Crossing the Human-Robot Embodiment Gap with Sim-to-Real RL using One Human Demonstration
作者: Tyler Ga Wei Lum, Olivia Y. Lee, C. Karen Liu, Jeannette Bohg
分类: cs.RO, cs.AI
发布日期: 2025-04-17 (更新: 2025-08-16)
💡 一句话要点
提出Human2Sim2Robot框架,仅用单人演示视频实现机器人灵巧操作的Sim-to-Real强化学习。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱五:交互与反应 (Interaction & Reaction)
关键词: 机器人灵巧操作 Sim-to-Real 强化学习 单样本学习 人机协作 物体姿态估计 模仿学习
📋 核心要点
- 机器人灵巧操作技能学习依赖大量演示数据,使用可穿戴设备或遥操作成本高,难以扩展。
- Human2Sim2Robot框架利用单人RGB-D视频,通过模拟环境中的强化学习弥合人机形态差异。
- 该方法在单人演示条件下,显著优于目标感知回放和模仿学习,无需任务特定奖励调整。
📝 摘要(中文)
本文提出了一种名为Human2Sim2Robot的real-to-sim-to-real框架,该框架仅使用一段人类演示任务的RGB-D视频来训练灵巧操作策略。由于获取大量可穿戴设备或遥操作的机器人演示数据成本高昂,因此本文利用强化学习(RL)在模拟环境中弥合人机之间的差异,无需依赖可穿戴设备、遥操作或大规模数据收集。从视频中,我们提取:(1) 物体姿态轨迹,以定义一个以物体为中心、与具体形态无关的奖励;(2) 预操作手部姿态,以初始化和指导RL训练期间的探索。这些组件使得无需任何特定于任务的奖励调整即可实现有效的策略学习。在单人演示的条件下,Human2Sim2Robot在抓取、非抓取操作和多步骤任务上的性能优于目标感知回放超过55%,优于模仿学习超过68%。
🔬 方法详解
问题定义:现有机器人灵巧操作学习方法需要大量人工示教数据,例如通过可穿戴设备或遥操作获取,这限制了其可扩展性。直接利用人类操作视频进行学习面临人机形态差异以及缺乏显式动作标签的挑战。
核心思路:Human2Sim2Robot的核心在于利用单个人类操作视频,通过模拟环境中的强化学习,将人类的技能迁移到机器人上。该方法避免了直接模仿学习中人机形态差异带来的问题,并减少了对大量人工标注数据的依赖。
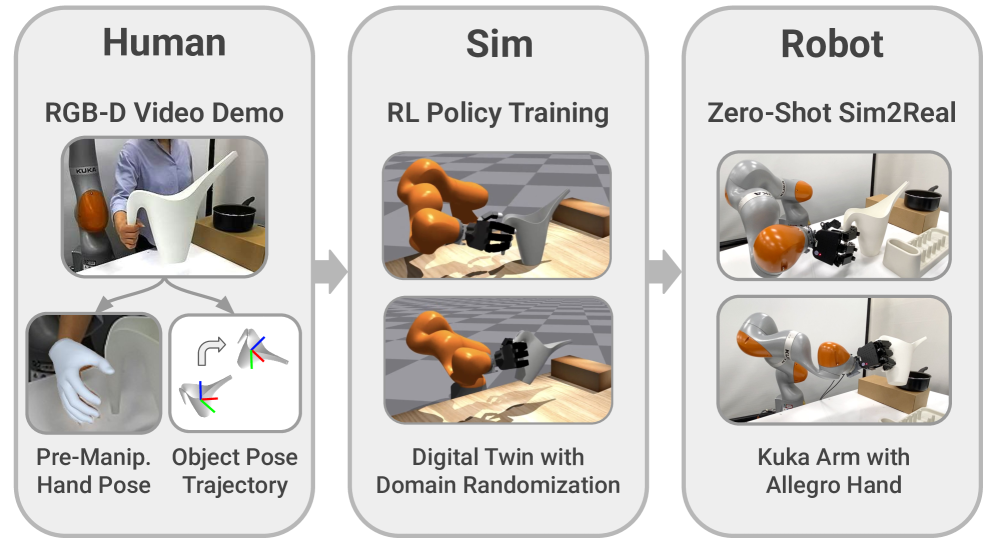
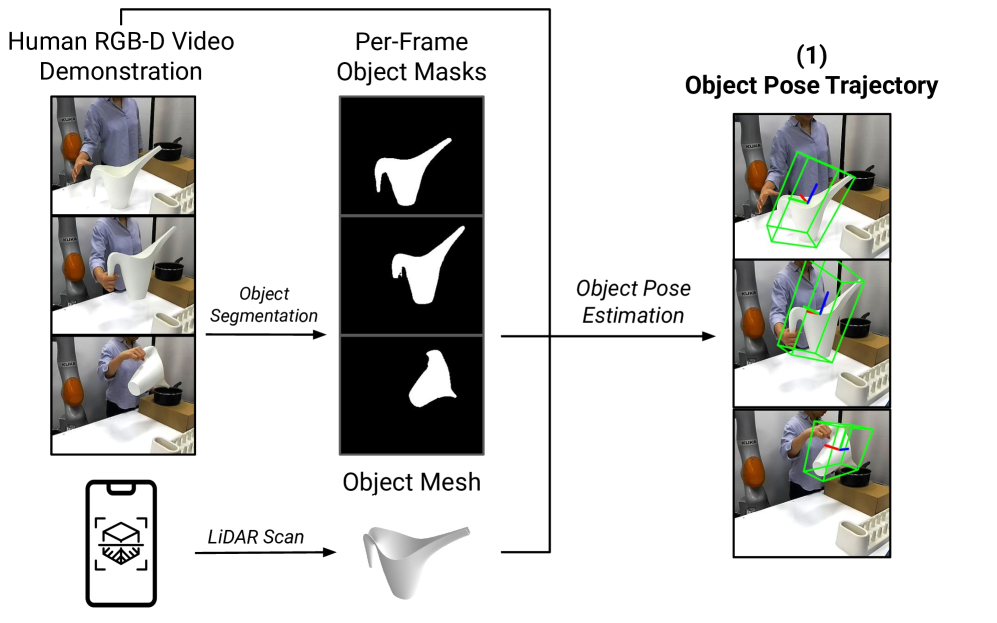
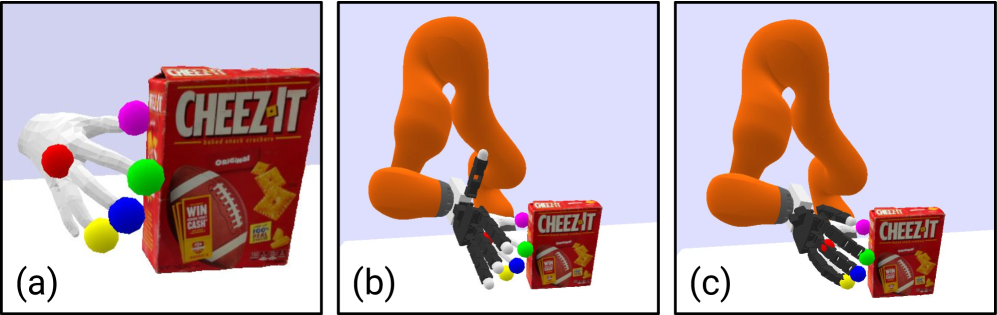
技术框架:Human2Sim2Robot框架包含以下几个主要阶段:1) 从单个人类操作视频中提取物体姿态轨迹和预操作手部姿态。2) 基于物体姿态轨迹定义与具体形态无关的奖励函数,引导强化学习过程。3) 使用提取的预操作手部姿态初始化和指导强化学习训练期间的探索,加速学习过程。4) 在模拟环境中训练得到的策略,通过Sim-to-Real迁移到真实机器人上。
关键创新:该方法最重要的创新点在于利用单人演示视频,结合物体中心奖励和预操作手部姿态引导,实现了高效的Sim-to-Real强化学习,从而克服了人机形态差异和数据稀缺的问题。与传统方法相比,该方法无需人工设计奖励函数,也无需大量人工示教数据。
关键设计:该方法的关键设计包括:1) 使用RGB-D视频提取物体姿态轨迹,作为强化学习的奖励信号。2) 利用预操作手部姿态初始化机器人状态,并引导探索,加速学习过程。3) 采用合适的强化学习算法,例如PPO等,在模拟环境中训练机器人策略。具体参数设置和网络结构的选择取决于具体的任务和机器人平台。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在单人演示的条件下,Human2Sim2Robot在抓取、非抓取操作和多步骤任务上的性能显著优于其他基线方法。具体而言,Human2Sim2Robot的性能优于目标感知回放超过55%,优于模仿学习超过68%。这些结果表明,该方法能够有效地利用单人演示视频学习灵巧操作策略,并成功地将策略迁移到真实机器人上。
🎯 应用场景
该研究成果可应用于各种需要灵巧操作的机器人应用场景,例如:家庭服务机器人、工业自动化机器人、医疗辅助机器人等。通过降低机器人学习灵巧操作技能的数据需求,可以加速机器人在复杂环境中的部署和应用,提高机器人的智能化水平和服务能力。未来,该方法可以扩展到更复杂的任务和环境,实现更高级的机器人自主操作能力。
📄 摘要(原文)
Teaching robots dexterous manipulation skills often requires collecting hundreds of demonstrations using wearables or teleoperation, a process that is challenging to scale. Videos of human-object interactions are easier to collect and scale, but leveraging them directly for robot learning is difficult due to the lack of explicit action labels and human-robot embodiment differences. We propose Human2Sim2Robot, a novel real-to-sim-to-real framework for training dexterous manipulation policies using only one RGB-D video of a human demonstrating a task. Our method utilizes reinforcement learning (RL) in simulation to cross the embodiment gap without relying on wearables, teleoperation, or large-scale data collection. From the video, we extract: (1) the object pose trajectory to define an object-centric, embodiment-agnostic reward, and (2) the pre-manipulation hand pose to initialize and guide exploration during RL training. These components enable effective policy learning without any task-specific reward tuning. In the single human demo regime, Human2Sim2Robot outperforms object-aware replay by over 55% and imitation learning by over 68% on grasping, non-prehensile manipulation, and multi-step tasks. Website: https://human2sim2robot.github.io