Dense Policy: Bidirectional Autoregressive Learning of Actions
作者: Yue Su, Xinyu Zhan, Hongjie Fang, Han Xue, Hao-Shu Fang, Yong-Lu Li, Cewu Lu, Lixin Yang
分类: cs.RO, cs.CV, cs.LG
发布日期: 2025-03-17
💡 一句话要点
提出Dense Policy双向自回归学习动作,提升机器人操作策略。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 机器人操作 自回归策略 动作预测 双向学习 深度学习
📋 核心要点
- 现有视觉运动策略依赖生成模型,自回归策略效果不佳,限制了机器人操作的性能。
- Dense Policy采用双向扩展学习,以轻量级编码器架构实现由粗到精的动作序列预测。
- 实验表明,Dense Policy具有更强的自回归学习能力,优于现有的整体生成策略。
📝 摘要(中文)
主流的视觉运动策略主要依赖于生成模型进行整体动作预测,而现有的自回归策略(预测下一个token或chunk)效果欠佳。这促使我们寻找更有效的学习方法,以释放自回归策略在机器人操作中的潜力。本文提出了一种双向扩展学习方法,称为Dense Policy,为动作预测中的自回归策略建立了一种新的范例。它采用轻量级的仅编码器架构,以对数时间推理的方式,从初始单帧迭代地将动作序列展开为目标序列,实现由粗到精的预测。大量实验验证了我们的Dense Policy具有卓越的自回归学习能力,并且可以超越现有的整体生成策略。我们的策略、示例数据和训练代码将在发布后公开。
🔬 方法详解
问题定义:论文旨在解决机器人操作中,现有自回归策略在动作预测方面表现不佳的问题。现有的自回归策略通常预测单个token或chunk,缺乏对整体动作序列的建模能力,导致性能受限。此外,主流的整体生成模型虽然能预测完整动作,但缺乏对动作序列内部依赖关系的有效利用。
核心思路:论文的核心思路是提出一种双向扩展学习方法,即Dense Policy,以迭代的方式逐步完善动作序列的预测。通过从初始单帧出发,双向地、由粗到精地展开动作序列,从而更好地捕捉动作序列内部的依赖关系,提升预测精度。这种方法旨在充分利用自回归模型的优势,同时克服其在动作预测中的局限性。
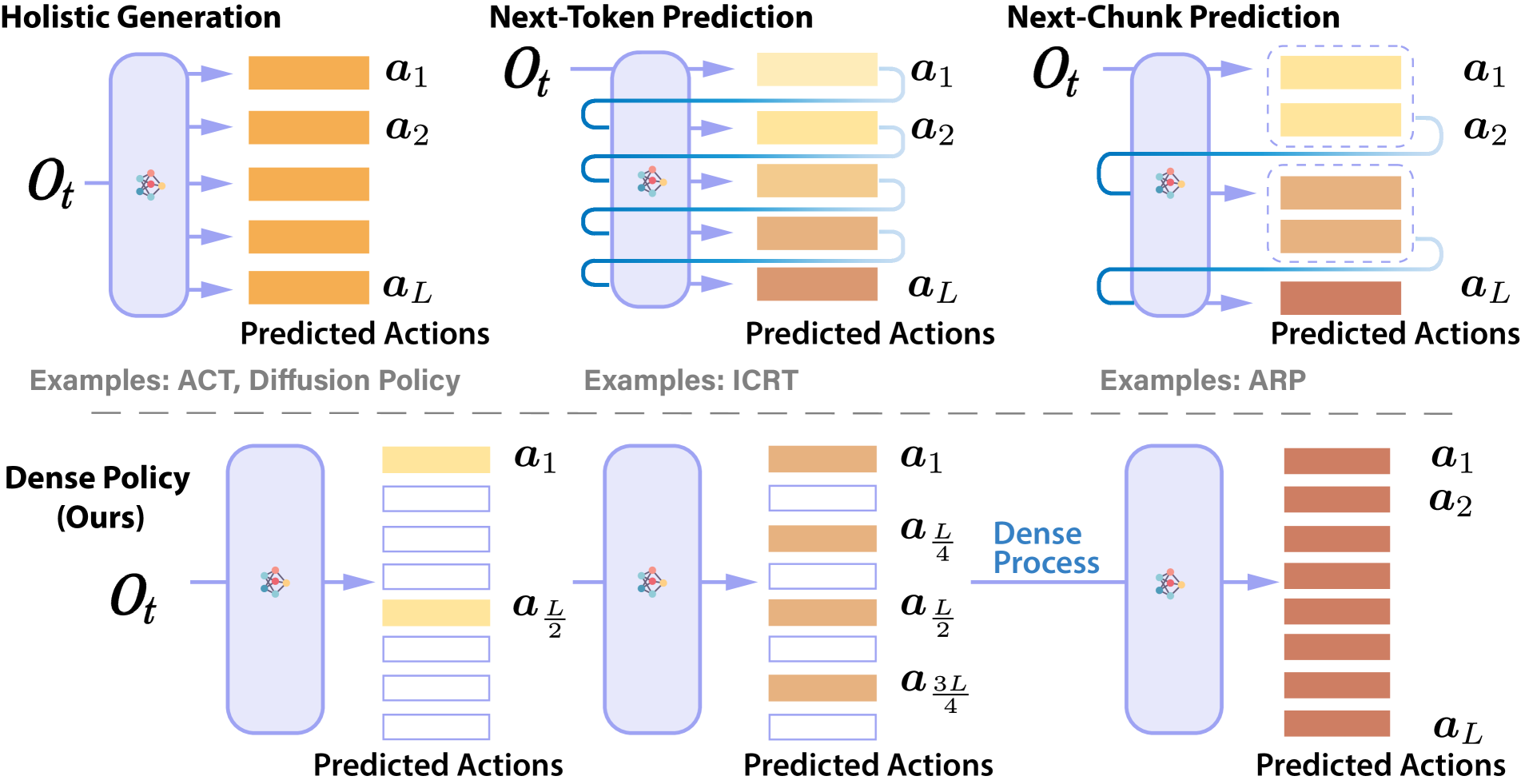
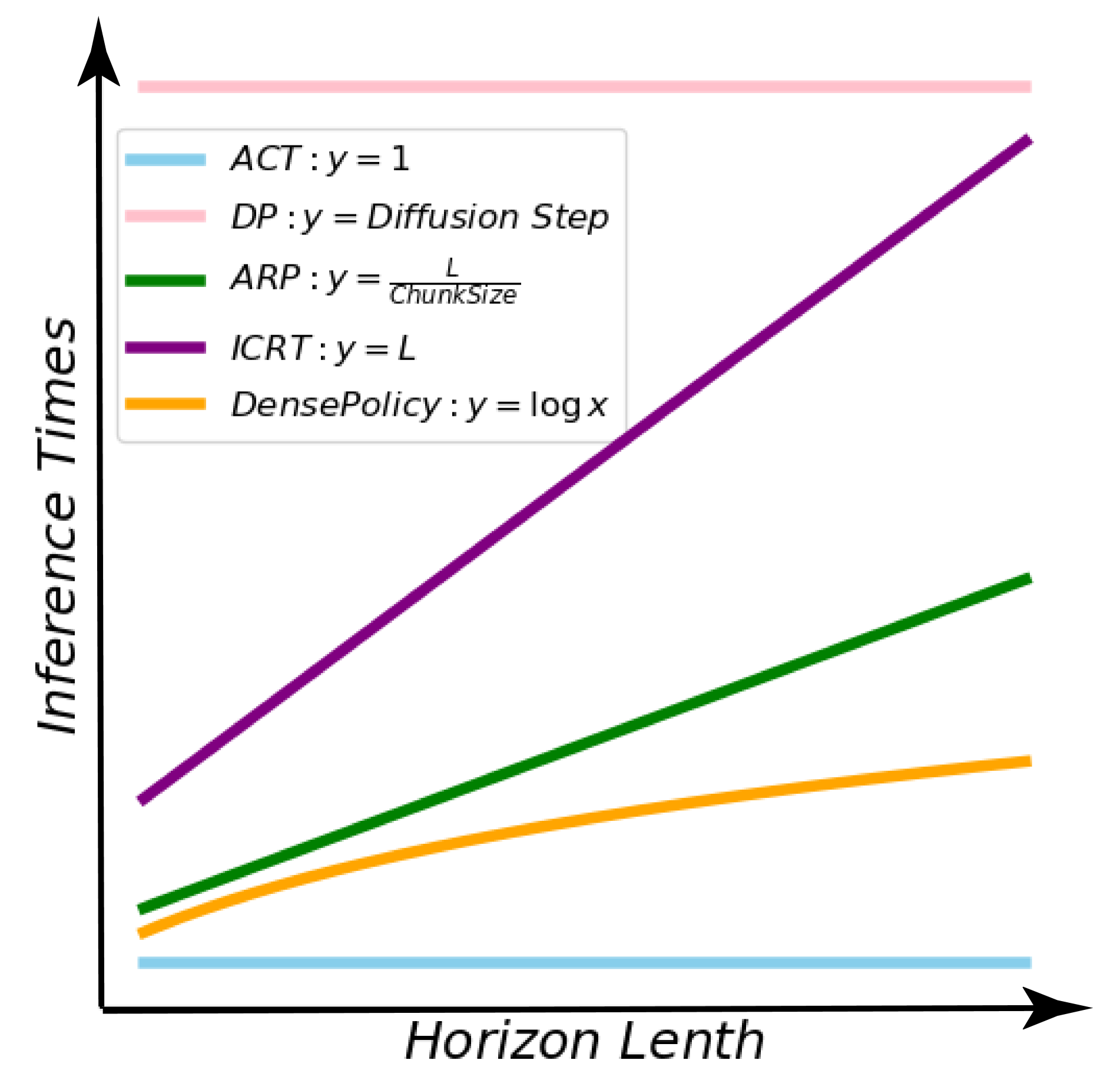
技术框架:Dense Policy采用一种轻量级的仅编码器架构。整体流程如下:1)输入初始单帧图像;2)编码器提取图像特征;3)自回归解码器基于图像特征和已预测的动作序列,预测下一个动作;4)双向扩展模块将预测的动作插入到已有的动作序列中,形成新的动作序列;5)重复步骤3和4,直到生成完整的动作序列。整个过程以对数时间复杂度进行推理,实现高效的动作预测。
关键创新:Dense Policy的关键创新在于其双向扩展学习方法。与传统的自回归模型单向预测不同,Dense Policy允许模型在动作序列的任意位置插入新的动作,从而实现更灵活、更高效的序列生成。此外,由粗到精的预测方式也使得模型能够逐步完善动作序列,避免了早期预测错误对后续预测的影响。
关键设计:Dense Policy采用Transformer编码器作为其核心组件。损失函数方面,论文可能采用了交叉熵损失或均方误差损失,具体细节未知。在训练过程中,可能使用了数据增强等技术来提高模型的泛化能力。具体的网络结构参数和训练细节将在论文发布后公开。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Dense Policy在动作预测任务中取得了显著的性能提升,超越了现有的整体生成策略。具体的性能数据和对比基线将在论文发布后公开。该方法验证了双向自回归学习在机器人操作中的有效性,为未来的研究提供了新的方向。
🎯 应用场景
Dense Policy在机器人操作领域具有广泛的应用前景,例如自动化装配、物体抓取、复杂操作任务等。该方法可以提高机器人在复杂环境中的操作精度和效率,降低对人工干预的依赖,从而推动机器人技术在工业、医疗、服务等领域的应用。
📄 摘要(原文)
Mainstream visuomotor policies predominantly rely on generative models for holistic action prediction, while current autoregressive policies, predicting the next token or chunk, have shown suboptimal results. This motivates a search for more effective learning methods to unleash the potential of autoregressive policies for robotic manipulation. This paper introduces a bidirectionally expanded learning approach, termed Dense Policy, to establish a new paradigm for autoregressive policies in action prediction. It employs a lightweight encoder-only architecture to iteratively unfold the action sequence from an initial single frame into the target sequence in a coarse-to-fine manner with logarithmic-time inference. Extensive experiments validate that our dense policy has superior autoregressive learning capabilities and can surpass existing holistic generative policies. Our policy, example data, and training code will be publicly available upon publication. Project page: https: //selen-suyue.github.io/DspNet/.