VISO-Grasp: Vision-Language Informed Spatial Object-centric 6-DoF Active View Planning and Grasping in Clutter and Invisibility
作者: Yitian Shi, Di Wen, Guanqi Chen, Edgar Welte, Sheng Liu, Kunyu Peng, Rainer Stiefelhagen, Rania Rayyes
分类: cs.RO, cs.CV
发布日期: 2025-03-16 (更新: 2025-08-06)
备注: Accepted to IROS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
VISO-Grasp:利用视觉-语言信息在严重遮挡下进行6自由度主动视图规划和抓取
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人抓取 视觉-语言模型 主动视图规划 6自由度抓取 遮挡处理 空间推理 目标导向抓取
📋 核心要点
- 现有方法在严重遮挡环境下进行物体抓取时,缺乏对空间关系的有效建模和利用,导致抓取成功率低。
- VISO-Grasp利用视觉-语言基础模型进行空间推理和主动视图规划,构建实例中心的空间关系表示,优化抓取策略。
- 实验表明,VISO-Grasp在真实场景中实现了87.5%的抓取成功率,优于现有基线方法,且抓取尝试次数更少。
📝 摘要(中文)
我们提出了VISO-Grasp,一种新颖的视觉-语言信息系统,旨在系统地解决严重遮挡环境中抓取的可见性约束。通过利用基础模型(FMs)进行空间推理和主动视图规划,我们的框架构建并更新以实例为中心的空间关系表示,从而提高在具有挑战性的遮挡下的抓取成功率。此外,这种表示促进了主动的Next-Best-View(NBV)规划,并在直接抓取不可行时优化顺序抓取策略。此外,我们引入了一种多视图不确定性驱动的抓取融合机制,可以实时细化抓取置信度和方向不确定性,从而确保鲁棒和稳定的抓取执行。大量的真实世界实验表明,VISO-Grasp在目标导向抓取中实现了87.5%的成功率,并且抓取尝试次数最少,优于基线方法。据我们所知,VISO-Grasp是第一个将FMs集成到目标感知主动视图规划和6自由度抓取中的统一框架,适用于具有严重遮挡和完全不可见约束的环境。代码可在https://github.com/YitianShi/vMF-Contact上找到。
🔬 方法详解
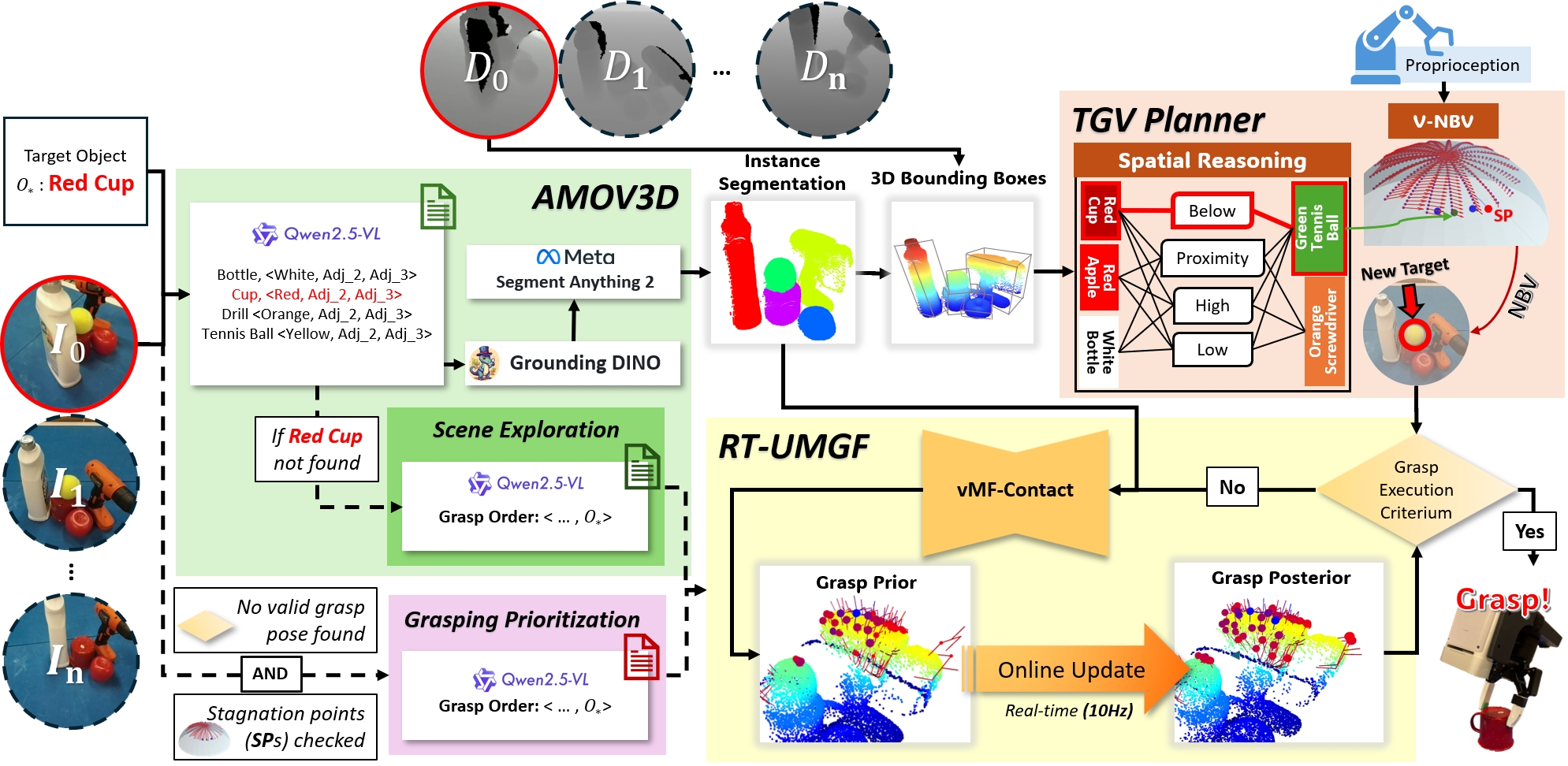
问题定义:论文旨在解决在严重遮挡和完全不可见约束下,机器人如何有效地进行目标导向的6自由度物体抓取。现有方法在处理此类问题时,通常难以准确估计被遮挡物体的姿态,并且缺乏主动探索未知区域的能力,导致抓取成功率较低。
核心思路:论文的核心思路是利用视觉-语言基础模型(FMs)进行空间推理,结合主动视图规划(Active View Planning)策略,构建一个以实例为中心的空间关系表示。通过不断更新和优化对场景的理解,系统能够选择最佳的观察视角和抓取姿态,从而提高在复杂环境下的抓取成功率。
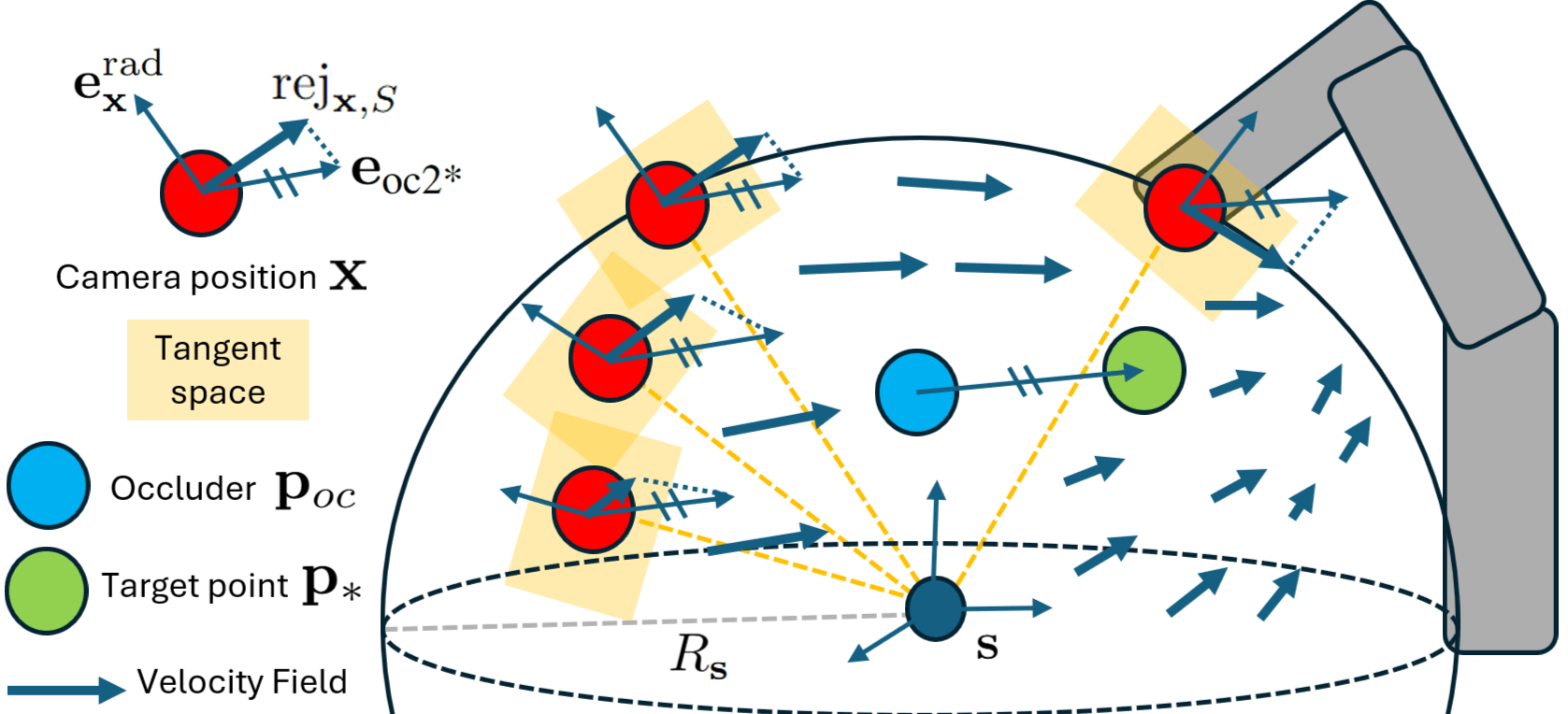
技术框架:VISO-Grasp框架主要包含以下几个模块:1) 场景感知模块:利用视觉信息和语言描述,提取场景中的物体信息和空间关系。2) 空间推理模块:利用基础模型(FMs)对场景进行空间推理,估计被遮挡物体的姿态和位置。3) 主动视图规划模块:根据当前场景的理解,选择下一个最佳观察视角(NBV),以减少不确定性。4) 抓取规划模块:根据场景理解和物体姿态估计,生成候选抓取姿态。5) 抓取融合模块:融合来自不同视角的抓取信息,提高抓取置信度。
关键创新:VISO-Grasp的关键创新在于将视觉-语言基础模型(FMs)集成到目标感知的6自由度抓取框架中,并结合主动视图规划策略。这是首次在严重遮挡和完全不可见约束下,实现高效的物体抓取。此外,多视图不确定性驱动的抓取融合机制也是一个重要的创新点,它能够有效地提高抓取的鲁棒性和稳定性。
关键设计:论文中关键的设计包括:1) 使用特定的视觉-语言基础模型进行空间推理,模型的选择和训练细节未知。2) 主动视图规划策略的具体实现方式,例如如何定义“最佳”观察视角,以及如何选择下一个视角。3) 多视图抓取融合机制的具体实现,例如如何计算抓取置信度和方向不确定性,以及如何进行融合。4) 损失函数的设计,用于优化整个框架的性能,具体形式未知。
🖼️ 关键图片

📊 实验亮点
VISO-Grasp在真实世界实验中取得了显著成果,在目标导向抓取任务中达到了87.5%的成功率,显著优于现有基线方法。此外,VISO-Grasp还能够以最少的抓取尝试次数完成任务,表明其具有更高的效率和鲁棒性。这些实验结果充分证明了VISO-Grasp在解决严重遮挡环境下的物体抓取问题方面的有效性。
🎯 应用场景
VISO-Grasp技术可应用于自动化仓库、家庭服务机器人、医疗辅助机器人等领域。在这些场景中,机器人需要在复杂、拥挤的环境中抓取物体,而遮挡和不可见性是常见的问题。该技术能够提高机器人在这些场景中的操作效率和可靠性,具有重要的实际应用价值和广阔的发展前景。
📄 摘要(原文)
We propose VISO-Grasp, a novel vision-language-informed system designed to systematically address visibility constraints for grasping in severely occluded environments. By leveraging Foundation Models (FMs) for spatial reasoning and active view planning, our framework constructs and updates an instance-centric representation of spatial relationships, enhancing grasp success under challenging occlusions. Furthermore, this representation facilitates active Next-Best-View (NBV) planning and optimizes sequential grasping strategies when direct grasping is infeasible. Additionally, we introduce a multi-view uncertainty-driven grasp fusion mechanism that refines grasp confidence and directional uncertainty in real-time, ensuring robust and stable grasp execution. Extensive real-world experiments demonstrate that VISO-Grasp achieves a success rate of $87.5\%$ in target-oriented grasping with the fewest grasp attempts outperforming baselines. To the best of our knowledge, VISO-Grasp is the first unified framework integrating FMs into target-aware active view planning and 6-DoF grasping in environments with severe occlusions and entire invisibility constraints. Code is available at: https://github.com/YitianShi/vMF-Contact