Semi-SMD: Semi-Supervised Metric Depth Estimation via Surrounding Cameras for Autonomous Driving
作者: Yusen Xie, Zhengmin Huang, Shaojie Shen, Jun Ma
分类: cs.RO, cs.CV
发布日期: 2025-03-25 (更新: 2025-09-09)
🔗 代码/项目: GITHUB
💡 一句话要点
Semi-SMD:面向自动驾驶,利用环视相机实现半监督度量深度估计
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 深度估计 环视相机 自动驾驶 时空融合 交叉注意力 半监督学习 度量尺度 姿态估计
📋 核心要点
- 现有方法在多相机深度估计中存在尺度模糊问题,且缺乏有效的时空信息融合机制。
- Semi-SMD通过统一的时空语义融合模块和交叉注意力机制,有效融合多相机和时序信息,提升深度估计精度。
- 在DDAD和nuScenes数据集上,Semi-SMD取得了state-of-the-art的深度估计性能,验证了其有效性。
📝 摘要(中文)
本文提出了一种名为Semi-SMD的新型度量深度估计框架,专为自动驾驶中的环视相机设备设计。该方法以相邻环视帧和相机参数作为输入,提出了一个统一的时空语义融合模块来构建视觉融合特征。利用环视相机和相邻帧的交叉注意力机制,专注于度量尺度信息的细化和时间特征匹配。在此基础上,提出了一个使用环视相机、其对应的估计深度和外参的姿态估计框架,有效解决了多相机设置中的尺度模糊问题。此外,集成了语义世界模型和单目深度估计世界模型来监督深度估计,从而提高深度估计的质量。在DDAD和nuScenes数据集上的评估结果表明,该方法在基于环视相机的深度估计质量方面达到了最先进的性能。
🔬 方法详解
问题定义:论文旨在解决自动驾驶场景下,利用环视相机进行精确度量深度估计的问题。现有方法在多相机系统中标定困难,容易出现尺度模糊,并且缺乏有效的时空信息融合机制,导致深度估计精度受限。
核心思路:论文的核心思路是利用相邻环视帧的时序信息和多相机之间的空间信息,通过统一的时空语义融合模块和交叉注意力机制,学习更鲁棒和精确的深度信息。同时,引入语义世界模型和单目深度估计世界模型作为监督信号,进一步提升深度估计的质量。
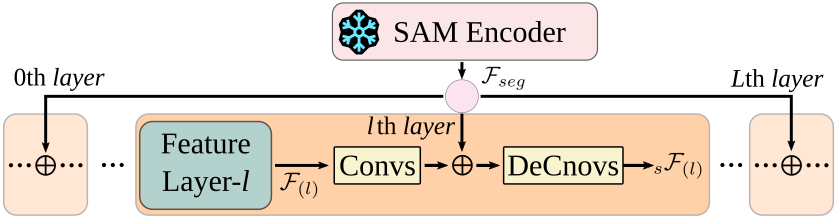
技术框架:Semi-SMD框架主要包含以下几个模块:1) 特征提取模块:提取环视相机图像的视觉特征。2) 时空语义融合模块:融合相邻帧和多相机的特征,构建统一的视觉表示。3) 交叉注意力模块:利用交叉注意力机制,细化度量尺度信息和匹配时间特征。4) 姿态估计模块:利用估计的深度和相机外参,进行姿态估计,解决尺度模糊问题。5) 深度估计模块:预测每个像素的深度值。
关键创新:该论文的关键创新在于:1) 提出了统一的时空语义融合模块,能够有效融合多相机和时序信息。2) 引入了交叉注意力机制,能够自适应地关注重要的特征,提升深度估计的精度。3) 提出了基于环视相机的姿态估计框架,能够有效解决多相机设置中的尺度模糊问题。4) 结合了语义世界模型和单目深度估计世界模型,作为额外的监督信号,提升深度估计的鲁棒性。
关键设计:论文中,交叉注意力模块的设计是关键。通过计算不同相机和不同帧之间的注意力权重,能够自适应地选择重要的特征,从而提升深度估计的精度。此外,损失函数的设计也至关重要,论文采用了深度损失、姿态损失和语义损失的组合,以保证深度估计的准确性和一致性。
🖼️ 关键图片


📊 实验亮点
Semi-SMD在DDAD和nuScenes数据集上取得了state-of-the-art的性能。实验结果表明,该方法在深度估计精度方面显著优于现有方法,尤其是在复杂场景和遮挡情况下,表现出更强的鲁棒性。具体的性能数据可以在论文中找到。
🎯 应用场景
该研究成果可广泛应用于自动驾驶领域,例如环境感知、路径规划和决策控制。精确的深度估计能够帮助自动驾驶车辆更好地理解周围环境,提高行驶安全性。此外,该方法还可以应用于机器人导航、三维重建等领域,具有重要的实际应用价值和广阔的发展前景。
📄 摘要(原文)
In this paper, we introduce Semi-SMD, a novel metric depth estimation framework tailored for surrounding cameras equipment in autonomous driving. In this work, the input data consists of adjacent surrounding frames and camera parameters. We propose a unified spatial-temporal-semantic fusion module to construct the visual fused features. Cross-attention components for surrounding cameras and adjacent frames are utilized to focus on metric scale information refinement and temporal feature matching. Building on this, we propose a pose estimation framework using surrounding cameras, their corresponding estimated depths, and extrinsic parameters, which effectively address the scale ambiguity in multi-camera setups. Moreover, semantic world model and monocular depth estimation world model are integrated to supervised the depth estimation, which improve the quality of depth estimation. We evaluate our algorithm on DDAD and nuScenes datasets, and the results demonstrate that our method achieves state-of-the-art performance in terms of surrounding camera based depth estimation quality. The source code will be available on https://github.com/xieyuser/Semi-SMD.