CubeRobot: Grounding Language in Rubik's Cube Manipulation via Vision-Language Model
作者: Feiyang Wang, Xiaomin Yu, Wangyu Wu
分类: cs.RO, cs.AI
发布日期: 2025-03-25
💡 一句话要点
提出CubeRobot,利用视觉-语言模型解决魔方操作中的语言理解与执行问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 魔方机器人 具身智能 多模态学习 机器人操作
📋 核心要点
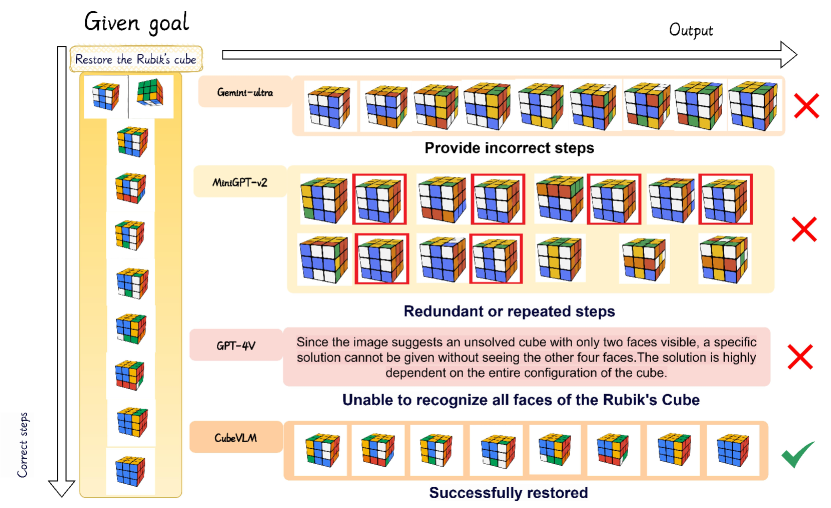
- 传统魔方机器人依赖复杂的视觉系统和固定算法,难以适应复杂和动态的场景,这是目前面临的核心问题。
- CubeRobot的核心思想是利用视觉-语言模型,赋予机器人多模态理解和执行能力,从而更好地解决魔方问题。
- 实验结果表明,CubeRobot在低、中、高级魔方任务中分别实现了100%、100%和80%的准确率,验证了其有效性。
📝 摘要(中文)
本文提出了一种名为CubeRobot的新型视觉-语言模型(VLM),专门用于解决3x3魔方问题,旨在赋予具身智能体多模态理解和执行能力。该模型使用CubeCoT图像数据集进行训练,该数据集包含人类难以处理的多层次任务(总共43个子任务),涵盖各种魔方状态。CubeRobot集成了双环VisionCoT架构和记忆流机制,从VLM生成的规划查询中提取任务相关特征,从而实现独立规划、决策、反思以及对高低级魔方任务的独立管理。在低级魔方复原任务中,CubeRobot实现了100%的准确率,在中级任务中也达到了100%,而在高级任务中达到了80%的准确率。
🔬 方法详解
问题定义:传统魔方机器人依赖于复杂的视觉系统和预定义的算法,这使得它们难以适应动态变化的环境和复杂的任务。现有的方法在处理高级推理和规划任务时表现不足,无法像人类一样进行空间想象和逻辑推理。因此,需要一种能够理解自然语言指令并将其转化为魔方操作的智能体。
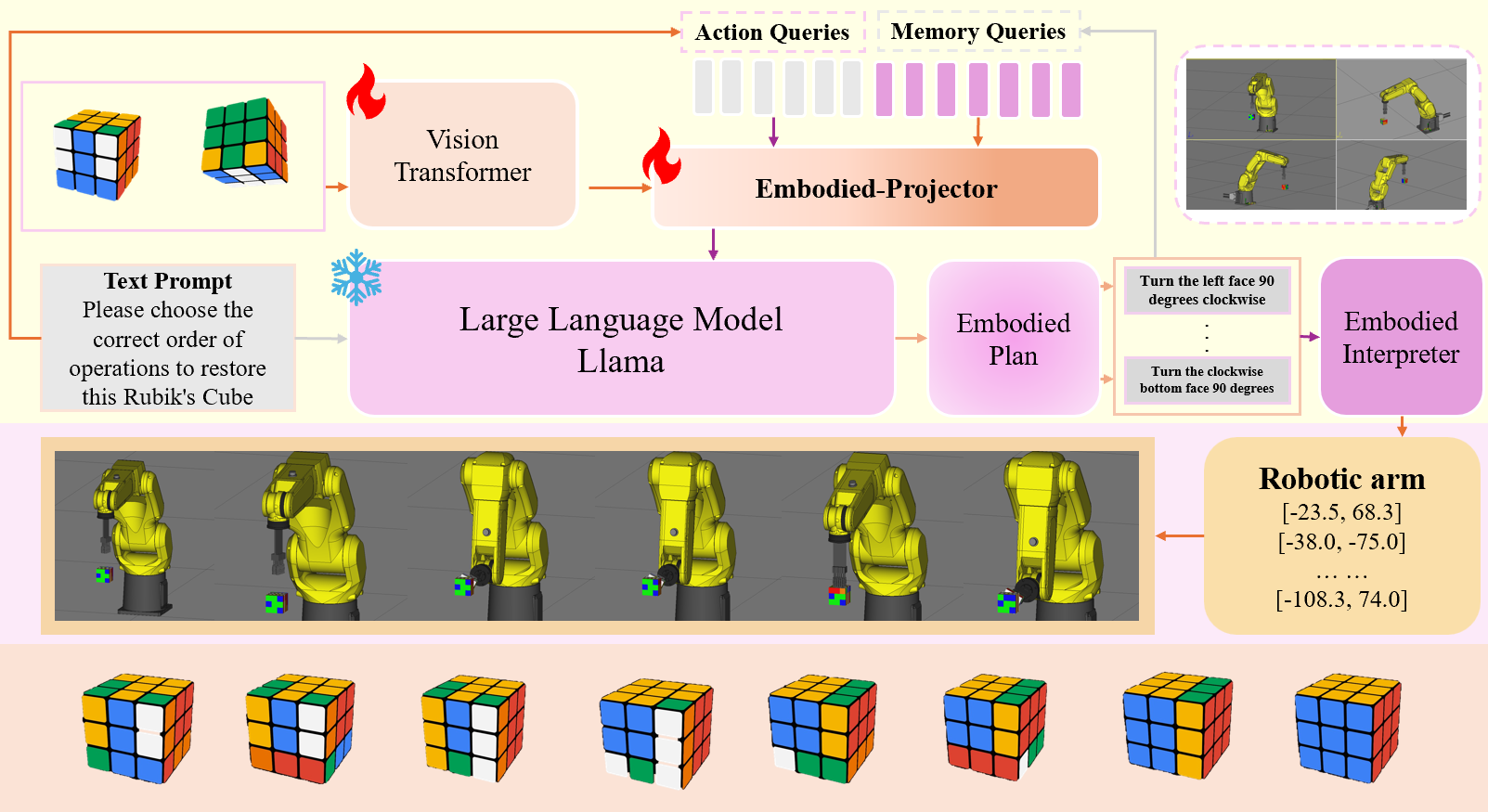
核心思路:CubeRobot的核心思路是利用视觉-语言模型(VLM)将视觉信息(魔方状态)和语言指令(例如,复原魔方)联系起来。通过训练VLM,使机器人能够理解指令,规划操作步骤,并执行这些步骤来解决魔方问题。这种方法的关键在于将魔方操作分解为多个层次的任务,并利用VLM进行高层次的规划和低层次的执行。
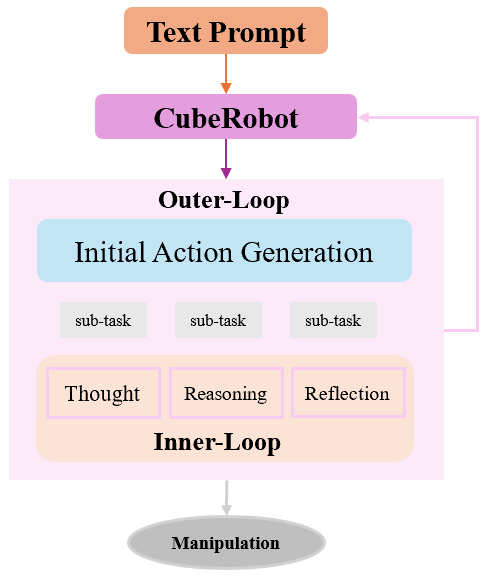
技术框架:CubeRobot的技术框架主要包括以下几个模块:1) 视觉输入模块:用于获取魔方的图像信息。2) 视觉-语言模型(VLM):核心模块,用于理解语言指令并生成操作规划。采用双环VisionCoT架构,增强推理能力。3) 记忆流(Memory Stream):用于从VLM生成的规划查询中提取任务相关特征,辅助决策。4) 执行模块:根据VLM生成的规划,控制机械臂执行魔方操作。
关键创新:CubeRobot的关键创新在于:1) 双环VisionCoT架构:增强了VLM的推理能力,使其能够更好地理解复杂指令并生成有效的操作规划。2) 记忆流机制:能够从VLM生成的规划查询中提取任务相关特征,从而更好地指导机器人的决策和执行。3) 多层次任务分解:将魔方操作分解为多个层次的任务,使机器人能够更好地管理高层次的规划和低层次的执行。
关键设计:CubeRobot使用了CubeCoT图像数据集进行训练,该数据集包含多个层次的任务,涵盖各种魔方状态。VLM的具体结构未知,但采用了VisionCoT架构,可能包含Transformer等关键组件。记忆流的具体实现方式未知,但其目的是提取任务相关特征。损失函数和优化器的具体选择未知,但需要保证VLM能够有效地学习视觉信息和语言指令之间的关系。
🖼️ 关键图片
📊 实验亮点
CubeRobot在不同难度的魔方复原任务中表现出色。在低级和中级任务中,准确率均达到100%。在更具挑战性的高级任务中,准确率也达到了80%。这些结果表明,CubeRobot能够有效地理解语言指令,规划操作步骤,并执行这些步骤来解决魔方问题,验证了其在复杂操作任务中的潜力。
🎯 应用场景
CubeRobot的研究成果可应用于自动化魔方解算、机器人教学、智能玩具等领域。更广泛地,该研究为开发能够理解和执行复杂任务的具身智能体提供了新的思路,有助于推动机器人技术在工业自动化、服务机器人等领域的应用。未来,可以将该方法扩展到其他需要复杂操作和推理的任务中,例如装配、维修等。
📄 摘要(原文)
Proving Rubik's Cube theorems at the high level represents a notable milestone in human-level spatial imagination and logic thinking and reasoning. Traditional Rubik's Cube robots, relying on complex vision systems and fixed algorithms, often struggle to adapt to complex and dynamic scenarios. To overcome this limitation, we introduce CubeRobot, a novel vision-language model (VLM) tailored for solving 3x3 Rubik's Cubes, empowering embodied agents with multimodal understanding and execution capabilities. We used the CubeCoT image dataset, which contains multiple-level tasks (43 subtasks in total) that humans are unable to handle, encompassing various cube states. We incorporate a dual-loop VisionCoT architecture and Memory Stream, a paradigm for extracting task-related features from VLM-generated planning queries, thus enabling CubeRobot to independent planning, decision-making, reflection and separate management of high- and low-level Rubik's Cube tasks. Furthermore, in low-level Rubik's Cube restoration tasks, CubeRobot achieved a high accuracy rate of 100%, similar to 100% in medium-level tasks, and achieved an accuracy rate of 80% in high-level tasks.