PPF: Pre-training and Preservative Fine-tuning of Humanoid Locomotion via Model-Assumption-based Regularization
作者: Hyunyoung Jung, Zhaoyuan Gu, Ye Zhao, Hae-Won Park, Sehoon Ha
分类: cs.RO
发布日期: 2025-04-14 (更新: 2025-09-02)
期刊: IEEE Robotics and Automation Letters ( Volume: 10, Issue: 11, November 2025)
💡 一句话要点
提出基于模型假设正则化的预训练与保持性微调方法,提升人形机器人复杂地形运动能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人形机器人 运动控制 强化学习 预训练 微调 模型假设 正则化 复杂地形
📋 核心要点
- 人形机器人运动控制面临高维度动力学和复杂环境适应的挑战,现有方法难以兼顾复杂地形和高速度。
- 该论文提出基于模型假设的正则化方法,在强化学习微调过程中,有选择性地对策略进行约束,避免灾难性遗忘。
- 实验结果表明,该方法使人形机器人能够在复杂地形上实现1.5m/s的前进速度,验证了其有效性和鲁棒性。
📝 摘要(中文)
本文提出了一种新颖的学习框架,用于有效训练人形机器人运动策略。该框架通过模仿基于模型的控制器的行为进行预训练,并扩展其能力以处理更复杂的运动任务,例如更具挑战性的地形和更高的速度指令。该框架包含三个关键组成部分:通过模仿基于模型的控制器进行预训练,通过强化学习进行微调,以及在微调期间进行基于模型假设的正则化(MAR)。特别地,MAR仅在模型假设成立的状态下将策略与基于模型的控制器的动作对齐,以防止灾难性遗忘。通过全面的仿真测试和全尺寸人形机器人Digit的硬件实验,验证了所提出框架的有效性,实现了1.5米/秒的前进速度,并在包括湿滑、倾斜、不平和沙地等多种地形上实现了稳健的运动。
🔬 方法详解
问题定义:人形机器人运动控制需要应对复杂动力学和多变环境,传统方法难以在复杂地形和高速度下保持稳定性和适应性。现有基于模型的方法虽然在特定条件下表现良好,但在复杂环境中模型假设容易失效,导致性能下降。强化学习方法虽然可以学习到复杂的策略,但训练难度大,容易出现灾难性遗忘,且难以保证安全性。
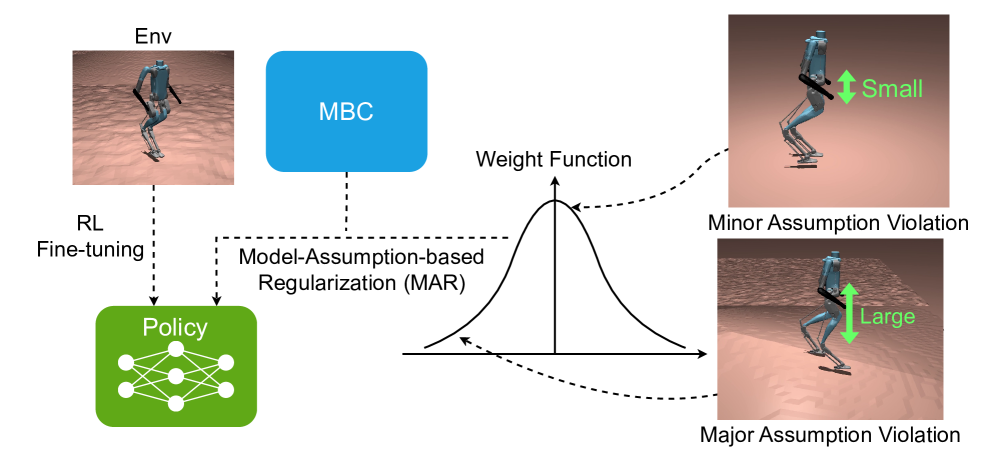
核心思路:该论文的核心思路是结合基于模型控制器的优势和强化学习的泛化能力,通过预训练和微调的方式,使机器人能够模仿模型控制器的行为,并在复杂环境中进行适应。关键在于引入基于模型假设的正则化(MAR),在微调过程中,仅在模型假设成立的状态下,将强化学习策略与模型控制器的动作对齐,从而避免灾难性遗忘,并提高策略的鲁棒性。
技术框架:整体框架包含三个阶段:1) 预训练阶段:通过模仿学习,使用基于模型的控制器生成的数据来初始化强化学习策略。2) 微调阶段:使用强化学习算法(例如PPO)对策略进行微调,使其能够在更复杂的环境中工作。3) 正则化阶段:在微调过程中,引入基于模型假设的正则化项,该正则化项仅在模型假设成立的状态下起作用,促使强化学习策略与模型控制器的动作保持一致。
关键创新:该论文的关键创新在于提出了基于模型假设的正则化(MAR)方法。与传统的正则化方法不同,MAR不是无差别地对所有状态进行约束,而是根据模型假设的有效性,有选择性地进行约束。这种方法可以有效地防止灾难性遗忘,并提高策略的鲁棒性。此外,将预训练、微调和正则化三个阶段有机结合,形成了一个完整的学习框架。
关键设计:MAR的具体实现方式是,首先定义一个模型假设有效性的指标,例如模型预测误差。然后,根据该指标,计算一个正则化权重,该权重在模型假设成立时接近1,在模型假设失效时接近0。最后,将该权重乘以一个正则化项,该正则化项衡量强化学习策略与模型控制器的动作之间的差异。正则化项被添加到强化学习的损失函数中,从而引导策略的学习。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法使人形机器人Digit能够在包括湿滑、倾斜、不平和沙地等多种复杂地形上实现稳健的运动,并达到1.5米/秒的前进速度。与没有正则化的强化学习方法相比,该方法在复杂地形上的性能显著提升,证明了基于模型假设的正则化的有效性。仿真和硬件实验结果一致,验证了该方法在实际应用中的可行性。
🎯 应用场景
该研究成果可应用于各种人形机器人运动控制场景,例如灾难救援、物流运输、家庭服务等。通过提升机器人在复杂地形下的运动能力,可以使其更好地完成各种任务,提高工作效率和安全性。此外,该方法还可以推广到其他类型的机器人,例如四足机器人、轮式机器人等。
📄 摘要(原文)
Humanoid locomotion is a challenging task due to its inherent complexity and high-dimensional dynamics, as well as the need to adapt to diverse and unpredictable environments. In this work, we introduce a novel learning framework for effectively training a humanoid locomotion policy that imitates the behavior of a model-based controller while extending its capabilities to handle more complex locomotion tasks, such as more challenging terrain and higher velocity commands. Our framework consists of three key components: pre-training through imitation of the model-based controller, fine-tuning via reinforcement learning, and model-assumption-based regularization (MAR) during fine-tuning. In particular, MAR aligns the policy with actions from the model-based controller only in states where the model assumption holds to prevent catastrophic forgetting. We evaluate the proposed framework through comprehensive simulation tests and hardware experiments on a full-size humanoid robot, Digit, demonstrating a forward speed of 1.5 m/s and robust locomotion across diverse terrains, including slippery, sloped, uneven, and sandy terrains.