Gemini Robotics: Bringing AI into the Physical World
作者: Gemini Robotics Team, Saminda Abeyruwan, Joshua Ainslie, Jean-Baptiste Alayrac, Montserrat Gonzalez Arenas, Travis Armstrong, Ashwin Balakrishna, Robert Baruch, Maria Bauza, Michiel Blokzijl, Steven Bohez, Konstantinos Bousmalis, Anthony Brohan, Thomas Buschmann, Arunkumar Byravan, Serkan Cabi, Ken Caluwaerts, Federico Casarini, Oscar Chang, Jose Enrique Chen, Xi Chen, Hao-Tien Lewis Chiang, Krzysztof Choromanski, David D'Ambrosio, Sudeep Dasari, Todor Davchev, Coline Devin, Norman Di Palo, Tianli Ding, Adil Dostmohamed, Danny Driess, Yilun Du, Debidatta Dwibedi, Michael Elabd, Claudio Fantacci, Cody Fong, Erik Frey, Chuyuan Fu, Marissa Giustina, Keerthana Gopalakrishnan, Laura Graesser, Leonard Hasenclever, Nicolas Heess, Brandon Hernaez, Alexander Herzog, R. Alex Hofer, Jan Humplik, Atil Iscen, Mithun George Jacob, Deepali Jain, Ryan Julian, Dmitry Kalashnikov, M. Emre Karagozler, Stefani Karp, Chase Kew, Jerad Kirkland, Sean Kirmani, Yuheng Kuang, Thomas Lampe, Antoine Laurens, Isabel Leal, Alex X. Lee, Tsang-Wei Edward Lee, Jacky Liang, Yixin Lin, Sharath Maddineni, Anirudha Majumdar, Assaf Hurwitz Michaely, Robert Moreno, Michael Neunert, Francesco Nori, Carolina Parada, Emilio Parisotto, Peter Pastor, Acorn Pooley, Kanishka Rao, Krista Reymann, Dorsa Sadigh, Stefano Saliceti, Pannag Sanketi, Pierre Sermanet, Dhruv Shah, Mohit Sharma, Kathryn Shea, Charles Shu, Vikas Sindhwani, Sumeet Singh, Radu Soricut, Jost Tobias Springenberg, Rachel Sterneck, Razvan Surdulescu, Jie Tan, Jonathan Tompson, Vincent Vanhoucke, Jake Varley, Grace Vesom, Giulia Vezzani, Oriol Vinyals, Ayzaan Wahid, Stefan Welker, Paul Wohlhart, Fei Xia, Ted Xiao, Annie Xie, Jinyu Xie, Peng Xu, Sichun Xu, Ying Xu, Zhuo Xu, Yuxiang Yang, Rui Yao, Sergey Yaroshenko, Wenhao Yu, Wentao Yuan, Jingwei Zhang, Tingnan Zhang, Allan Zhou, Yuxiang Zhou
分类: cs.RO
发布日期: 2025-03-25
💡 一句话要点
Gemini Robotics:将AI引入物理世界,构建通用机器人
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人控制 视觉语言动作模型 多模态学习 具身智能 通用机器人
📋 核心要点
- 现有方法难以将大型多模态模型的能力有效迁移到物理机器人上,导致机器人难以泛化到复杂环境和任务。
- Gemini Robotics通过构建视觉-语言-动作(VLA)通用模型,直接控制机器人,实现平滑、鲁棒的运动控制和任务执行。
- Gemini Robotics在长时程任务、小样本学习和机器人形态适应性方面表现出色,证明了其在机器人领域的泛化潜力。
📝 摘要(中文)
大型多模态模型的最新进展已经在数字领域展现了卓越的通用能力,但将其转化为物理智能体(如机器人)仍然是一个重大挑战。本报告介绍了一个新的AI模型系列Gemini Robotics,它专门为机器人技术而设计,并建立在Gemini 2.0的基础之上。Gemini Robotics是一个先进的视觉-语言-动作(VLA)通用模型,能够直接控制机器人。它可以执行平滑且反应灵敏的动作,以应对各种复杂的操纵任务,同时对物体类型和位置的变化具有鲁棒性,能够处理未见过的环境,并遵循多样化的开放词汇指令。通过额外的微调,Gemini Robotics可以专门用于新的能力,包括解决长时程、高度灵巧的任务,从仅100个演示中学习新的短时程任务,以及适应全新的机器人形态。这得益于Gemini Robotics构建于Gemini Robotics-ER模型之上,这是本研究中介绍的第二个模型。Gemini Robotics-ER(具身推理)将Gemini的多模态推理能力扩展到物理世界,增强了空间和时间理解能力。这使得与机器人技术相关的能力成为可能,包括物体检测、指向、轨迹和抓取预测,以及多视图对应和3D边界框预测。我们展示了这种新颖的组合如何支持各种机器人应用。我们还讨论并解决了与这类新型机器人基础模型相关的重要安全考虑。Gemini Robotics系列标志着在开发通用机器人方面迈出了重要一步,实现了AI在物理世界中的潜力。
🔬 方法详解
问题定义:现有机器人控制方法通常依赖于特定任务的训练数据,泛化能力差,难以适应复杂多变的环境和任务需求。将大型多模态模型应用于机器人控制面临着如何将数字世界的知识迁移到物理世界,以及如何处理机器人运动的连续性和实时性等挑战。
核心思路:Gemini Robotics的核心思路是构建一个视觉-语言-动作(VLA)通用模型,该模型能够理解视觉输入(如摄像头图像)、语言指令,并生成相应的机器人动作。通过在大量数据上进行预训练,模型可以学习到通用的物理世界知识和运动控制策略,从而实现更好的泛化能力。
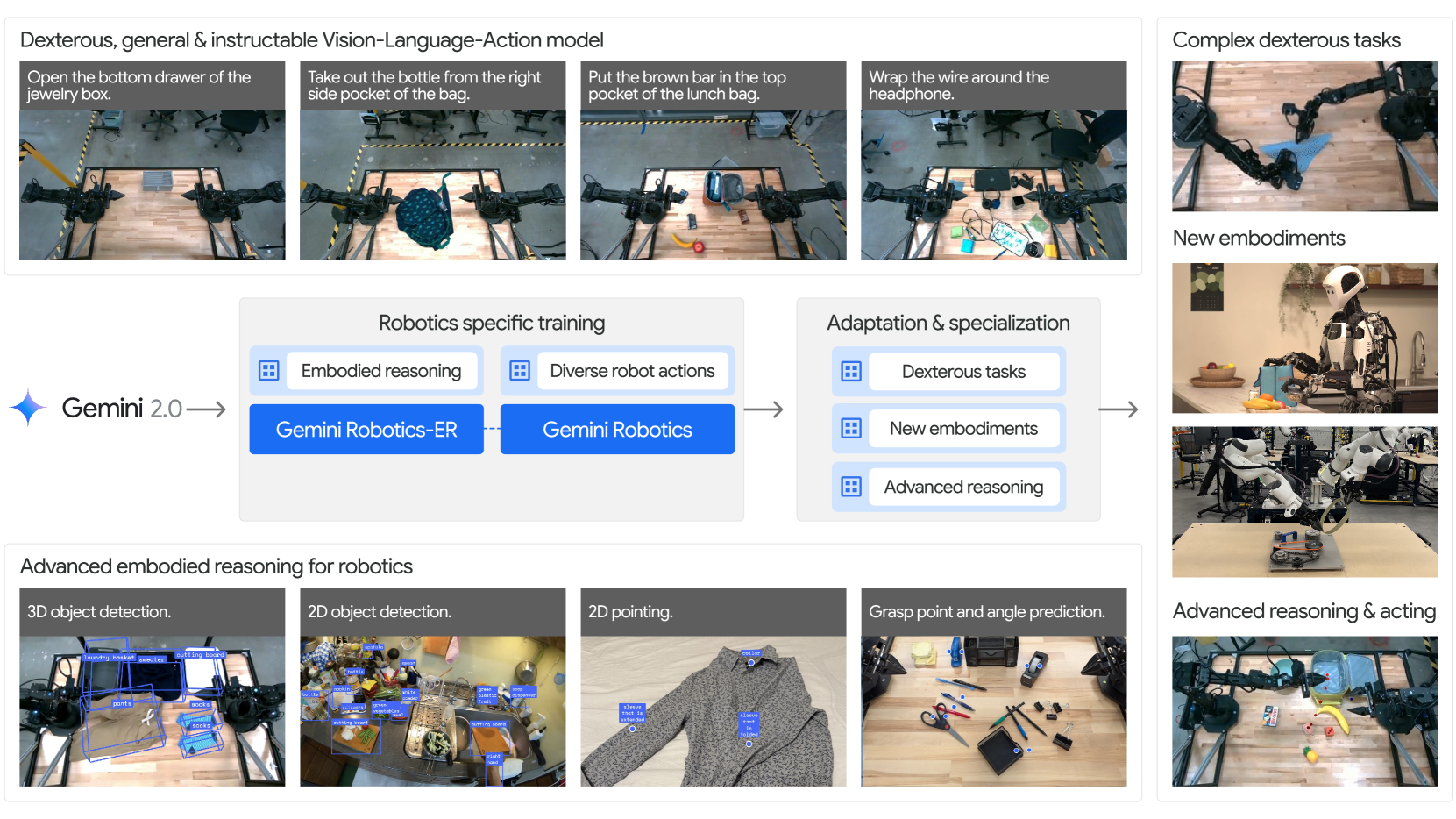
技术框架:Gemini Robotics建立在Gemini 2.0的基础之上,并引入了Gemini Robotics-ER(Embodied Reasoning)模型。整体架构包含以下几个主要模块:1) 视觉编码器:将摄像头图像转换为视觉特征表示。2) 语言编码器:将语言指令转换为语言特征表示。3) 多模态融合模块:将视觉和语言特征进行融合,得到统一的场景表示。4) 动作解码器:根据场景表示生成机器人的动作指令。Gemini Robotics-ER模型增强了模型的空间和时间理解能力,用于物体检测、轨迹预测等任务。
关键创新:Gemini Robotics的关键创新在于其VLA通用模型的架构设计和训练方法。通过将视觉、语言和动作信息进行统一建模,模型可以学习到更丰富的物理世界知识和运动控制策略。此外,Gemini Robotics-ER模型的引入进一步提升了模型在物理环境中的推理能力。
关键设计:Gemini Robotics使用了Transformer架构作为其核心模型。损失函数包括动作预测损失、物体检测损失等。训练数据包括大量的机器人操作视频和语言指令。模型还采用了数据增强技术,以提高模型的鲁棒性。
🖼️ 关键图片


📊 实验亮点
Gemini Robotics在多个机器人任务上取得了显著成果。通过少量演示(100个),即可学习新的短时程任务。在长时程、高灵巧性任务中表现出色。此外,Gemini Robotics还能够适应全新的机器人形态,展示了其强大的泛化能力和适应性。
🎯 应用场景
Gemini Robotics具有广泛的应用前景,包括智能制造、物流仓储、家庭服务、医疗健康等领域。它可以用于自动化装配、货物搬运、清洁打扫、辅助医疗等任务,提高生产效率和服务质量。未来,Gemini Robotics有望成为通用机器人的核心技术,实现AI在物理世界的广泛应用。
📄 摘要(原文)
Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.