Efficient Task-specific Conditional Diffusion Policies: Shortcut Model Acceleration and SO(3) Optimization
作者: Haiyong Yu, Yanqiong Jin, Yonghao He, Wei Sui
分类: cs.RO
发布日期: 2025-04-14
备注: Accepted to CVPR 2025 Workshop on 2nd MEIS
💡 一句话要点
提出基于捷径模型加速和SO(3)优化的高效任务特定条件扩散策略
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散策略 模仿学习 机器人控制 捷径连接 SO(3)流形
📋 核心要点
- 传统扩散策略依赖迭代去噪,推理效率低,响应慢,难以满足实时机器人控制需求。
- 提出无分类器捷径扩散策略(CF-SDP),结合无分类器指导和捷径加速,提升推理速度。
- 将扩散模型扩展到SO(3)流形,优化旋转估计,在仿真和真实场景中验证了方法的有效性。
📝 摘要(中文)
本文提出了一种用于具身智能的动作策略生成方法,即无分类器捷径扩散策略(CF-SDP)。该方法结合了无分类器指导和基于捷径的加速,实现了高效的任务特定动作生成,并显著提高了推理速度。此外,本文还将扩散模型扩展到SO(3)流形,在切线空间中定义了具有各向同性高斯分布的前向和反向过程,确保了稳定和准确的旋转估计,从而增强了基于扩散的控制效果。实验结果表明,与基于DDIM的扩散策略相比,该方法在扩散推理中实现了近5倍的加速,同时保持了任务性能。在RoboTwin仿真平台和真实场景中的评估也证明了该方法的优越性。
🔬 方法详解
问题定义:现有基于扩散策略的模仿学习方法,在具身智能领域展现出强大的动作策略生成能力。然而,这些方法通常依赖于迭代去噪过程,导致推理效率低下,响应时间过长,难以满足实时机器人控制等应用场景的需求。因此,如何加速扩散模型的推理过程,同时保持其性能,是本文要解决的关键问题。
核心思路:本文的核心思路是通过引入捷径连接(Shortcut)来加速扩散模型的推理过程。类似于残差网络,捷径连接允许模型直接利用浅层特征,从而减少了对深层网络迭代去噪的依赖。此外,本文还结合了无分类器指导,进一步提升了模型的性能和泛化能力。对于旋转动作的建模,则将扩散过程定义在SO(3)流形的切空间上,以保证旋转表示的有效性和稳定性。
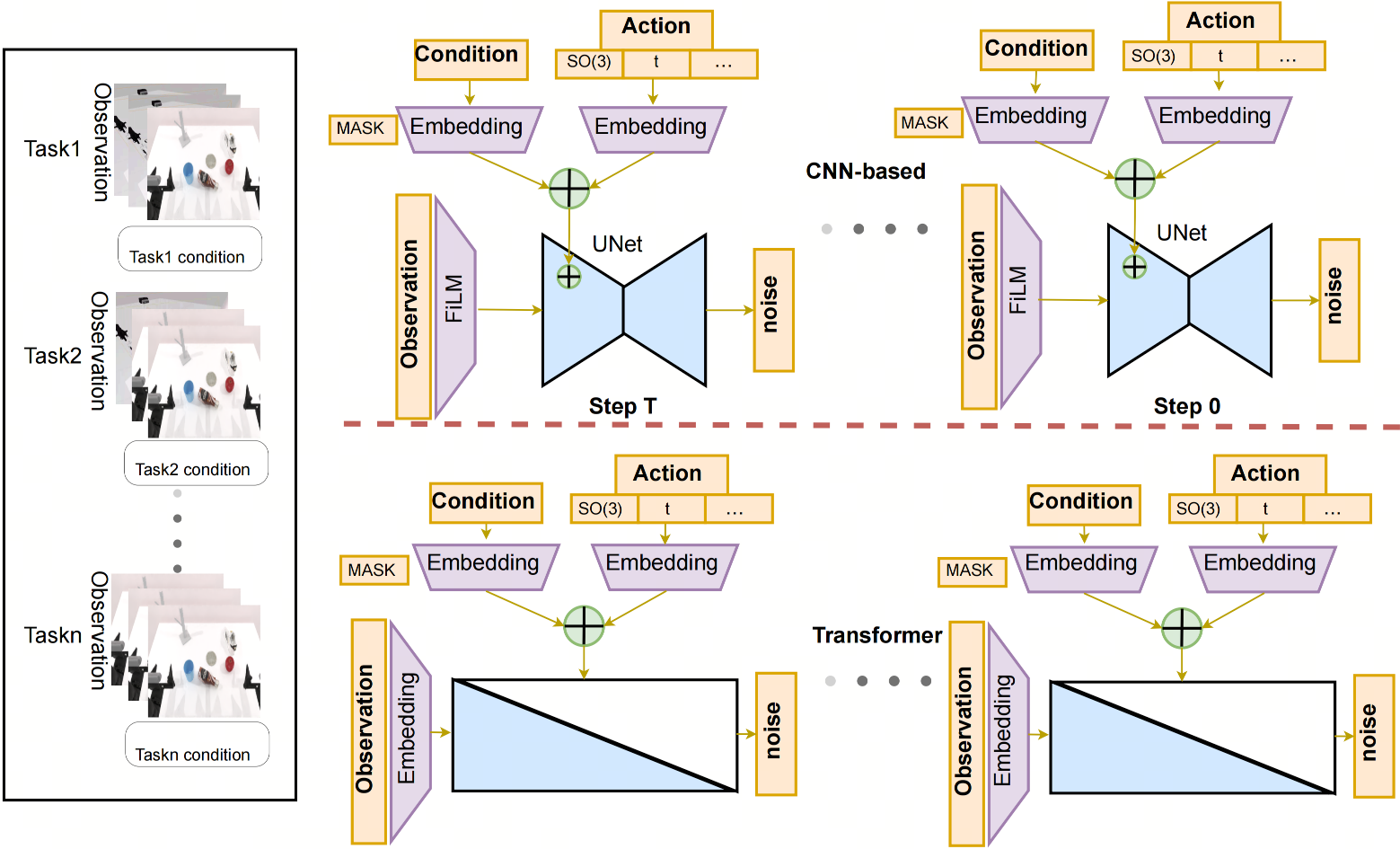
技术框架:CF-SDP方法主要包含以下几个关键模块:1) 扩散模型:采用标准的扩散模型框架,学习从噪声到动作的映射关系。2) 捷径连接:在扩散模型的不同层之间添加捷径连接,允许信息快速传递。3) 无分类器指导:利用无分类器指导来提升模型的性能和泛化能力。4) SO(3)优化:将扩散过程定义在SO(3)流形的切空间上,用于优化旋转动作的建模。整体流程为:首先,利用专家数据训练一个条件扩散模型;然后,在推理阶段,通过捷径连接和无分类器指导加速推理过程,生成动作策略。
关键创新:本文最重要的技术创新点在于将捷径连接引入到扩散策略中,从而实现了推理速度的大幅提升。与传统的迭代去噪方法相比,捷径连接允许模型直接利用浅层特征,减少了对深层网络迭代的依赖,从而显著降低了计算复杂度。此外,将扩散模型扩展到SO(3)流形,也保证了旋转动作建模的有效性和稳定性。
关键设计:在网络结构方面,本文采用了U-Net作为扩散模型的主体结构,并在不同层之间添加了捷径连接。在损失函数方面,采用了标准的扩散模型损失函数,并结合了无分类器指导的损失函数。在SO(3)优化方面,采用了李代数表示旋转,并在切空间上定义了扩散过程。具体的参数设置和超参数选择,需要在实际应用中进行调整和优化。
🖼️ 关键图片

📊 实验亮点
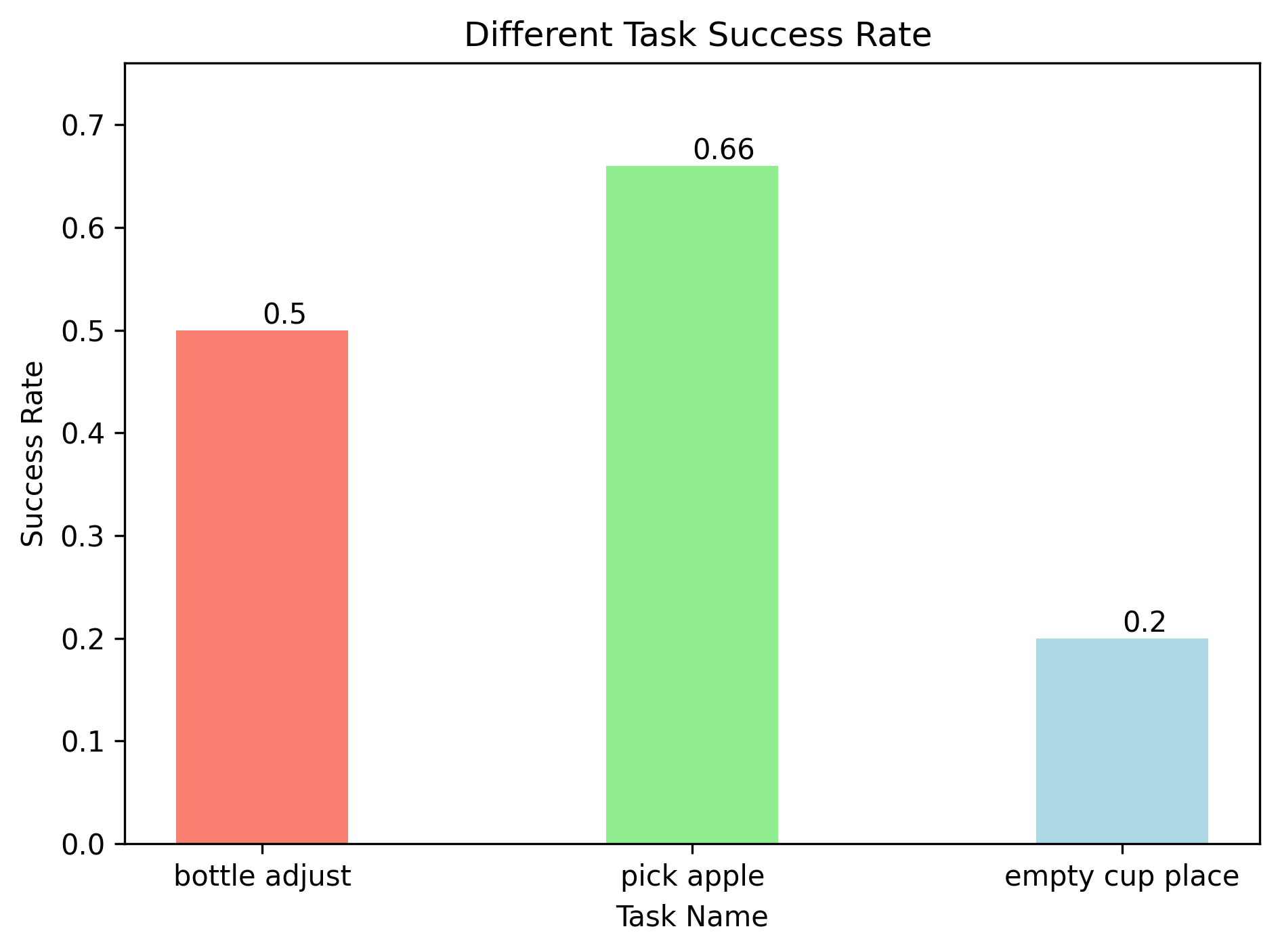
实验结果表明,CF-SDP方法在扩散推理速度上实现了近5倍的加速,同时保持了与DDIM-based Diffusion Policy相当的任务性能。在RoboTwin仿真平台和真实场景中的评估也证明了该方法的优越性。例如,在某个具体的机器人控制任务中,CF-SDP方法可以将响应时间从数百毫秒降低到数十毫秒,从而显著提升了机器人的控制精度和稳定性。
🎯 应用场景
该研究成果可广泛应用于机器人控制、自动驾驶、虚拟现实等领域。通过加速扩散模型的推理过程,可以实现更快速、更实时的动作策略生成,从而提升机器人的自主性和智能化水平。例如,可以应用于复杂环境下的机器人导航、物体抓取、人机协作等任务,具有重要的实际应用价值和广阔的发展前景。
📄 摘要(原文)
Imitation learning, particularly Diffusion Policies based methods, has recently gained significant traction in embodied AI as a powerful approach to action policy generation. These models efficiently generate action policies by learning to predict noise. However, conventional Diffusion Policy methods rely on iterative denoising, leading to inefficient inference and slow response times, which hinder real-time robot control. To address these limitations, we propose a Classifier-Free Shortcut Diffusion Policy (CF-SDP) that integrates classifier-free guidance with shortcut-based acceleration, enabling efficient task-specific action generation while significantly improving inference speed. Furthermore, we extend diffusion modeling to the SO(3) manifold in shortcut model, defining the forward and reverse processes in its tangent space with an isotropic Gaussian distribution. This ensures stable and accurate rotational estimation, enhancing the effectiveness of diffusion-based control. Our approach achieves nearly 5x acceleration in diffusion inference compared to DDIM-based Diffusion Policy while maintaining task performance. Evaluations both on the RoboTwin simulation platform and real-world scenarios across various tasks demonstrate the superiority of our method.