从而使得模型能够学习到对抓取任务更有用的特征表示。此外,论文还探索了不同的网络结构和超参数设置,以优化模型的性能。
🖼️ 关键图片
📊 实验亮点
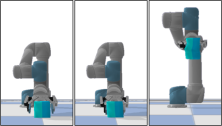
实验结果表明,所提出的跨模态注意力方法在不同环境中(包括未见过的机器人运动和物体)均优于其他早期和晚期数据融合方法。具体性能数据未知,但摘要强调了该方法在不同场景下的泛化能力和优越性,表明其在软体抓取任务中具有显著优势。
🎯 应用场景
该研究成果可应用于柔性物体的自动化抓取和操作,例如食品加工、医疗器械组装、服装制造等领域。通过提升机器人对软体物体的操作能力,可以提高生产效率、降低人工成本,并减少因人为操作造成的损坏。未来,该技术有望扩展到更复杂的机器人操作任务中,例如软体机器人的控制和人机协作。
📄 摘要(原文)
We consider the problem of grasping deformable objects with soft shells using a robotic gripper. Such objects have a center-of-mass that changes dynamically and are fragile so prone to burst. Thus, it is difficult for robots to generate appropriate control inputs not to drop or break the object while performing manipulation tasks. Multi-modal sensing data could help understand the grasping state through global information (e.g., shapes, pose) from visual data and local information around the contact (e.g., pressure) from tactile data. Although they have complementary information that can be beneficial to use together, fusing them is difficult owing to their different properties. We propose a method based on deep reinforcement learning (DRL) that generates control inputs of a simple gripper from visuo-tactile sensing information. Our method employs a cross-modal attention module in the encoder network and trains it in a self-supervised manner using the loss function of the RL agent. With the multi-modal fusion, the proposed method can learn the representation for the DRL agent from the visuo-tactile sensory data. The experimental result shows that cross-modal attention is effective to outperform other early and late data fusion methods across different environments including unseen robot motions and objects.