Reinforcement Learning-Based Neuroadaptive Control of Robotic Manipulators under Deferred Constraints
作者: Hamed Rahimi Nohooji, Abolfazl Zaraki, Holger Voos
分类: cs.RO, eess.SY
发布日期: 2025-03-18
备注: 7 pages, 5 figures
💡 一句话要点
提出基于强化学习的神经自适应控制,解决机器人操作臂在约束下的控制问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作臂 强化学习 神经自适应控制 约束控制 Actor-Critic 李雅普诺夫稳定性 平滑约束
📋 核心要点
- 传统方法在处理机器人操作臂的约束控制时,往往难以兼顾控制精度、能效和安全性。
- 该论文提出一种基于强化学习的神经自适应控制框架,通过平滑约束执行和Actor-Critic网络实现高效、安全的约束处理。
- 数值仿真验证了所提方法的有效性,表明其能够在满足约束条件的同时,提高能源效率和适应性。
📝 摘要(中文)
本文提出了一种基于强化学习的神经自适应控制框架,用于在延迟约束下运行的机器人操作臂。该方法改进了传统的障碍李雅普诺夫函数,引入了一种平滑的约束执行机制,具有两个关键优势:(i) 它最大限度地减少了无约束区域的控制工作,并在接近约束时逐步增加控制工作,从而提高了能源效率;(ii) 它通过规定的时间移位函数实现逐渐的约束激活,即使初始条件违反约束也能安全运行。为了解决系统不确定性并提高适应性,采用了一种Actor-Critic强化学习框架。评论家网络估计价值函数,而行动者网络实时学习最优控制策略,从而实现自适应约束处理,而无需显式系统建模。基于李雅普诺夫的稳定性分析保证了所有闭环信号的有界性。通过数值仿真验证了该方法的有效性。
🔬 方法详解
问题定义:论文旨在解决机器人操作臂在存在约束条件下的精确控制问题。现有方法,如传统的障碍李雅普诺夫函数,在无约束区域可能引入不必要的控制努力,导致能源效率低下。此外,当初始状态违反约束时,难以保证系统的安全性。
核心思路:论文的核心思路是结合平滑约束执行机制和强化学习,实现对机器人操作臂的自适应约束控制。平滑约束执行机制能够在无约束区域减少控制努力,并在接近约束时逐步增加控制努力,从而提高能源效率。强化学习则用于处理系统的不确定性,并学习最优控制策略。
技术框架:该框架采用Actor-Critic强化学习结构。Critic网络用于估计价值函数,评估当前状态的优劣;Actor网络则根据Critic网络的反馈,学习最优的控制策略。此外,框架还包含一个平滑约束执行模块,用于实现对约束的逐渐激活和控制。整体流程为:首先,Critic网络评估当前状态;然后,Actor网络根据Critic网络的评估结果,生成控制指令;最后,平滑约束执行模块对控制指令进行调整,以满足约束条件。
关键创新:论文的关键创新在于将平滑约束执行机制与Actor-Critic强化学习相结合。传统的障碍李雅普诺夫函数通常采用硬约束,容易导致控制信号的突变。而平滑约束执行机制则能够实现对约束的逐渐激活,从而避免控制信号的突变,提高系统的平稳性。此外,强化学习的使用使得系统能够自适应地处理不确定性,并学习最优的控制策略。
关键设计:论文中,平滑约束执行机制通过一个规定的时间移位函数来实现对约束的逐渐激活。Actor和Critic网络通常采用多层感知机(MLP)结构。损失函数的设计需要同时考虑控制性能和约束满足程度。具体的参数设置需要根据具体的机器人操作臂和约束条件进行调整。
🖼️ 关键图片

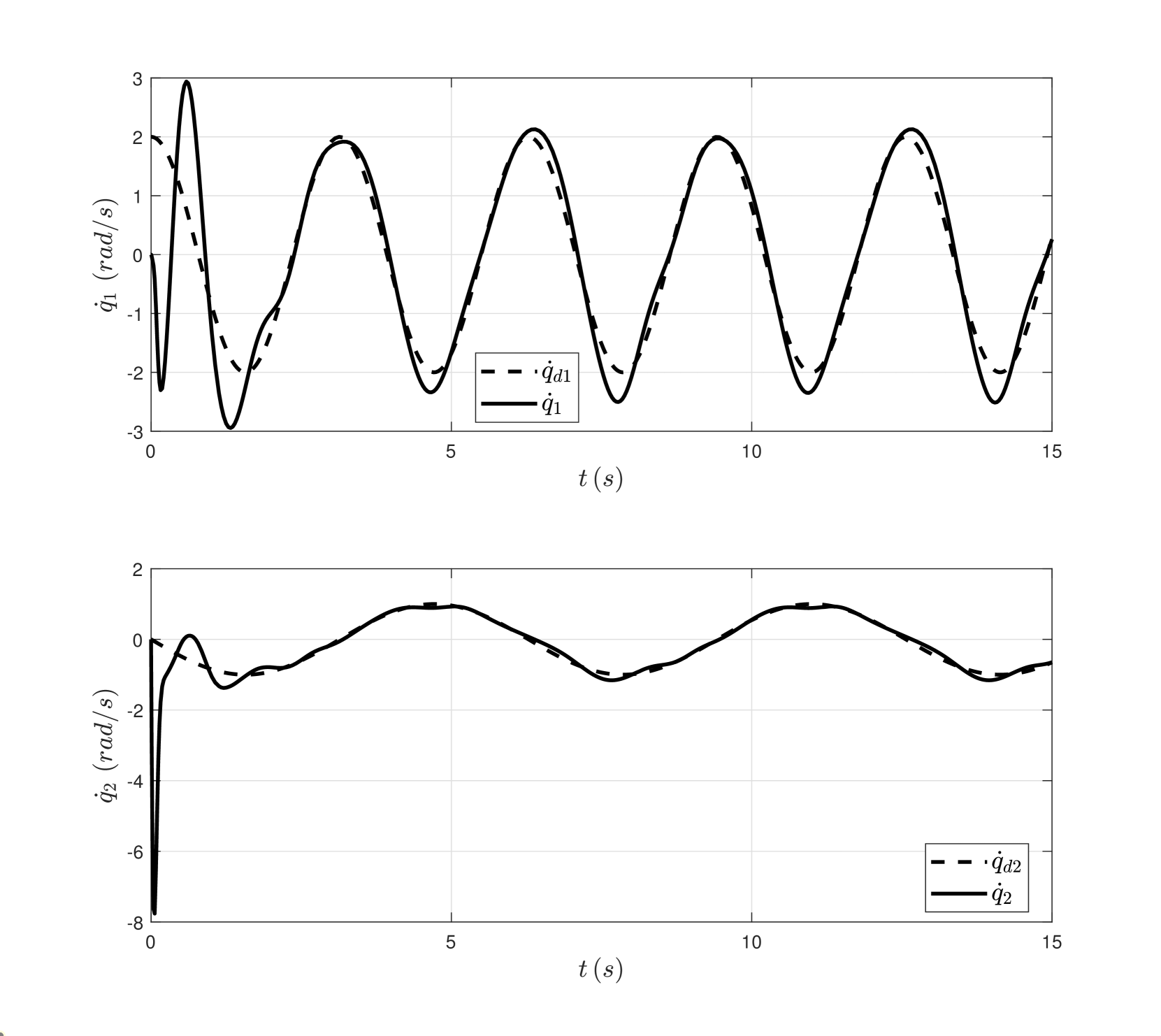
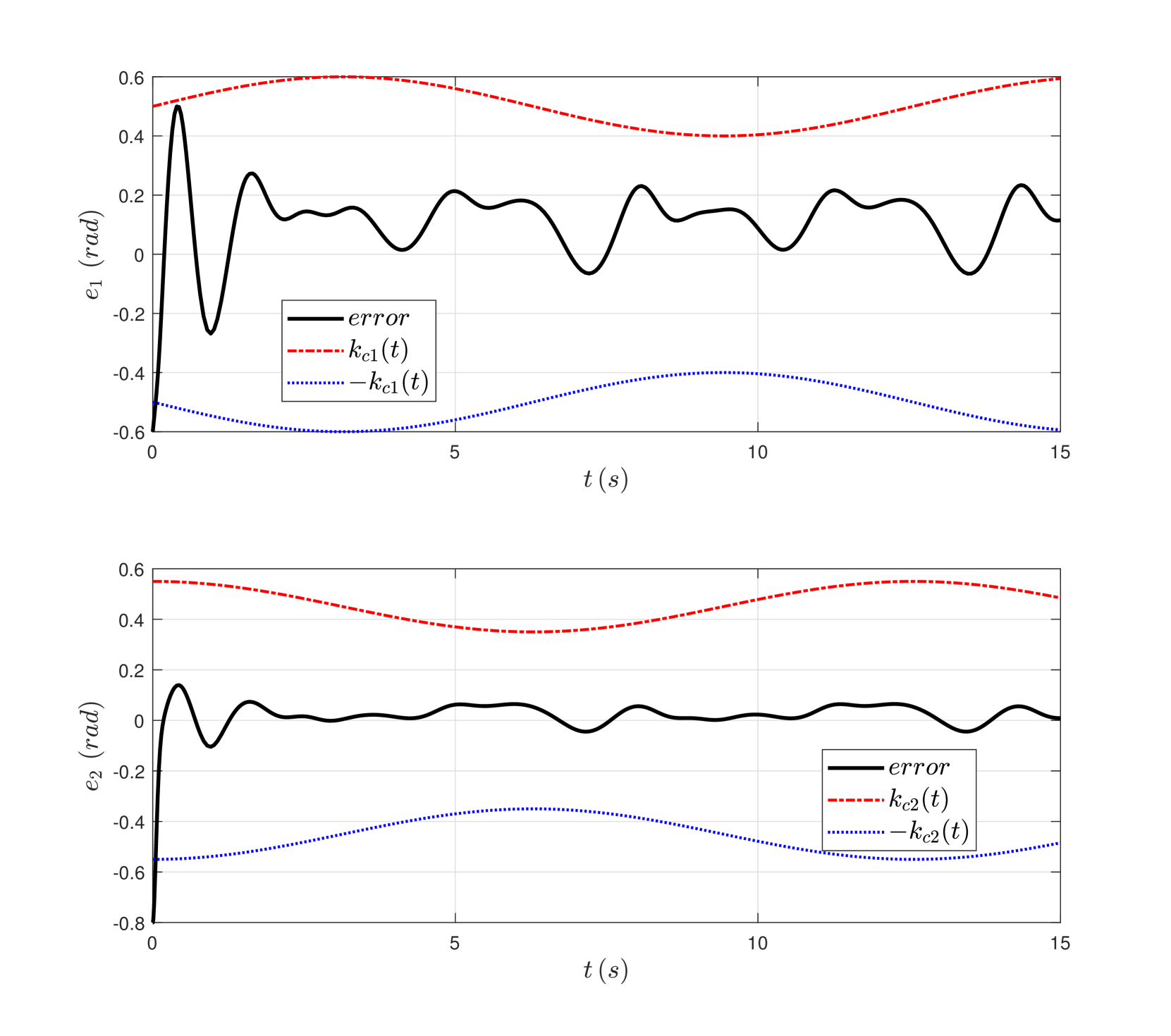
📊 实验亮点
论文通过数值仿真验证了所提方法的有效性。仿真结果表明,该方法能够在满足约束条件的同时,显著降低控制能量消耗,并提高系统的适应性。具体的性能数据(例如,能量消耗降低的百分比、约束违反的程度等)在论文中进行了详细的展示。
🎯 应用场景
该研究成果可应用于各种需要在约束条件下精确控制的机器人操作臂,例如:工业自动化中的装配机器人、医疗机器人中的手术辅助机器人、以及服务机器人中的人机协作机器人。该方法能够提高机器人的能源效率、安全性和适应性,从而提升机器人的整体性能和可靠性。
📄 摘要(原文)
This paper presents a reinforcement learning-based neuroadaptive control framework for robotic manipulators operating under deferred constraints. The proposed approach improves traditional barrier Lyapunov functions by introducing a smooth constraint enforcement mechanism that offers two key advantages: (i) it minimizes control effort in unconstrained regions and progressively increases it near constraints, improving energy efficiency, and (ii) it enables gradual constraint activation through a prescribed-time shifting function, allowing safe operation even when initial conditions violate constraints. To address system uncertainties and improve adaptability, an actor-critic reinforcement learning framework is employed. The critic network estimates the value function, while the actor network learns an optimal control policy in real time, enabling adaptive constraint handling without requiring explicit system modeling. Lyapunov-based stability analysis guarantees the boundedness of all closed-loop signals. The effectiveness of the proposed method is validated through numerical simulations.