Explosive Jumping with Rigid and Articulated Soft Quadrupeds via Example Guided Reinforcement Learning
作者: Georgios Apostolides, Wei Pan, Jens Kober, Cosimo Della Santina, Jiatao Ding
分类: cs.RO
发布日期: 2025-03-20 (更新: 2025-08-26)
备注: accepted by IROS2025
💡 一句话要点
提出基于示例引导强化学习的跳跃控制方法,实现刚性和柔性四足机器人的高难度跳跃动作。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 四足机器人 跳跃控制 强化学习 模仿学习 柔性机器人
📋 核心要点
- 四足机器人跳跃控制面临被动柔顺机构引入的挑战,传统方法难以兼顾性能与鲁棒性。
- 论文提出一种基于示例引导的深度强化学习方法,通过模仿学习和策略泛化实现复杂跳跃动作。
- 实验结果表明,该方法能有效提升柔性四足机器人的跳跃性能,并增强对未知环境的适应性。
📝 摘要(中文)
本研究致力于解决四足机器人,特别是具有被动柔顺机构设计的四足机器人,实现可控跳跃行为的难题。为此,我们提出了一种基于模仿学习的深度强化学习方法,并采用渐进式训练流程。首先,通过模仿基于模型的轨迹优化生成的粗略跳跃示例来学习跳跃技能。然后,将学习到的策略推广到更广泛的场景,包括在前后和横向方向上的各种距离。进一步,追求在未知的地面不平整情况下实现鲁棒的跳跃。此外,在不大幅调整奖励函数的情况下,我们学习了具有并联弹性机构的四足机器人的跳跃策略。结果表明,使用所提出的方法,i) 机器人仅通过学习单个演示即可学习多功能的跳跃;ii) 与没有并联弹性的刚性机器人相比,具有并联柔顺机构的机器人可将着陆误差降低 11.1%,节省能量成本 15.2%,并降低峰值扭矩 15.8%;iii) 机器人仅使用本体感受即可执行可变距离的跳跃,并对地面不平整(最大 4 厘米高度扰动)具有鲁棒性。
🔬 方法详解
问题定义:论文旨在解决四足机器人,特别是具有被动柔顺机构的四足机器人,实现稳定、高效、鲁棒跳跃控制的问题。现有方法在处理柔顺机构带来的复杂动力学时,往往难以兼顾跳跃的性能和对环境变化的适应性。
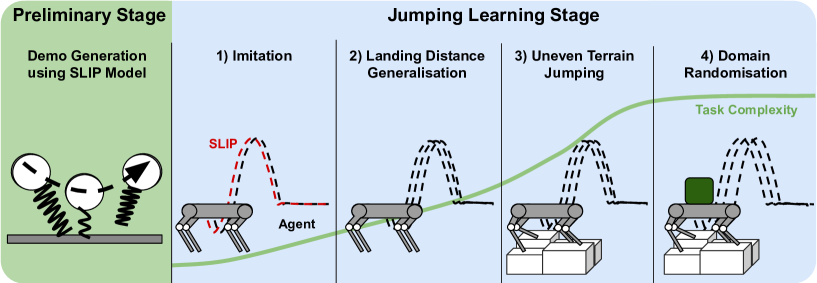
核心思路:论文的核心思路是利用模仿学习引导强化学习,通过模仿一个粗略的跳跃示例,快速学习到初步的跳跃策略,然后利用强化学习的优势,将该策略泛化到更广泛的场景,并提高其鲁棒性。这种方法结合了模仿学习的快速学习能力和强化学习的策略优化能力。
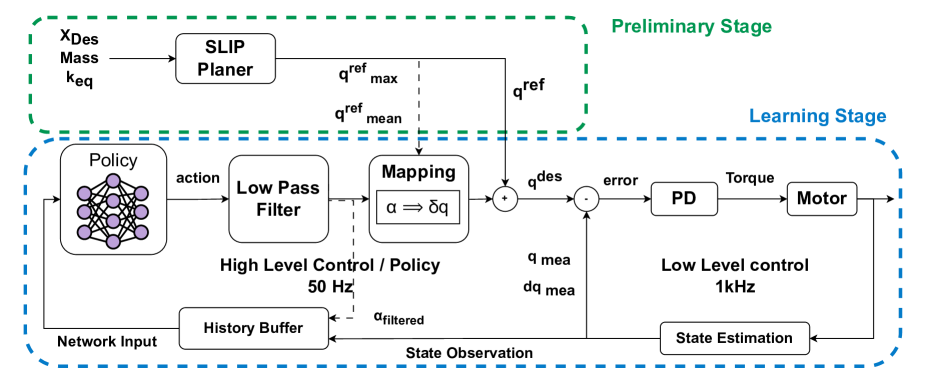
技术框架:整体框架包含三个主要阶段:1) 基于模型的轨迹优化生成粗略的跳跃示例;2) 通过模仿学习,利用深度强化学习算法,从示例中学习初步的跳跃策略;3) 通过强化学习,将学习到的策略泛化到不同的跳跃距离和地面不平整情况。该框架使用渐进式训练流程,逐步提升机器人的跳跃能力和鲁棒性。
关键创新:论文的关键创新在于将模仿学习和强化学习相结合,并采用渐进式训练流程。通过模仿学习,可以快速学习到初步的跳跃策略,避免了从零开始探索的困难。通过强化学习,可以对策略进行优化,提高其泛化能力和鲁棒性。此外,论文还针对具有并联弹性机构的四足机器人进行了优化,使其能够更好地利用柔顺机构的优势。
关键设计:论文使用深度强化学习算法,例如PPO或者SAC,来学习跳跃策略。奖励函数的设计至关重要,需要综合考虑跳跃距离、着陆稳定性、能量消耗等因素。网络结构的选择也需要根据具体任务进行调整,例如可以使用循环神经网络来处理时序信息。此外,论文还采用了课程学习的思想,逐步增加训练难度,以提高策略的泛化能力。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法能够使四足机器人仅通过学习单个演示即可学习多功能的跳跃。与没有并联弹性的刚性机器人相比,具有并联柔顺机构的机器人可将着陆误差降低 11.1%,节省能量成本 15.2%,并降低峰值扭矩 15.8%。此外,机器人仅使用本体感受即可执行可变距离的跳跃,并对地面不平整(最大 4 厘米高度扰动)具有鲁棒性。
🎯 应用场景
该研究成果可应用于搜救机器人、勘探机器人等领域,使其能够在复杂地形环境下进行高效移动和作业。通过提升四足机器人的跳跃能力和环境适应性,可以扩展其应用范围,使其在灾后救援、野外勘探等场景中发挥更大的作用。此外,该研究对于开发更具运动智能的机器人具有重要的参考价值。
📄 摘要(原文)
Achieving controlled jumping behaviour for a quadruped robot is a challenging task, especially when introducing passive compliance in mechanical design. This study addresses this challenge via imitation-based deep reinforcement learning with a progressive training process. To start, we learn the jumping skill by mimicking a coarse jumping example generated by model-based trajectory optimization. Subsequently, we generalize the learned policy to broader situations, including various distances in both forward and lateral directions, and then pursue robust jumping in unknown ground unevenness. In addition, without tuning the reward much, we learn the jumping policy for a quadruped with parallel elasticity. Results show that using the proposed method, i) the robot learns versatile jumps by learning only from a single demonstration, ii) the robot with parallel compliance reduces the landing error by 11.1%, saves energy cost by 15.2% and reduces the peak torque by 15.8%, compared to the rigid robot without parallel elasticity, iii) the robot can perform jumps of variable distances with robustness against ground unevenness (maximal 4cm height perturbations) using only proprioceptive perception.