RAMBO: RL-Augmented Model-Based Whole-Body Control for Loco-Manipulation
作者: Jin Cheng, Dongho Kang, Gabriele Fadini, Guanya Shi, Stelian Coros
分类: cs.RO
发布日期: 2025-04-09 (更新: 2025-08-05)
备注: Accepted to IEEE Robotics and Automation Letters (RA-L)
💡 一句话要点
RAMBO:强化学习增强的模型预测控制用于腿式机器人灵巧操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 腿式机器人 灵巧操作 模型预测控制 强化学习 全身控制 四足机器人 混合控制
📋 核心要点
- 腿式机器人的灵巧操作需要精确的末端执行器控制和对未建模动态的鲁棒性,现有方法难以兼顾。
- RAMBO融合了基于模型的全身控制和强化学习训练的反馈策略,前者提供精确规划,后者增强鲁棒性。
- 实验表明,RAMBO在多种真实场景下,如推车、平衡物体等,实现了精确操作和鲁棒运动。
📝 摘要(中文)
本文提出了一种混合框架RAMBO,用于解决腿式机器人灵巧操作中的难题。灵巧操作是指在运动的同时协调地与各种物体进行物理交互。由于需要精确的末端执行器控制和对未建模动态的鲁棒性,这对腿式机器人来说仍然是一个重大挑战。RAMBO集成了基于模型的全身控制和通过强化学习训练的反馈策略。基于模型的模块通过求解二次规划生成前馈扭矩,而策略提供反馈校正项以增强鲁棒性。我们在四足机器人上验证了该框架在一系列真实世界的灵巧操作任务中的有效性,例如推购物车、平衡盘子和保持柔软物体,包括四足和双足行走。实验表明,RAMBO能够在实现鲁棒和动态运动的同时,实现精确的操作能力。
🔬 方法详解
问题定义:腿式机器人的灵巧操作需要同时控制机器人的运动和与环境的交互,这需要精确的末端执行器控制和对未建模动态的鲁棒性。现有的基于模型的方法虽然可以进行精确的规划,但容易受到模型不准确的影响。而基于学习的方法虽然具有鲁棒性,但在精确控制交互力方面存在困难。
核心思路:RAMBO的核心思路是将基于模型的控制和强化学习相结合,利用基于模型的控制进行精确的轨迹规划,并使用强化学习训练的策略来提供反馈校正,从而提高系统的鲁棒性。这种混合方法旨在结合两者的优点,克服各自的缺点。
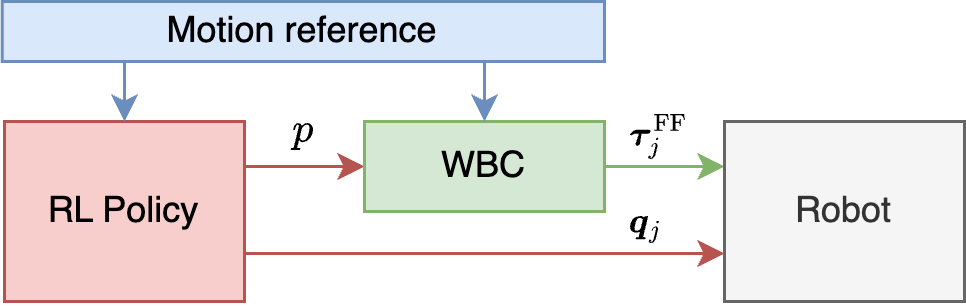
技术框架:RAMBO框架包含两个主要模块:基于模型的全身控制器和强化学习策略。基于模型的控制器通过求解二次规划问题生成前馈扭矩,用于实现期望的运动轨迹和交互力。强化学习策略则根据机器人的状态和环境信息,生成反馈校正项,用于补偿模型误差和未建模的动态。这两个模块共同作用,实现精确和鲁棒的灵巧操作。
关键创新:RAMBO的关键创新在于将基于模型的控制和强化学习策略无缝集成,实现优势互补。传统的基于模型的方法依赖于精确的模型,而RAMBO通过强化学习策略来弥补模型误差,从而提高了系统的鲁棒性。同时,RAMBO利用基于模型的控制来提供精确的轨迹规划,避免了强化学习方法在复杂任务中难以训练的问题。
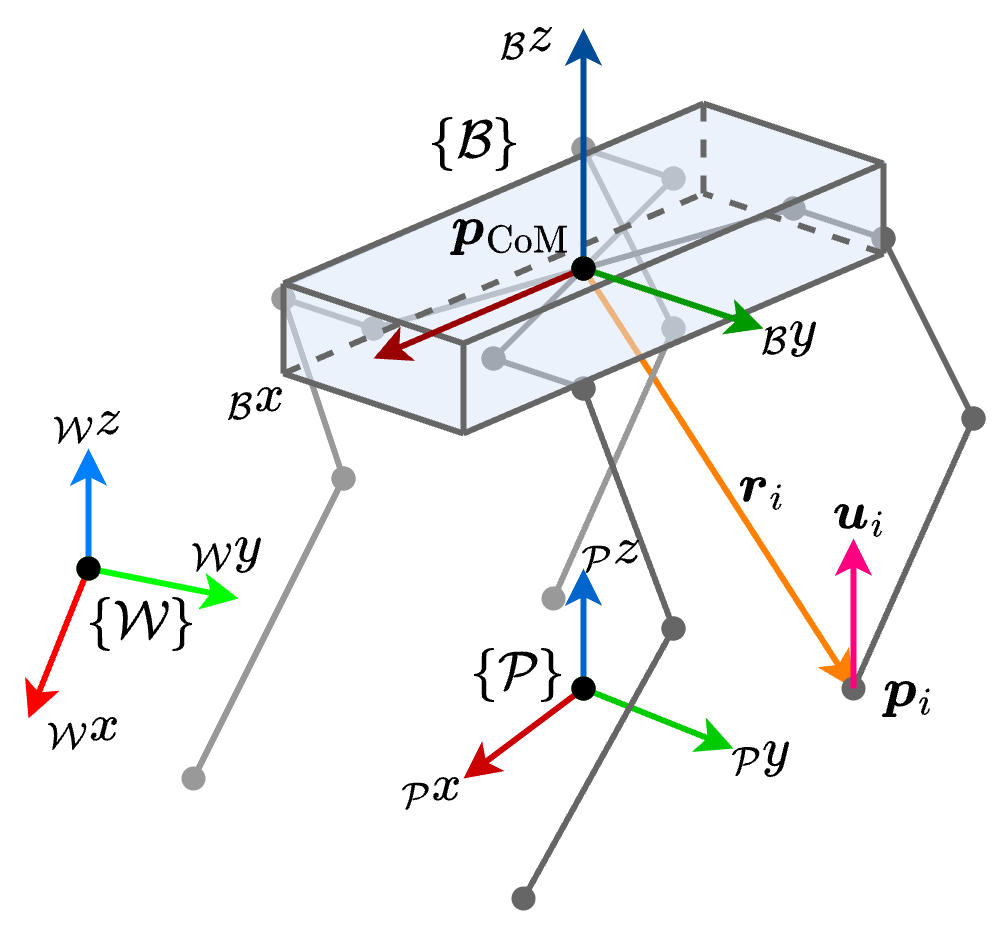
关键设计:基于模型的控制器使用二次规划来优化机器人的关节扭矩,目标是最小化轨迹跟踪误差和控制力矩。强化学习策略使用深度神经网络来近似最优的反馈控制律,网络的输入包括机器人的状态和环境信息,输出是关节扭矩的校正量。损失函数的设计需要平衡轨迹跟踪精度和控制力矩的大小,同时需要考虑机器人的稳定性和安全性。具体的参数设置和网络结构未知。
🖼️ 关键图片

📊 实验亮点
RAMBO在四足机器人上进行了真实世界的灵巧操作任务验证,包括推购物车、平衡盘子和保持柔软物体等。实验结果表明,RAMBO能够在实现鲁棒和动态运动的同时,实现精确的操作能力。具体性能数据和对比基线未知。
🎯 应用场景
RAMBO技术可应用于物流、仓储、家庭服务等领域,使腿式机器人能够在复杂环境中进行物品搬运、组装等任务。该研究有助于提升腿式机器人在非结构化环境中的适应性和操作能力,推动机器人技术在实际场景中的应用。
📄 摘要(原文)
Loco-manipulation, physical interaction of various objects that is concurrently coordinated with locomotion, remains a major challenge for legged robots due to the need for both precise end-effector control and robustness to unmodeled dynamics. While model-based controllers provide precise planning via online optimization, they are limited by model inaccuracies. In contrast, learning-based methods offer robustness, but they struggle with precise modulation of interaction forces. We introduce RAMBO, a hybrid framework that integrates model-based whole-body control within a feedback policy trained with reinforcement learning. The model-based module generates feedforward torques by solving a quadratic program, while the policy provides feedback corrective terms to enhance robustness. We validate our framework on a quadruped robot across a diverse set of real-world loco-manipulation tasks, such as pushing a shopping cart, balancing a plate, and holding soft objects, in both quadrupedal and bipedal walking. Our experiments demonstrate that RAMBO enables precise manipulation capabilities while achieving robust and dynamic locomotion.