Towards Task-Oriented Flying: Framework, Infrastructure, and Principles
作者: Kangyao Huang, Hao Wang, Jingyu Chen, Jintao Chen, Yu Luo, Di Guo, Xiangkui Zhang, Xiangyang Ji, Huaping Liu
分类: cs.RO, cs.AI, cs.CV, cs.LG
发布日期: 2025-04-21 (更新: 2025-12-09)
💡 一句话要点
提出面向任务的四旋翼飞行框架,促进学习型控制在复杂环境中的部署。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 四旋翼飞行 深度强化学习 端到端控制 任务导向 Sim-to-Real 自主飞行 机器人学习
📋 核心要点
- 现有方法缺乏系统设计指南和统一基础设施,难以支持可复现的训练和真实环境部署。
- 提出面向任务的框架,整合复杂任务规范的设计原则,揭示模拟、训练和部署的相互依赖。
- 构建软硬件平台和开源固件,支持全栈学习流程,实验验证了鲁棒性和sim-to-real泛化能力。
📝 摘要(中文)
在非结构化环境中部署机器人学习方法到无人机上仍然充满挑战和前景。尽管深度强化学习(DRL)的最新进展已经实现了端到端的飞行控制,但该领域仍然缺乏系统的设计指南和统一的基础设施来支持可复现的训练和实际部署。本文提出了一个面向任务的四旋翼端到端DRL框架,该框架集成了复杂任务规范的设计原则,并揭示了模拟任务定义、训练设计原则和物理部署之间的相互依赖关系。我们的框架包括软件基础设施、硬件平台和开源固件,以支持全栈学习基础设施和工作流程。大量的实验结果表明,在真实世界的干扰下,该框架具有鲁棒的飞行能力和从仿真到真实的泛化能力。通过降低在无人机上部署基于学习的控制器的门槛,我们的工作为在动态和非结构化环境中推进自主飞行奠定了实践基础。
🔬 方法详解
问题定义:论文旨在解决在复杂、非结构化环境中,如何高效、可靠地训练和部署基于深度强化学习的四旋翼飞行控制策略的问题。现有方法通常缺乏系统性的设计原则和统一的基础设施,导致训练过程难以复现,且在真实环境中泛化能力较差,难以应对真实世界的干扰。
核心思路:论文的核心思路是构建一个面向任务的端到端深度强化学习框架,该框架强调任务定义的明确性、训练过程的可控性以及部署的便捷性。通过将任务分解为可学习的子任务,并设计相应的奖励函数,引导智能体学习到期望的行为。同时,框架提供统一的软件和硬件平台,降低了研究人员的入门门槛。
技术框架:该框架包含三个主要组成部分:1) 软件基础设施,提供模拟环境、训练算法和评估工具;2) 硬件平台,包括四旋翼飞行器和传感器;3) 开源固件,用于将训练好的策略部署到实际飞行器上。整个流程包括任务定义、环境建模、策略训练、仿真验证和真实部署等环节。
关键创新:该论文的关键创新在于提出了一个完整的、面向任务的四旋翼飞行学习框架,并强调了任务定义、训练设计和物理部署之间的相互依赖关系。与以往的研究相比,该框架更加注重系统性和可复现性,并提供了一套完整的工具链,降低了学习型控制器的部署难度。
关键设计:在任务定义方面,论文提出了一套复杂任务规范的设计原则,例如将复杂任务分解为多个子任务,并为每个子任务设计相应的奖励函数。在训练方面,采用了深度强化学习算法,并针对四旋翼飞行器的特点进行了优化。在网络结构方面,使用了卷积神经网络和循环神经网络,以提取图像特征和处理时序信息。具体的参数设置和损失函数等细节在论文中进行了详细描述。
🖼️ 关键图片


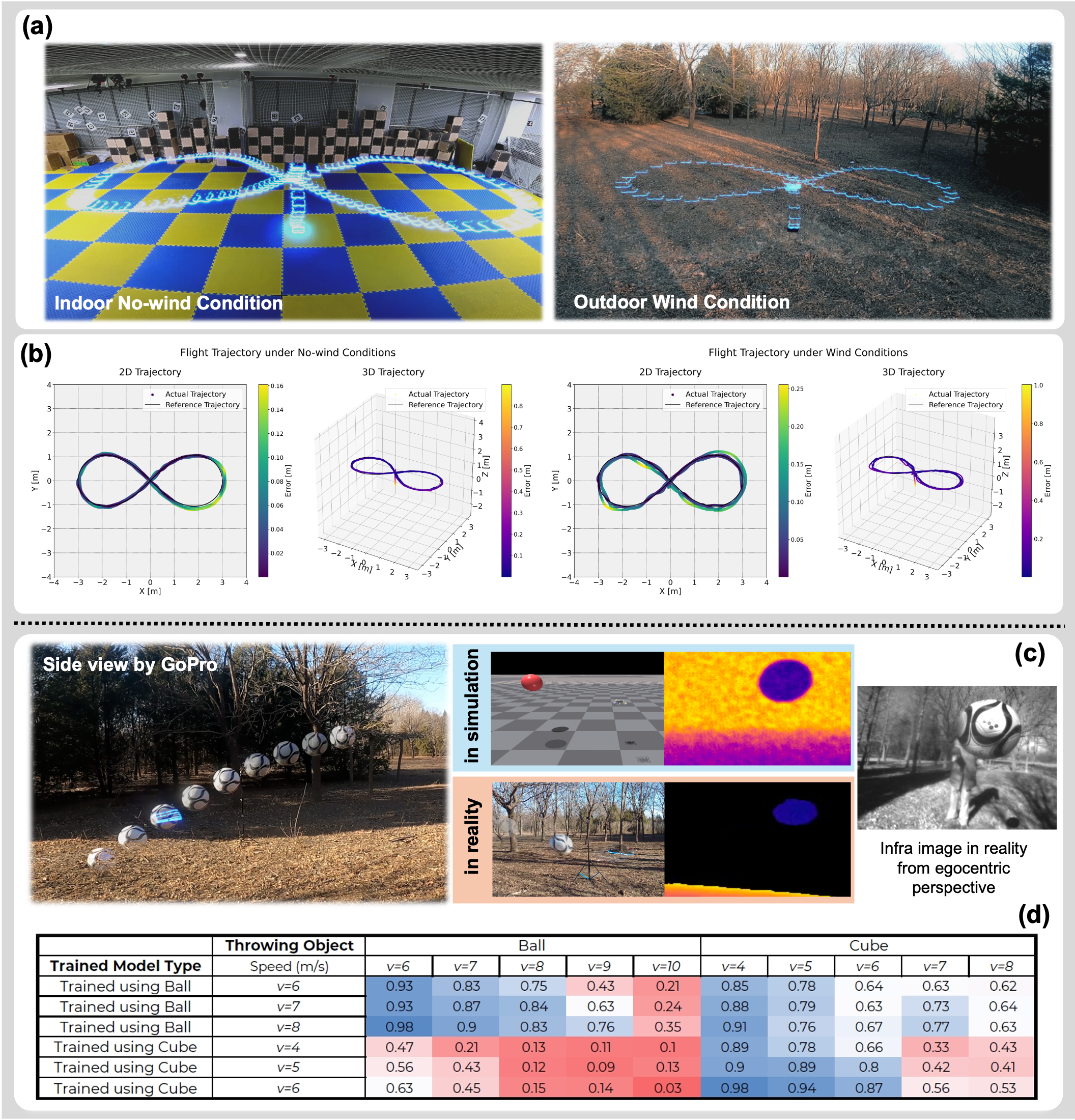
📊 实验亮点
论文通过大量的实验验证了所提出框架的有效性。实验结果表明,在真实世界的干扰下,该框架训练的控制器具有鲁棒的飞行能力和良好的sim-to-real泛化能力。具体的性能数据和对比基线在论文中进行了详细的展示,证明了该框架在复杂环境下的优越性。
🎯 应用场景
该研究成果可应用于物流配送、环境监测、灾害救援、农业植保等领域。通过降低学习型无人机控制器的开发和部署门槛,可以加速无人机在复杂环境中的自主应用,提高作业效率和安全性,并为未来的智能空中交通管理系统奠定基础。
📄 摘要(原文)
Deploying robot learning methods to aerial robots in unstructured environments remains both challenging and promising. While recent advances in deep reinforcement learning (DRL) have enabled end-to-end flight control, the field still lacks systematic design guidelines and a unified infrastructure to support reproducible training and real-world deployment. We present a task-oriented framework for end-to-end DRL in quadrotors that integrates design principles for complex task specification and reveals the interdependencies among simulated task definition, training design principles, and physical deployment. Our framework involves software infrastructure, hardware platforms, and open-source firmware to support a full-stack learning infrastructure and workflow. Extensive empirical results demonstrate robust flight and sim-to-real generalization under real-world disturbances. By reducing the entry barrier for deploying learning-based controllers on aerial robots, our work lays a practical foundation for advancing autonomous flight in dynamic and unstructured environments.