Sim-to-Real Transfer in Reinforcement Learning for Maneuver Control of a Variable-Pitch MAV
作者: Zhikun Wang, Shiyu Zhao
分类: cs.RO
发布日期: 2025-04-10
💡 一句话要点
提出一种基于强化学习的VPP MAV控制框架,实现模拟到真实的零样本迁移
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 模拟到真实迁移 变桨距螺旋桨 无人机控制 领域随机化
📋 核心要点
- 现有强化学习方法在MAV控制中存在模拟到真实迁移的难题,尤其是在VPP MAV这种动力学复杂的系统中。
- 该论文提出了一种结合系统辨识、领域随机化和课程学习的强化学习框架,以增强仿真环境的鲁棒性。
- 实验结果表明,该框架能够实现VPP MAV在真实环境中的零样本部署,并成功完成翻转和墙壁回溯等复杂动作。
📝 摘要(中文)
强化学习(RL)算法可以使无人机(MAV)实现高机动性,但将其从仿真转移到实际应用中具有挑战性。变桨距螺旋桨(VPP) MAV具有更高的灵活性,但其复杂的动力学使模拟到真实的转移变得复杂。本文介绍了一种新的RL框架来克服这些挑战,使VPP MAV能够在真实环境中执行高级空中机动。我们的方法包括真实到仿真的转移技术,如系统辨识、领域随机化和课程学习,以创建鲁棒的训练仿真,以及结合级联控制系统和快速响应低级控制器的模拟到真实转移策略,以实现可靠的部署。结果表明,该框架在实现零样本部署方面的有效性,使MAV能够执行复杂的机动,如翻转和墙壁回溯。
🔬 方法详解
问题定义:论文旨在解决变桨距螺旋桨(VPP)无人机(MAV)在强化学习控制中,从仿真环境到真实环境的迁移问题。VPP MAV虽然具有更高的机动性,但其复杂的动力学特性使得传统的强化学习方法难以直接应用于真实世界,存在性能下降甚至失效的风险。现有方法在处理这种复杂动力学系统时,鲁棒性不足,难以适应真实环境中的各种不确定性和噪声。
核心思路:论文的核心思路是通过构建一个鲁棒的仿真环境,并结合有效的迁移策略,使得在仿真环境中训练得到的强化学习策略可以直接部署到真实VPP MAV上,实现零样本迁移。关键在于提高仿真环境的真实度和多样性,以及设计一个能够弥合仿真与真实环境差异的控制架构。
技术框架:整体框架包含以下几个主要模块:1) 系统辨识:用于建立VPP MAV的精确动力学模型,为仿真环境提供基础。2) 领域随机化:通过在仿真环境中引入各种随机参数,如质量、惯性、电机参数等,增加仿真环境的多样性,提高策略的鲁棒性。3) 课程学习:设计一个由易到难的训练课程,逐步引导智能体学习复杂的控制策略。4) 级联控制系统:采用级联控制结构,将高级策略输出的期望状态转化为低级控制器的控制指令,实现精确的姿态控制。5) 低级控制器:设计一个快速响应的低级控制器,用于补偿仿真与真实环境之间的差异。
关键创新:该论文的关键创新在于将真实到仿真的迁移技术(系统辨识、领域随机化、课程学习)与模拟到真实的迁移策略(级联控制系统、快速响应低级控制器)相结合,形成一个完整的强化学习框架,实现了VPP MAV在真实环境中的零样本部署。这种方法有效地解决了复杂动力学系统在强化学习控制中面临的迁移难题。
关键设计:论文中关键的设计包括:领域随机化参数的选择范围,课程学习的难度递增策略,级联控制器的参数整定,以及低级控制器的设计。例如,领域随机化参数的选择需要根据实际系统的物理特性进行调整,以保证仿真环境的合理性。课程学习的难度递增策略需要平衡学习效率和策略的鲁棒性。低级控制器的设计需要考虑系统的动态响应和控制精度。
🖼️ 关键图片

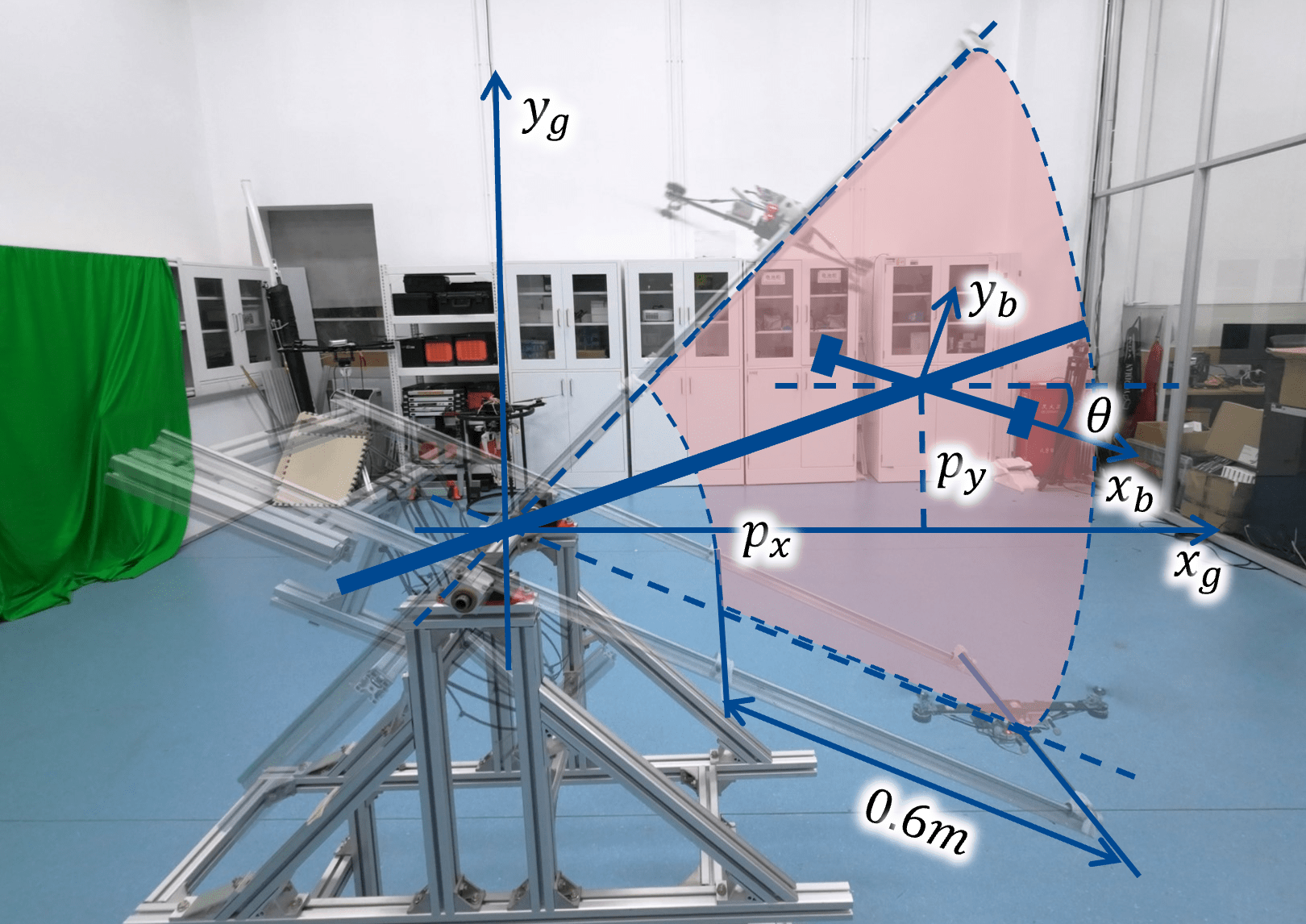

📊 实验亮点
实验结果表明,该框架能够成功实现VPP MAV在真实环境中的零样本部署,并能够完成如翻转和墙壁回溯等复杂机动动作。与传统的PID控制方法相比,该方法能够更好地适应VPP MAV的复杂动力学特性,并具有更强的鲁棒性和适应性。虽然论文中没有给出具体的性能数据,但零样本部署的成功本身就证明了该方法的有效性。
🎯 应用场景
该研究成果可应用于需要高机动性和复杂控制的无人机应用场景,例如:复杂环境下的搜索与救援、精准农业、桥梁检测、以及其他需要快速响应和精确控制的机器人系统。该方法能够降低开发成本,缩短部署时间,并提高系统的鲁棒性和可靠性,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
Reinforcement learning (RL) algorithms can enable high-maneuverability in unmanned aerial vehicles (MAVs), but transferring them from simulation to real-world use is challenging. Variable-pitch propeller (VPP) MAVs offer greater agility, yet their complex dynamics complicate the sim-to-real transfer. This paper introduces a novel RL framework to overcome these challenges, enabling VPP MAVs to perform advanced aerial maneuvers in real-world settings. Our approach includes real-to-sim transfer techniques-such as system identification, domain randomization, and curriculum learning to create robust training simulations and a sim-to-real transfer strategy combining a cascade control system with a fast-response low-level controller for reliable deployment. Results demonstrate the effectiveness of this framework in achieving zero-shot deployment, enabling MAVs to perform complex maneuvers such as flips and wall-backtracking.