GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
作者: NVIDIA, :, Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi "Jim" Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith Llontop, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed, You Liang Tan, Guanzhi Wang, Zu Wang, Jing Wang, Qi Wang, Jiannan Xiang, Yuqi Xie, Yinzhen Xu, Zhenjia Xu, Seonghyeon Ye, Zhiding Yu, Ao Zhang, Hao Zhang, Yizhou Zhao, Ruijie Zheng, Yuke Zhu
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-03-18 (更新: 2025-03-27)
备注: Authors are listed alphabetically. Project leads are Linxi "Jim" Fan and Yuke Zhu. For more information, see https://developer.nvidia.com/isaac/gr00t
💡 一句话要点
NVIDIA发布GR00T N1:通用人形机器人开放基础模型
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人形机器人 基础模型 视觉语言动作模型 模仿学习 扩散模型
📋 核心要点
- 现有机器人模型泛化能力弱,难以应对真实世界的多样性,且学习新任务效率低。
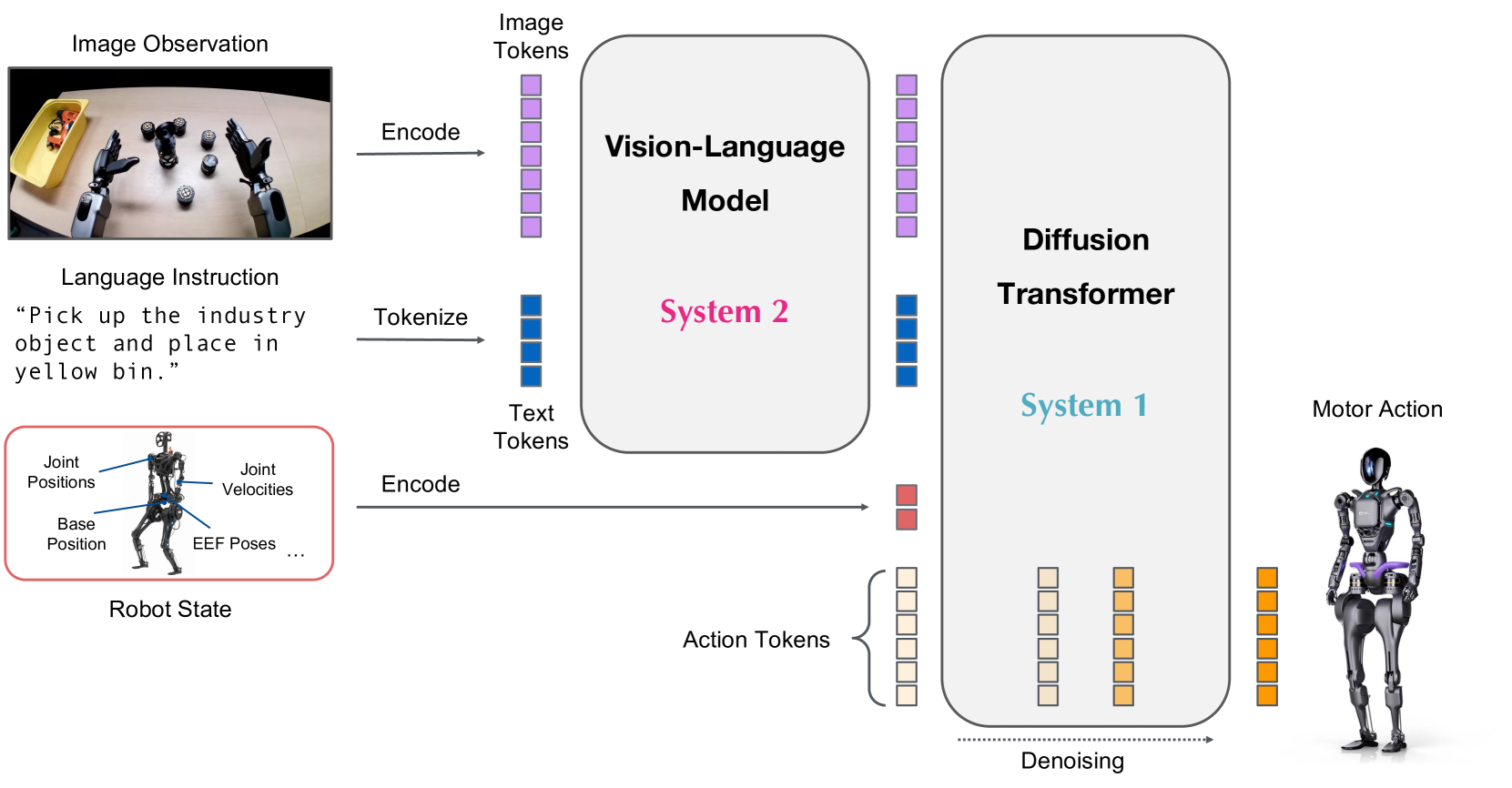
- GR00T N1采用双系统架构的VLA模型,结合视觉语言理解和扩散Transformer动作生成。
- 实验表明,GR00T N1在模拟和真实机器人上均优于现有模仿学习方法,数据效率高。
📝 摘要(中文)
本文介绍了GR00T N1,一个用于人形机器人的开放基础模型。通用机器人需要多功能的身体和智能的头脑。人形机器人技术的最新进展展示了作为在人类世界中构建通用自主性的硬件平台的巨大潜力。一个在海量和多样化数据源上训练的机器人基础模型,对于使机器人能够推理新情况、稳健地处理真实世界的变异性以及快速学习新任务至关重要。GR00T N1是一个具有双系统架构的视觉-语言-动作(VLA)模型。视觉-语言模块(系统2)通过视觉和语言指令解释环境。随后的扩散Transformer模块(系统1)实时生成流畅的运动动作。两个模块紧密耦合,并进行端到端联合训练。我们使用真实机器人轨迹、人类视频和合成生成数据集的异构混合来训练GR00T N1。我们表明,我们的通用机器人模型GR00T N1在多个机器人形态的标准模拟基准测试中优于最先进的模仿学习基线。此外,我们将我们的模型部署在Fourier GR-1人形机器人上,用于语言条件下的双手动操作任务,以高数据效率实现了强大的性能。
🔬 方法详解
问题定义:现有机器人模型在泛化性和数据效率方面存在瓶颈。它们难以适应真实世界中复杂多变的场景,并且需要大量的训练数据才能学习新的任务。模仿学习方法虽然有效,但往往受限于训练数据的质量和多样性,难以实现真正的通用性。
核心思路:GR00T N1的核心思路是构建一个能够理解视觉和语言指令,并生成流畅运动动作的通用机器人模型。通过结合视觉-语言模块和扩散Transformer模块,模型能够将高层次的指令转化为低层次的运动控制,从而实现对复杂任务的自主执行。
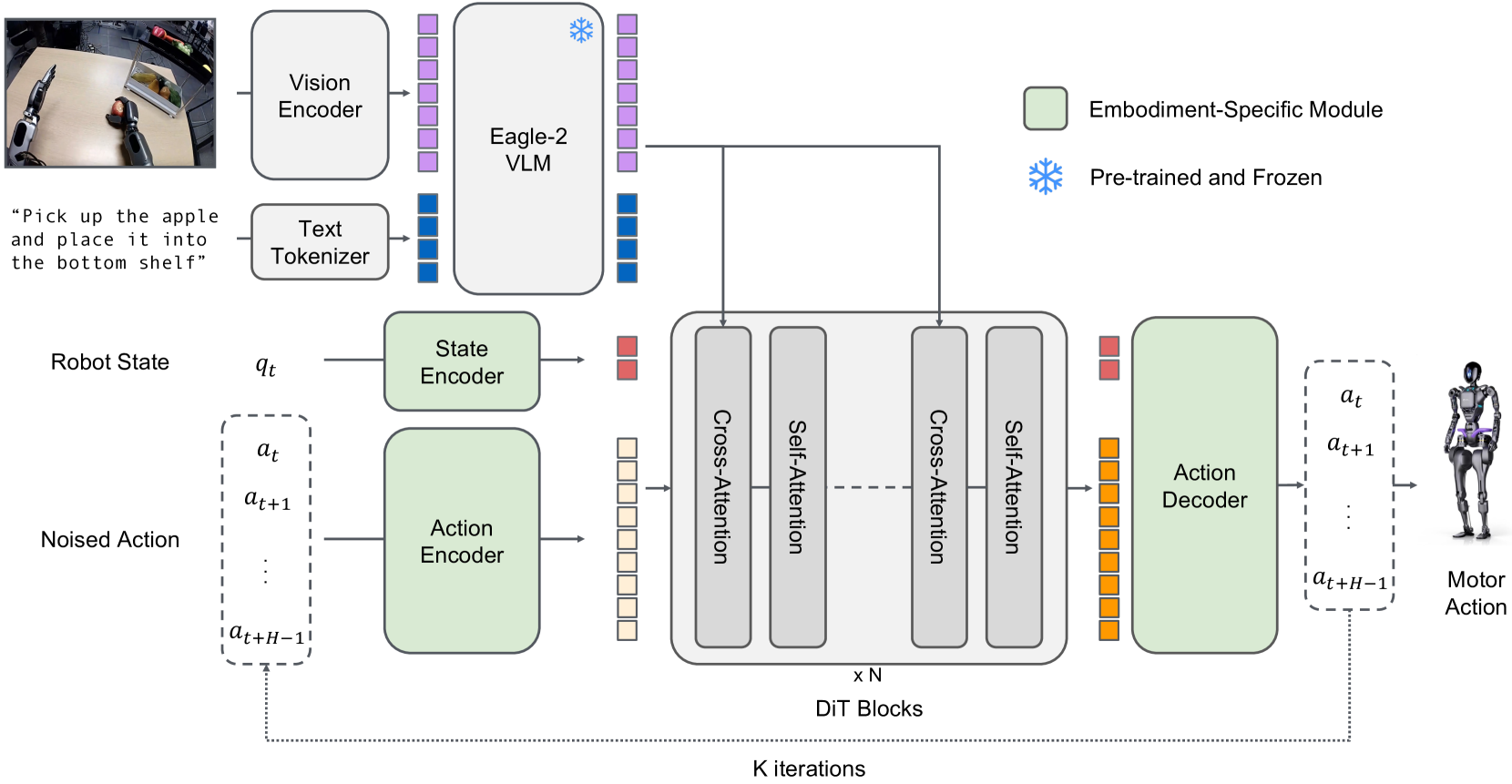
技术框架:GR00T N1采用双系统架构的视觉-语言-动作(VLA)模型。系统2是视觉-语言模块,负责接收视觉输入(例如摄像头图像)和语言指令,并理解环境和任务要求。系统1是扩散Transformer模块,负责根据系统2的输出,生成实时的运动动作。这两个模块紧密耦合,通过端到端的方式进行联合训练。训练数据包括真实机器人轨迹、人类视频和合成生成的数据集。
关键创新:GR00T N1的关键创新在于其双系统架构和端到端训练方式。视觉-语言模块和扩散Transformer模块的结合,使得模型能够同时处理高层次的语义信息和低层次的运动控制。端到端训练使得两个模块能够协同工作,从而实现更好的性能。此外,使用异构数据进行训练,提高了模型的泛化能力。
关键设计:GR00T N1的具体网络结构和参数设置在论文中未详细说明,属于未知信息。但可以推测,视觉-语言模块可能采用Transformer或类似的注意力机制,以处理视觉和语言输入。扩散Transformer模块可能采用扩散模型生成运动轨迹,并使用Transformer进行序列建模。损失函数可能包括模仿学习损失、强化学习损失以及其他正则化项。
🖼️ 关键图片

📊 实验亮点
GR00T N1在标准模拟基准测试中优于最先进的模仿学习基线,并在Fourier GR-1人形机器人上成功部署,实现了语言条件下的双手动操作任务。该模型具有高数据效率,能够在少量数据下实现强大的性能,表明其具有良好的泛化能力和适应性。具体性能数据未知,但结果表明GR00T N1是通用人形机器人领域的一个重要进展。
🎯 应用场景
GR00T N1有望应用于各种需要通用机器人自主性的场景,例如家庭服务、工业自动化、医疗保健和灾难救援。它可以帮助机器人理解人类指令,执行复杂任务,并在未知环境中安全有效地工作。未来的研究方向包括提高模型的鲁棒性、泛化能力和数据效率,以及探索更复杂的任务和环境。
📄 摘要(原文)
General-purpose robots need a versatile body and an intelligent mind. Recent advancements in humanoid robots have shown great promise as a hardware platform for building generalist autonomy in the human world. A robot foundation model, trained on massive and diverse data sources, is essential for enabling the robots to reason about novel situations, robustly handle real-world variability, and rapidly learn new tasks. To this end, we introduce GR00T N1, an open foundation model for humanoid robots. GR00T N1 is a Vision-Language-Action (VLA) model with a dual-system architecture. The vision-language module (System 2) interprets the environment through vision and language instructions. The subsequent diffusion transformer module (System 1) generates fluid motor actions in real time. Both modules are tightly coupled and jointly trained end-to-end. We train GR00T N1 with a heterogeneous mixture of real-robot trajectories, human videos, and synthetically generated datasets. We show that our generalist robot model GR00T N1 outperforms the state-of-the-art imitation learning baselines on standard simulation benchmarks across multiple robot embodiments. Furthermore, we deploy our model on the Fourier GR-1 humanoid robot for language-conditioned bimanual manipulation tasks, achieving strong performance with high data efficiency.