R900: Understanding the Cost-Effectiveness of Random Exploration from 900 Hours of Robotic Data Collection
作者: Shutong Jin, Axel Kaliff, Ruiyu Wang, Muhammad Zahid, Florian T. Pokorny
分类: cs.RO
发布日期: 2025-03-30 (更新: 2025-09-17)
💡 一句话要点
R900:基于900小时机器人数据的随机探索成本效益分析
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 模仿学习 随机探索 自监督学习 数据收集 自动化流程 成本效益分析
📋 核心要点
- 机器人操作中的模仿学习面临数据稀缺的挑战,限制了模型的泛化能力和实际应用。
- 该研究探索随机动作和随机探索视频作为经济高效的数据来源,用于引导数据收集和预训练网络。
- 通过807小时随机动作和71小时随机探索视频的大规模实验,验证了随机探索在双层堆叠任务中的有效性。
📝 摘要(中文)
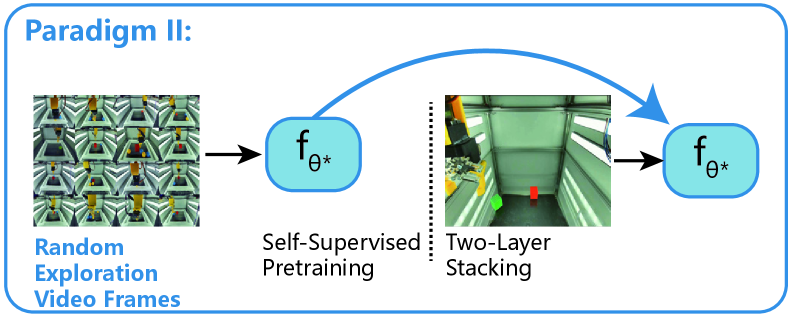
数据稀缺是机器人操作中模仿学习的关键瓶颈。本文关注随机探索数据,即通过自主运动到工作空间中随机采样的位置而产生的动作和视频序列,以研究它们作为一种经济高效的数据来源的潜力。我们的研究遵循两种范式:(a)随机动作,评估其自主引导数据收集策略的可行性;(b)随机探索视频帧,评估其在利用自监督学习目标预训练参数密集型网络中的有效性。为了最大限度地减少人工监督,我们首先开发了一个全自动化的流程,该流程使用基于云的微服务进行实时监控,从而处理episode标记、终止和重置。在此基础上,我们对一个非平凡的双层堆叠任务中真实世界随机探索的成本效益进行了大规模研究,利用了来自807小时随机动作、71小时随机探索视频(128万帧)和1260次策略评估的统计结果。该数据集将公开提供,并且通过云服务提供对具有自动化流程的机器人环境的访问,以供未来研究。
🔬 方法详解
问题定义:机器人操作任务中,模仿学习需要大量高质量数据,而人工标注成本高昂。现有方法难以有效利用低成本的随机探索数据,导致模型训练效率低下,泛化能力不足。
核心思路:利用随机动作和随机探索视频作为数据来源,通过自动化流程进行数据收集和标注,并结合自监督学习方法,从大量无标签数据中提取有用的信息,从而降低数据获取成本,提高模型性能。
技术框架:该研究构建了一个全自动化的数据收集和处理流程。首先,机器人执行随机动作或进行随机探索视频录制。然后,使用基于云的微服务进行实时监控,自动完成episode的标记、终止和重置。收集到的数据用于训练数据收集策略或预训练参数密集型网络。最后,通过策略评估来验证随机探索的有效性。
关键创新:该研究的关键创新在于提出了一个全自动化的随机探索数据收集和处理流程,并验证了其在机器人操作任务中的有效性。通过大规模实验,证明了随机探索数据可以作为一种经济高效的数据来源,用于引导数据收集和预训练网络。
关键设计:该研究设计了一个基于云的微服务架构,用于实时监控和自动化数据处理流程。此外,研究中使用了自监督学习目标,例如视频预测或对比学习,来从随机探索视频中提取有用的特征表示。具体的参数设置和网络结构未在摘要中详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
该研究通过807小时的随机动作和71小时的随机探索视频(128万帧)的大规模实验,证明了随机探索在双层堆叠任务中的有效性。进行了1260次策略评估,验证了该方法的性能。数据集和自动化流程将公开,为未来研究提供便利。
🎯 应用场景
该研究成果可应用于各种机器人操作任务,尤其是在数据获取成本高昂或难以进行人工标注的场景下。例如,可用于自动化装配、物流分拣、家庭服务等领域,降低机器人部署和维护成本,提高机器人的智能化水平和适应能力。未来,可以进一步探索更有效的随机探索策略和自监督学习方法,以提高数据利用率和模型性能。
📄 摘要(原文)
Data scarcity presents a key bottleneck for imitation learning in robotic manipulation. In this paper, we focus on random exploration data-actions and video sequences produced autonomously via motions to randomly sampled positions in the workspace-to investigate their potential as a cost-effective data source. Our investigation follows two paradigms: (a) random actions, where we assess their feasibility for autonomously bootstrapping data collection policies, and (b) random exploration video frames, where we evaluate their effectiveness in pre-training parameter-dense networks with self-supervised learning objectives. To minimize human supervision, we first develop a fully automated pipeline that handles episode labeling, termination, and resetting using cloud-based microservices for real-time monitoring. Building on this, we present a large-scale study on the cost-effectiveness of real-world random exploration in a non-trivial two-layer stacking task, drawing on statistical results from 807 hours of random actions, 71 hours of random exploration video (1.28M frames), and 1,260 times of policy evaluation. The dataset will be made publicly available and access to the robot environment with the automated pipeline is to be made accessible via cloud service for future research.