MoManipVLA: Transferring Vision-language-action Models for General Mobile Manipulation
作者: Zhenyu Wu, Yuheng Zhou, Xiuwei Xu, Ziwei Wang, Haibin Yan
分类: cs.RO, cs.CV
发布日期: 2025-03-17
备注: Accepted to CVPR 2025. Project Page: https://gary3410.github.io/momanipVLA/
💡 一句话要点
MoManipVLA:迁移视觉-语言-动作模型至通用移动操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 移动操作 视觉-语言-动作模型 迁移学习 双层优化 机器人运动规划
📋 核心要点
- 传统移动操作方法因缺乏大规模训练,难以在不同任务和环境中泛化,限制了其应用。
- MoManipVLA通过迁移预训练的固定基座VLA模型,并结合双层优化框架,实现了移动操作策略的高泛化能力。
- 实验表明,MoManipVLA在成功率上优于现有方法,并显著降低了真实世界部署所需的训练成本。
📝 摘要(中文)
移动操作是机器人辅助人类完成日常任务和适应各种环境的关键挑战。然而,由于缺乏大规模训练,传统的移动操作方法难以在不同任务和环境中泛化。相比之下,视觉-语言-动作(VLA)模型展现了卓越的泛化能力,但这些基础模型是为固定基座操作任务设计的。因此,我们提出了一个名为MoManipVLA的高效策略自适应框架,将预训练的固定基座操作VLA模型迁移到移动操作,从而在移动操作策略中实现跨任务和环境的高泛化能力。具体而言,我们利用预训练的VLA模型生成具有高泛化能力的末端执行器航点。我们为移动底座和机器人手臂设计了运动规划目标,旨在最大化轨迹的物理可行性。最后,我们提出了一个高效的双层目标优化框架用于轨迹生成,其中上层优化预测底座运动的航点以增强机械臂策略空间,下层优化选择最佳末端执行器轨迹以完成操作任务。通过这种方式,MoManipVLA可以以零样本方式调整机器人底座的位置,从而使固定基座VLA模型预测的航点可行。在OVMM和真实世界中的大量实验结果表明,MoManipVLA比最先进的移动操作方法实现了高4.2%的成功率,并且由于预训练VLA模型中强大的泛化能力,真实世界部署仅需50次训练成本。
🔬 方法详解
问题定义:论文旨在解决移动操作任务中,现有方法泛化能力不足的问题。传统方法依赖于特定任务的训练数据,难以适应新的环境和任务。固定基座的VLA模型虽然具有良好的泛化能力,但无法直接应用于移动操作。
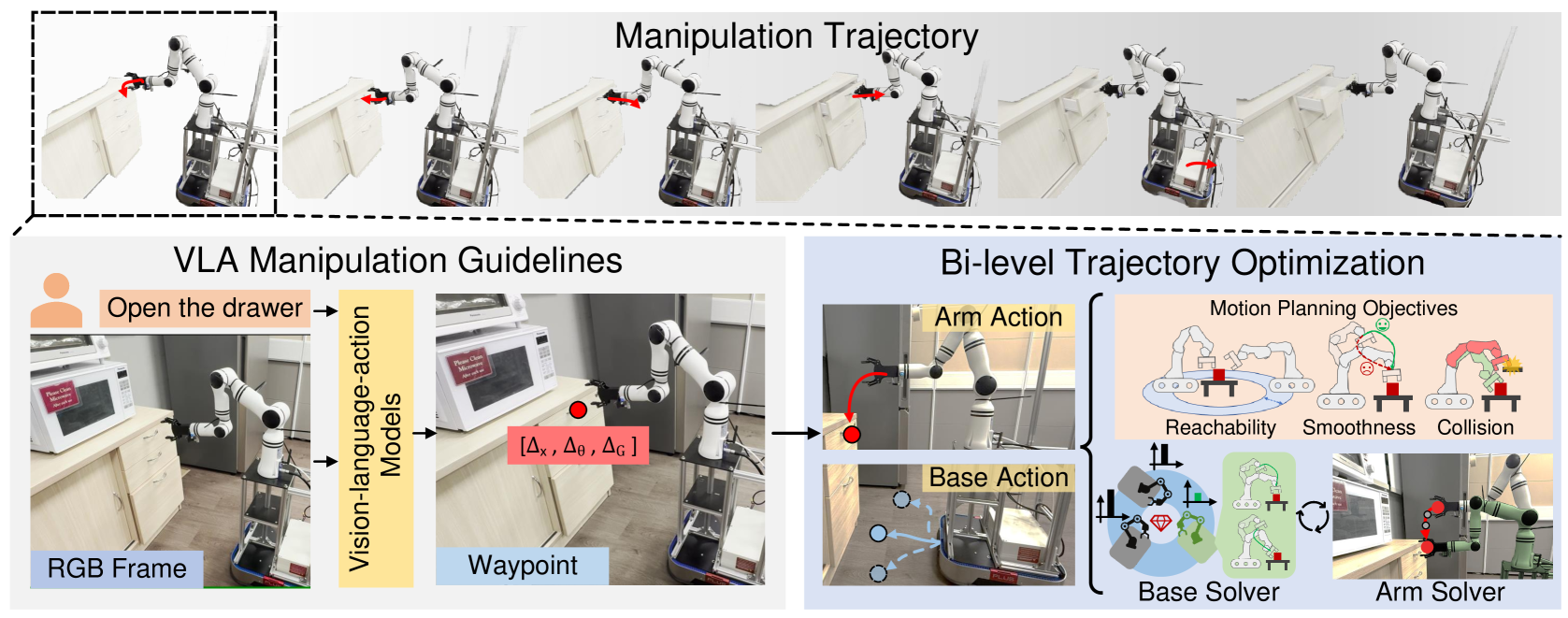
核心思路:论文的核心思路是将预训练的固定基座VLA模型的泛化能力迁移到移动操作任务中。通过调整机器人底座的位置,使得固定基座VLA模型预测的末端执行器航点在移动操作中可行。这避免了从头开始训练移动操作策略,并利用了现有VLA模型的知识。
技术框架:MoManipVLA框架包含以下几个主要模块:1) 利用预训练VLA模型生成末端执行器的航点;2) 设计移动底座和机器人手臂的运动规划目标,以最大化轨迹的物理可行性;3) 采用双层优化框架进行轨迹生成,上层优化预测底座运动的航点,下层优化选择最佳末端执行器轨迹。
关键创新:该方法最重要的创新点在于将固定基座VLA模型的知识迁移到移动操作任务中,并提出了一个双层优化框架来实现底座位置的调整。与现有方法相比,MoManipVLA无需从头开始训练移动操作策略,而是利用了预训练模型的泛化能力,从而提高了效率和泛化性能。
关键设计:双层优化框架是关键设计之一。上层优化目标是预测底座运动的航点,以增强机械臂策略空间。下层优化目标是选择最佳末端执行器轨迹,以完成操作任务。运动规划目标的设计旨在最大化轨迹的物理可行性,例如避免碰撞、限制关节运动范围等。具体的参数设置和损失函数细节在论文中进行了详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
MoManipVLA在OVMM和真实世界实验中均取得了显著成果。在OVMM数据集上,MoManipVLA的成功率比现有最先进的移动操作方法高4.2%。更重要的是,由于预训练VLA模型强大的泛化能力,MoManipVLA在真实世界部署中仅需50次训练迭代,大大降低了部署成本。
🎯 应用场景
该研究成果可广泛应用于各种需要移动操作的场景,例如家庭服务机器人、仓库自动化、医疗辅助机器人等。通过利用预训练VLA模型的泛化能力,可以降低机器人部署的成本和难度,使其能够更好地适应不同的任务和环境。未来,该方法有望进一步扩展到更复杂的移动操作任务中。
📄 摘要(原文)
Mobile manipulation is the fundamental challenge for robotics to assist humans with diverse tasks and environments in everyday life. However, conventional mobile manipulation approaches often struggle to generalize across different tasks and environments because of the lack of large-scale training. In contrast, recent advances in vision-language-action (VLA) models have shown impressive generalization capabilities, but these foundation models are developed for fixed-base manipulation tasks. Therefore, we propose an efficient policy adaptation framework named MoManipVLA to transfer pre-trained VLA models of fix-base manipulation to mobile manipulation, so that high generalization ability across tasks and environments can be achieved in mobile manipulation policy. Specifically, we utilize pre-trained VLA models to generate waypoints of the end-effector with high generalization ability. We design motion planning objectives for the mobile base and the robot arm, which aim at maximizing the physical feasibility of the trajectory. Finally, we present an efficient bi-level objective optimization framework for trajectory generation, where the upper-level optimization predicts waypoints for base movement to enhance the manipulator policy space, and the lower-level optimization selects the optimal end-effector trajectory to complete the manipulation task. In this way, MoManipVLA can adjust the position of the robot base in a zero-shot manner, thus making the waypoints predicted from the fixed-base VLA models feasible. Extensive experimental results on OVMM and the real world demonstrate that MoManipVLA achieves a 4.2% higher success rate than the state-of-the-art mobile manipulation, and only requires 50 training cost for real world deployment due to the strong generalization ability in the pre-trained VLA models.