MAPLE: Encoding Dexterous Robotic Manipulation Priors Learned From Egocentric Videos
作者: Alexey Gavryushin, Xi Wang, Robert J. S. Malate, Chenyu Yang, Davide Liconti, René Zurbrügg, Robert K. Katzschmann, Marc Pollefeys
分类: cs.RO, cs.CV
发布日期: 2025-04-08 (更新: 2025-12-08)
💡 一句话要点
MAPLE:利用自中心视频学习灵巧机器人操作先验,提升策略学习。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 灵巧操作 机器人学习 自中心视频 操作先验 策略学习
📋 核心要点
- 传统机器人操作方法在处理需要精细控制的灵巧操作任务时存在不足,难以充分利用人类操作的丰富经验。
- MAPLE通过学习自中心视频中的操作先验,预测物体接触点和手部姿势,为机器人策略学习提供更有效的特征。
- 实验表明,MAPLE在模拟和真实机器人环境中均能有效提升灵巧操作性能,尤其是在复杂任务中表现突出。
📝 摘要(中文)
大规模自中心视频数据集捕捉了各种场景下的人类活动,提供了人类与物体交互的丰富而详细的见解,尤其是在需要精细灵巧控制的情况下。这种复杂、灵巧的技能对于许多机器人操作任务至关重要,但传统的机器人操作数据驱动方法往往无法充分解决这些问题。为了弥补这一差距,我们利用从大规模自中心视频数据集学习的操作先验来改进灵巧机器人操作任务的策略学习。我们提出了一种新的灵巧机器人操作方法MAPLE,该方法学习从自中心图像预测物体接触点和接触时刻的详细手部姿势的特征。然后,我们使用学习到的特征来训练下游操作任务的策略。实验结果表明,MAPLE在4个现有的模拟基准以及一套新设计的4个具有挑战性的模拟任务中都有效,这些任务需要精细的物体控制和复杂的灵巧技能。MAPLE的优势在真实世界的实验中使用17自由度灵巧机器人手得到了进一步强调,而同时在模拟和真实世界实验中进行评估在之前的工作中仍然未被充分探索。此外,我们展示了我们的模型在自中心接触点预测任务中的有效性,验证了其在灵巧操作策略学习之外的用途。
🔬 方法详解
问题定义:论文旨在解决机器人灵巧操作中策略学习效率低下的问题。现有方法难以有效利用人类操作的先验知识,尤其是在需要精细控制的复杂任务中,导致学习过程缓慢且泛化能力不足。
核心思路:论文的核心思路是从大规模自中心视频数据中学习人类操作的先验知识,并将其迁移到机器人策略学习中。通过预测物体接触点和手部姿势,为机器人提供更具信息量的状态表示,从而加速策略学习并提高操作精度。
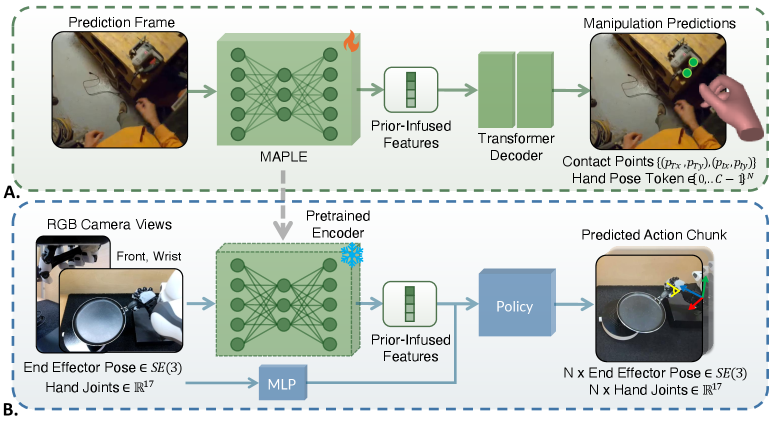
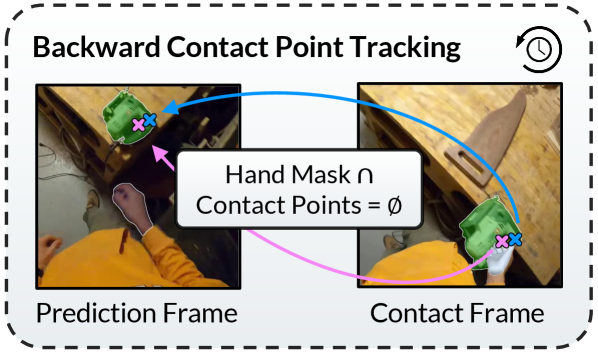
技术框架:MAPLE包含两个主要阶段:1) 先验知识学习阶段:使用自中心视频数据训练一个模型,该模型能够从图像中预测物体接触点和手部姿势。2) 策略学习阶段:利用学习到的特征作为策略网络的输入,训练机器人完成特定的操作任务。整体流程是从人类视频中提取操作知识,然后将其应用于机器人控制。
关键创新:MAPLE的关键创新在于将自中心视频中的操作先验知识有效地融入到机器人策略学习中。与传统的端到端学习方法相比,MAPLE能够利用人类操作的丰富经验,从而提高学习效率和泛化能力。同时,在模拟和真实环境中的同步验证也较为少见。
关键设计:在先验知识学习阶段,使用卷积神经网络提取图像特征,并使用回归损失函数训练模型预测物体接触点和手部姿势。在策略学习阶段,将预测的接触点和手部姿势与机器人状态信息相结合,作为策略网络的输入。具体的网络结构和参数设置根据不同的任务进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MAPLE在多个模拟基准测试中均优于现有方法,尤其是在需要精细控制的复杂任务中,性能提升显著。此外,MAPLE还在真实机器人环境中进行了验证,证明了其在实际应用中的有效性。具体而言,MAPLE在模拟和真实环境中的表现均优于基线方法,证明了其学习到的先验知识具有良好的泛化能力。
🎯 应用场景
MAPLE的研究成果可应用于各种需要灵巧操作的机器人任务,例如:医疗手术机器人、装配线上的工业机器人、家庭服务机器人等。通过学习人类的操作经验,机器人能够更高效、更精确地完成复杂的操作任务,提高生产效率和服务质量。未来,该方法有望进一步扩展到其他类型的机器人和操作任务中。
📄 摘要(原文)
Large-scale egocentric video datasets capture diverse human activities across a wide range of scenarios, offering rich and detailed insights into how humans interact with objects, especially those that require fine-grained dexterous control. Such complex, dexterous skills with precise controls are crucial for many robotic manipulation tasks, yet are often insufficiently addressed by traditional data-driven approaches to robotic manipulation. To address this gap, we leverage manipulation priors learned from large-scale egocentric video datasets to improve policy learning for dexterous robotic manipulation tasks. We present MAPLE, a novel method for dexterous robotic manipulation that learns features to predict object contact points and detailed hand poses at the moment of contact from egocentric images. We then use the learned features to train policies for downstream manipulation tasks. Experimental results demonstrate the effectiveness of MAPLE across 4 existing simulation benchmarks, as well as a newly designed set of 4 challenging simulation tasks requiring fine-grained object control and complex dexterous skills. The benefits of MAPLE are further highlighted in real-world experiments using a 17 DoF dexterous robotic hand, whereas the simultaneous evaluation across both simulation and real-world experiments has remained underexplored in prior work. We additionally showcase the efficacy of our model on an egocentric contact point prediction task, validating its usefulness beyond dexterous manipulation policy learning.