Empirical Analysis of Sim-and-Real Cotraining of Diffusion Policies for Planar Pushing from Pixels
作者: Adam Wei, Abhinav Agarwal, Boyuan Chen, Rohan Bosworth, Nicholas Pfaff, Russ Tedrake
分类: cs.RO, cs.AI
发布日期: 2025-03-28 (更新: 2025-08-05)
备注: 11 pages, 17 figures, IROS 2025 Aug 5, 2025 update: Included new experiments in Sections V and VII. Updated abstract and minor changes to text
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
研究Sim-to-Real扩散策略中,仿真与真实数据协同训练对平面推物任务的影响。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: Sim-to-Real 协同训练 扩散策略 模仿学习 平面推物 机器人操作 域适应
📋 核心要点
- 现有机器人模仿学习方法在真实环境中数据获取成本高昂,限制了其应用范围。
- 采用仿真与真实数据协同训练,利用廉价的仿真数据提升策略在真实环境中的性能。
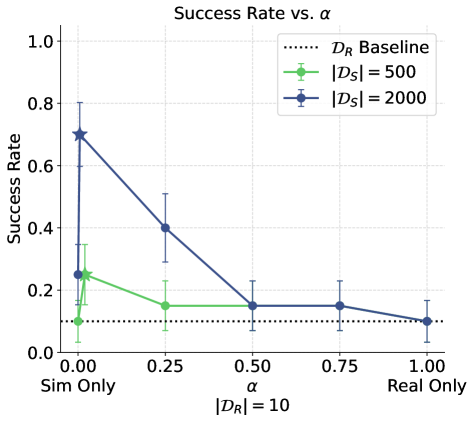
- 实验表明,增加仿真数据可以提高性能,但存在上限,增加真实数据可以突破该上限。
📝 摘要(中文)
本文旨在阐明仿真与真实数据协同训练的基本原则,以指导仿真设计、数据集创建和策略训练,从而扩展机器人模仿学习。实验证实,与仿真数据协同训练能显著提高性能,尤其是在真实数据有限的情况下。性能增益随仿真数据增加而提升,直至达到瓶颈;增加真实数据则能提高性能上限。研究表明,对于非抓取或接触丰富的任务,缩小物理域差距可能比视觉逼真度更重要。令人惊讶的是,一定程度的视觉差距反而有助于协同训练——二元探测显示,高性能策略必须学会区分仿真和真实环境。最后,本文探讨了这种细微差别以及促进仿真与真实之间正向迁移的机制。通过专注于平面推物这一典型任务,实现了深入研究。实验涵盖50多个真实策略(超过1000次试验)和250个仿真策略(超过50,000次试验)。
🔬 方法详解
问题定义:论文旨在解决平面推物任务中,如何有效利用仿真数据提升真实环境中扩散策略的性能问题。现有方法在真实数据有限的情况下,难以训练出鲁棒性强的策略,且仿真环境与真实环境的差异(domain gap)会影响策略的迁移效果。
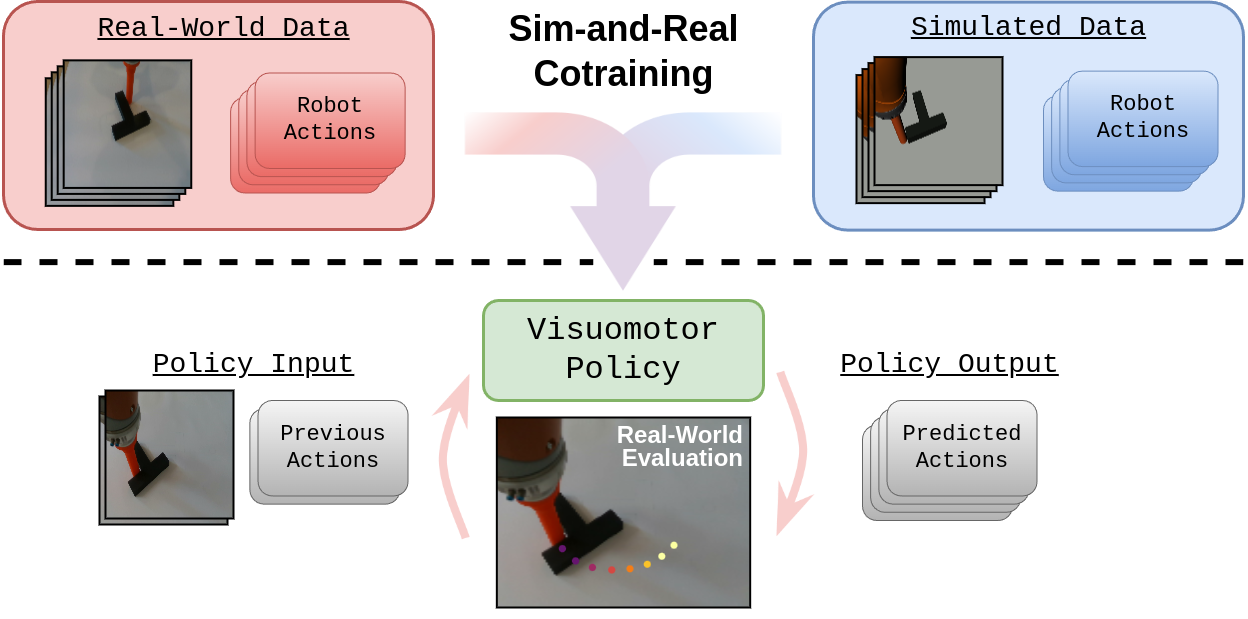
核心思路:论文的核心思路是通过仿真与真实数据协同训练,让策略同时学习仿真环境和真实环境的特征,从而提高策略在真实环境中的泛化能力。通过控制仿真环境的视觉和物理属性,研究不同类型的domain gap对策略性能的影响,并探索促进正向迁移的机制。
技术框架:整体框架包含以下几个主要部分:1) 仿真环境搭建,用于生成大量的仿真数据;2) 真实环境数据采集,用于提供真实环境的反馈;3) 扩散策略训练,使用仿真和真实数据进行协同训练;4) 策略评估,在真实环境中测试策略的性能。
关键创新:论文的关键创新在于对仿真与真实数据协同训练进行了深入的实证分析,揭示了不同类型的domain gap对策略性能的影响,并提出了促进正向迁移的机制。此外,论文还发现,一定程度的视觉差距反而有助于协同训练,这与直觉相反。
关键设计:论文使用了扩散模型作为策略学习的基础模型。在仿真环境设计方面,论文控制了视觉逼真度和物理属性的差异,例如摩擦系数、物体质量等。在损失函数设计方面,论文可能使用了某种形式的域对抗损失,以鼓励策略学习区分仿真和真实环境的特征。具体的网络结构和参数设置在论文中可能有所描述,但摘要中未提及。
🖼️ 关键图片

📊 实验亮点
实验结果表明,与仅使用真实数据相比,仿真与真实数据协同训练能显著提高平面推物任务的性能。性能增益随仿真数据增加而提升,直至达到瓶颈;增加真实数据则能提高性能上限。研究还发现,一定程度的视觉差距反而有助于协同训练,这为仿真环境的设计提供了新的思路。
🎯 应用场景
该研究成果可应用于机器人操作、自动驾驶等领域,通过仿真与真实数据协同训练,降低机器人学习的成本,提高机器人在复杂环境中的适应能力。未来的研究可以探索更复杂的任务和环境,以及更有效的协同训练方法,例如自适应域适应、元学习等。
📄 摘要(原文)
Cotraining with demonstration data generated both in simulation and on real hardware has emerged as a promising recipe for scaling imitation learning in robotics. This work seeks to elucidate basic principles of this sim-and-real cotraining to inform simulation design, sim-and-real dataset creation, and policy training. Our experiments confirm that cotraining with simulated data can dramatically improve performance, especially when real data is limited. We show that these performance gains scale with additional simulated data up to a plateau; adding more real-world data increases this performance ceiling. The results also suggest that reducing physical domain gaps may be more impactful than visual fidelity for non-prehensile or contact-rich tasks. Perhaps surprisingly, we find that some visual gap can help cotraining -- binary probes reveal that high-performing policies must learn to distinguish simulated domains from real. We conclude by investigating this nuance and mechanisms that facilitate positive transfer between sim-and-real. Focusing narrowly on the canonical task of planar pushing from pixels allows us to be thorough in our study. In total, our experiments span 50+ real-world policies (evaluated on 1000+ trials) and 250 simulated policies (evaluated on 50,000+ trials). Videos and code can be found at https://sim-and-real-cotraining.github.io/.