DiffOG: Differentiable Policy Trajectory Optimization with Generalizability
作者: Zhengtong Xu, Zichen Miao, Qiang Qiu, Zhe Zhang, Yu She
分类: cs.RO
发布日期: 2025-04-18 (更新: 2025-11-08)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
DiffOG:通过可泛化可微轨迹优化提升视觉运动策略
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 可微轨迹优化 视觉运动策略 模仿学习 机器人操作 Transformer 约束优化 轨迹平滑
📋 核心要点
- 现有视觉运动策略在处理复杂操作任务时,常因轨迹质量问题导致鲁棒性不足,难以满足实际应用中的约束条件。
- DiffOG提出一种可微策略轨迹优化框架,通过可微优化层优化动作轨迹,使其更平滑并满足约束,同时保持策略性能。
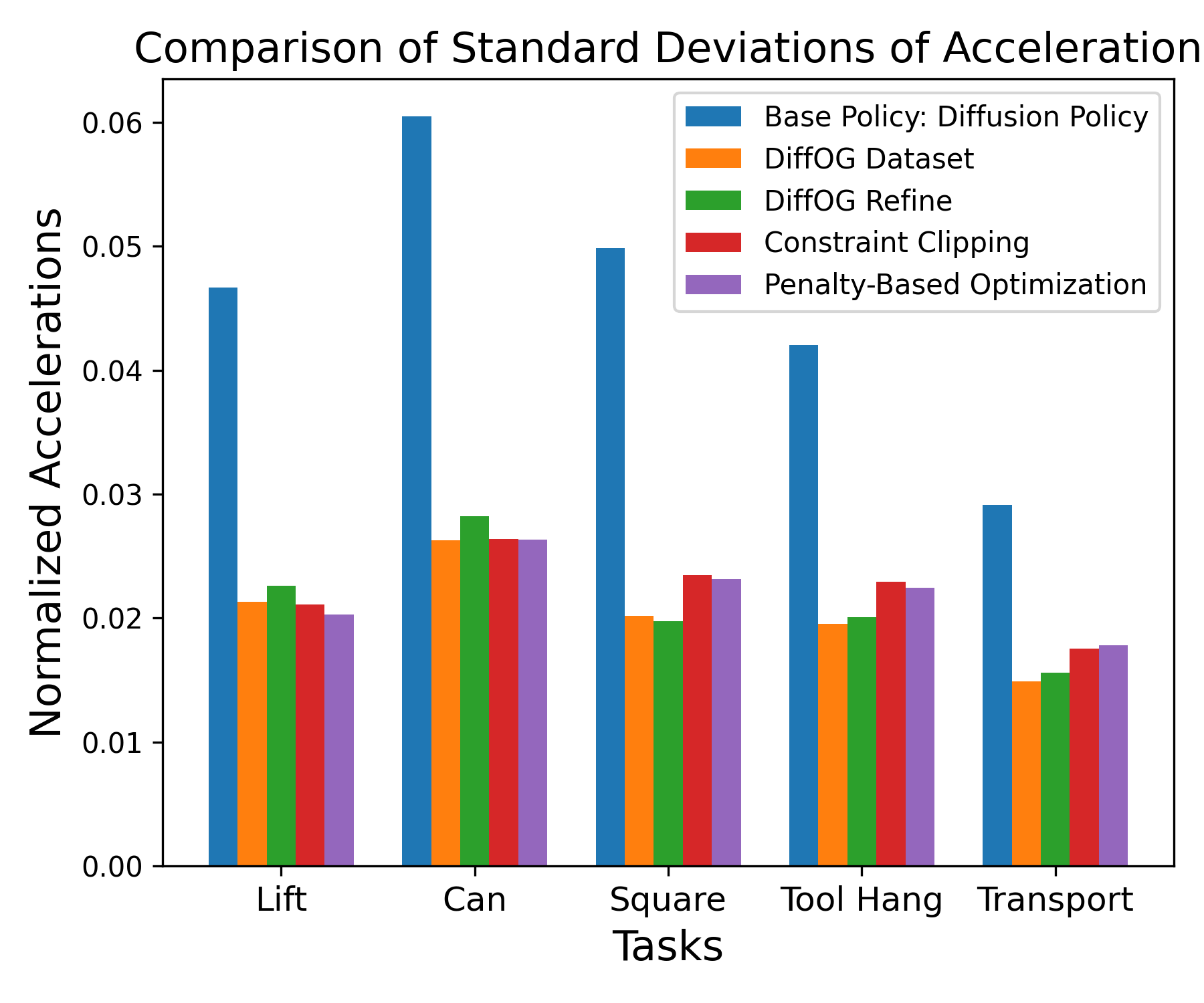
- 实验结果表明,DiffOG在多个模拟和真实世界任务中,显著提升了轨迹质量,优于现有轨迹处理和约束策略方法。
📝 摘要(中文)
基于模仿学习的视觉运动策略在操作任务中表现出色,但与基于模型的方法相比,通常会产生次优的动作轨迹。通过神经网络直接将相机数据映射到动作可能导致运动不稳定,难以满足关键约束,从而影响实际部署中的安全性和鲁棒性。对于需要高鲁棒性或严格遵守约束的任务,确保轨迹质量至关重要。然而,神经网络缺乏可解释性,使得以可控方式生成符合约束的动作具有挑战性。本文介绍了一种具有可泛化性的可微策略轨迹优化框架DiffOG,旨在增强视觉运动策略。通过利用所提出的具有Transformer的可微轨迹优化公式,DiffOG将策略与可泛化的优化层无缝集成。DiffOG优化动作轨迹,使其更平滑、更符合约束,同时保持与原始演示分布的一致性,从而避免策略性能下降。我们在11个模拟任务和2个真实世界任务中评估了DiffOG。结果表明,DiffOG显著提高了视觉运动策略的轨迹质量,同时对策略性能的影响最小,优于诸如贪婪约束裁剪和基于惩罚的轨迹优化等轨迹处理基线。此外,DiffOG实现了优于现有约束视觉运动策略的性能。
🔬 方法详解
问题定义:论文旨在解决基于模仿学习的视觉运动策略在操作任务中产生的动作轨迹次优问题。现有方法直接将相机数据映射到动作,导致轨迹不平滑、难以满足约束,缺乏可解释性,影响了策略的鲁棒性和安全性。
核心思路:论文的核心思路是将策略学习与轨迹优化相结合,利用可微优化层对策略生成的轨迹进行优化,使其更平滑、更符合约束,同时保持与原始策略的一致性。这样既能利用模仿学习的优势,又能提高轨迹的质量和鲁棒性。
技术框架:DiffOG框架包含两个主要部分:策略网络和可微优化层。策略网络负责根据视觉输入生成初始动作轨迹。可微优化层则利用Transformer结构,对初始轨迹进行优化,使其满足约束条件并更加平滑。整个框架是端到端可训练的,可以同时优化策略网络和优化层。
关键创新:DiffOG的关键创新在于提出了一个可微的轨迹优化层,该优化层可以与策略网络无缝集成,并利用梯度下降进行优化。这种可微优化方法允许框架在优化轨迹的同时,考虑到策略的性能,从而避免了轨迹优化对策略性能的负面影响。
关键设计:DiffOG使用Transformer作为可微优化层的核心结构,Transformer具有强大的序列建模能力,可以有效地捕捉轨迹中的时间依赖关系。损失函数包括轨迹平滑损失、约束损失和策略一致性损失,分别用于优化轨迹的平滑度、满足约束的程度和与原始策略的一致性。具体参数设置和网络结构细节在论文中有详细描述,例如Transformer的层数、头数等。
🖼️ 关键图片


📊 实验亮点
DiffOG在11个模拟任务和2个真实世界任务中进行了评估,实验结果表明,DiffOG显著提高了视觉运动策略的轨迹质量,同时对策略性能的影响最小。与贪婪约束裁剪和基于惩罚的轨迹优化等基线方法相比,DiffOG取得了更好的性能。此外,DiffOG在约束满足方面也优于现有的约束视觉运动策略。
🎯 应用场景
DiffOG具有广泛的应用前景,可应用于机器人操作、自动驾驶、游戏AI等领域。在机器人操作中,可以提高机器人在复杂环境中的操作精度和鲁棒性。在自动驾驶中,可以生成更安全、更平稳的驾驶轨迹。在游戏AI中,可以生成更自然、更智能的角色行为。该研究有助于推动人工智能技术在实际场景中的应用。
📄 摘要(原文)
Imitation learning-based visuomotor policies excel at manipulation tasks but often produce suboptimal action trajectories compared to model-based methods. Directly mapping camera data to actions via neural networks can result in jerky motions and difficulties in meeting critical constraints, compromising safety and robustness in real-world deployment. For tasks that require high robustness or strict adherence to constraints, ensuring trajectory quality is crucial. However, the lack of interpretability in neural networks makes it challenging to generate constraint-compliant actions in a controlled manner. This paper introduces differentiable policy trajectory optimization with generalizability (DiffOG), a learning-based trajectory optimization framework designed to enhance visuomotor policies. By leveraging the proposed differentiable formulation of trajectory optimization with transformer, DiffOG seamlessly integrates policies with a generalizable optimization layer. DiffOG refines action trajectories to be smoother and more constraint-compliant while maintaining alignment with the original demonstration distribution, thus avoiding degradation in policy performance. We evaluated DiffOG across 11 simulated tasks and 2 real-world tasks. The results demonstrate that DiffOG significantly enhances the trajectory quality of visuomotor policies while having minimal impact on policy performance, outperforming trajectory processing baselines such as greedy constraint clipping and penalty-based trajectory optimization. Furthermore, DiffOG achieves superior performance compared to existing constrained visuomotor policy. For more details, please visit the project website: https://zhengtongxu.github.io/diffog-website/.