Multimodal Fusion and Vision-Language Models: A Survey for Robot Vision
作者: Xiaofeng Han, Shunpeng Chen, Zenghuang Fu, Zhe Feng, Lue Fan, Dong An, Changwei Wang, Li Guo, Weiliang Meng, Xiaopeng Zhang, Rongtao Xu, Shibiao Xu
分类: cs.RO, cs.CV
发布日期: 2025-04-03 (更新: 2025-10-15)
备注: 27 pages, 11 figures. Accepted to Information Fusion. Final journal version: volume 126 (Part B), February 2026
期刊: Information Fusion, 126 (Part B), February 2026, 103652
DOI: 10.1016/j.inffus.2025.103652
🔗 代码/项目: GITHUB
💡 一句话要点
综述多模态融合与视觉-语言模型在机器人视觉中的应用与进展。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人视觉 多模态融合 视觉-语言模型 语义场景理解 同步定位与地图构建 3D目标检测 导航 操作
📋 核心要点
- 现有机器人视觉方法在处理复杂环境和多源信息融合方面存在不足,限制了其泛化性和鲁棒性。
- 本文系统性地综述了多模态融合和视觉-语言模型在机器人视觉中的应用,并从任务导向的角度进行分类和分析。
- 该综述总结了现有方法的挑战,并提出了未来研究方向,包括自监督学习、空间记忆和伦理对齐等。
📝 摘要(中文)
机器人视觉受益于多模态融合技术和视觉-语言模型(VLMs)的进步。本文从任务导向的角度系统地回顾了多模态融合方法和VLMs在机器人视觉领域的应用和进展。对于语义场景理解任务,我们将融合方法分为编码器-解码器框架、基于注意力的架构和图神经网络。同时,我们还分析了这些融合策略在同步定位与地图构建(SLAM)、3D目标检测、导航和操作等关键任务中的架构特征和实际应用。我们比较了基于大型语言模型(LLMs)的VLMs与传统多模态融合方法的演进路径和适用性。此外,我们还深入分析了常用的数据集,评估了它们在真实机器人场景中的适用性和挑战。在此基础上,我们确定了当前研究中的关键挑战,包括跨模态对齐、高效融合、实时部署和领域自适应。我们提出了未来的方向,如用于鲁棒多模态表示的自监督学习、用于增强空间智能的结构化空间记忆和环境建模,以及对抗鲁棒性和人类反馈机制的集成,以实现符合伦理的系统部署。通过全面的回顾、比较分析和前瞻性讨论,我们为推进机器人视觉中的多模态感知和交互提供了有价值的参考。
🔬 方法详解
问题定义:机器人视觉需要理解复杂环境并进行交互,而单一模态的信息往往不足以提供全面的感知。现有的多模态融合方法在跨模态对齐、计算效率、实时部署和领域自适应方面存在挑战,限制了机器人在真实世界中的应用。此外,如何将大型语言模型的知识融入机器人视觉系统,也是一个亟待解决的问题。
核心思路:本文的核心思路是通过系统性地回顾和分析多模态融合方法和视觉-语言模型在机器人视觉中的应用,总结现有方法的优缺点,并指出未来的研究方向。通过任务导向的分类,可以更好地理解不同方法在不同任务中的适用性。
技术框架:本文的综述框架主要包括以下几个部分:首先,对语义场景理解任务中的多模态融合方法进行分类,包括编码器-解码器框架、基于注意力的架构和图神经网络。其次,分析这些融合策略在SLAM、3D目标检测、导航和操作等关键任务中的应用。然后,比较基于LLMs的VLMs与传统多模态融合方法的演进路径和适用性。最后,分析常用数据集的适用性和挑战,并提出未来的研究方向。
关键创新:本文的创新之处在于:1) 采用任务导向的视角,系统性地回顾了多模态融合和视觉-语言模型在机器人视觉中的应用;2) 深入分析了现有方法的挑战,并提出了未来的研究方向,如自监督学习、空间记忆和伦理对齐;3) 比较了基于LLMs的VLMs与传统多模态融合方法的演进路径和适用性。
关键设计:本文主要关注多模态融合的架构设计,包括编码器-解码器结构、注意力机制和图神经网络。对于VLMs,本文关注其与LLMs的集成方式和知识迁移策略。此外,本文还关注数据集的选择和评估,以及未来研究方向的探索。
🖼️ 关键图片


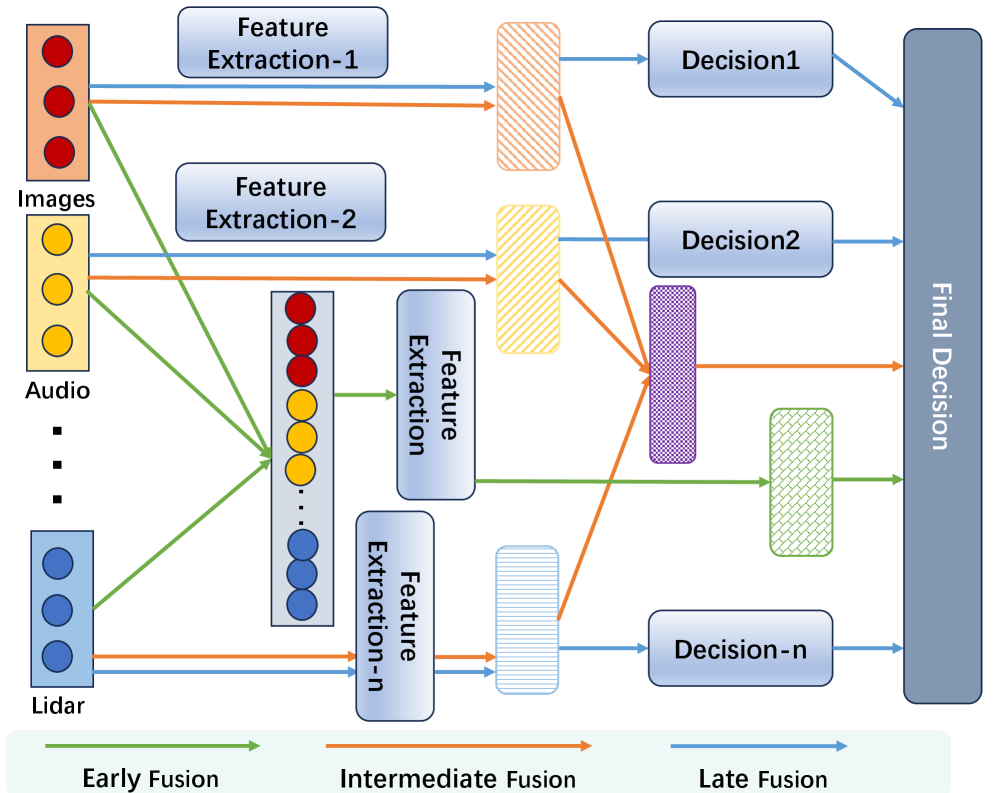
📊 实验亮点
该综述全面回顾了多模态融合和视觉-语言模型在机器人视觉中的应用,并从任务导向的角度进行了分类和分析。它总结了现有方法的挑战,并提出了未来研究方向,包括自监督学习、空间记忆和伦理对齐等。该综述为研究人员提供了一个有价值的参考,有助于推动机器人视觉技术的发展。
🎯 应用场景
该研究成果可应用于各种机器人视觉任务,如自动驾驶、智能制造、家庭服务机器人等。通过提升机器人的感知能力和交互能力,可以使其更好地适应复杂环境,完成各种任务,从而提高生产效率和生活质量。未来的研究方向将进一步推动机器人视觉技术的发展,使其更加智能化和自主化。
📄 摘要(原文)
Robot vision has greatly benefited from advancements in multimodal fusion techniques and vision-language models (VLMs). We adopt a task-oriented perspective to systematically review the applications and advancements of multimodal fusion methods and VLMs in the field of robot vision. For semantic scene understanding tasks, we categorize fusion approaches into encoder-decoder frameworks, attention-based architectures, and graph neural networks. Meanwhile, we also analyze the architectural characteristics and practical implementations of these fusion strategies in key tasks such as simultaneous localization and mapping (SLAM), 3D object detection, navigation, and manipulation. We compare the evolutionary paths and applicability of VLMs based on large language models (LLMs) with traditional multimodal fusion methods.Additionally, we conduct an in-depth analysis of commonly used datasets, evaluating their applicability and challenges in real-world robotic scenarios. Building on this analysis, we identify key challenges in current research, including cross-modal alignment, efficient fusion, real-time deployment, and domain adaptation. We propose future directions such as self-supervised learning for robust multimodal representations, structured spatial memory and environment modeling to enhance spatial intelligence, and the integration of adversarial robustness and human feedback mechanisms to enable ethically aligned system deployment. Through a comprehensive review, comparative analysis, and forward-looking discussion, we provide a valuable reference for advancing multimodal perception and interaction in robotic vision. A comprehensive list of studies in this survey is available at https://github.com/Xiaofeng-Han-Res/MF-RV.