TERL: Large-Scale Multi-Target Encirclement Using Transformer-Enhanced Reinforcement Learning
作者: Heng Zhang, Guoxiang Zhao, Xiaoqiang Ren
分类: cs.RO, cs.LG
发布日期: 2025-03-16 (更新: 2025-08-27)
备注: Accepted to the 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2025)
🔗 代码/项目: GITHUB
💡 一句话要点
提出TERL,利用Transformer增强强化学习解决大规模多目标围捕问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多机器人系统 强化学习 Transformer网络 多目标围捕 追逃问题
📋 核心要点
- 现有强化学习方法在多机器人追逃问题中,主要集中于单目标追捕,缺乏对大规模多目标围捕问题的有效解决。
- TERL框架通过Transformer网络学习目标间的关系,并结合目标选择机制,使机器人能够自适应地选择目标并协同围捕。
- 实验表明,TERL在围捕成功率和任务完成时间上优于现有方法,并能从小规模场景泛化到大规模场景,无需重新训练。
📝 摘要(中文)
本文提出了一种用于大规模多目标围捕的Transformer增强强化学习(TERL)框架。针对多机器人系统中追逃问题的挑战,现有研究主要集中于单目标追捕,对大规模多目标围捕的探索有限。TERL通过集成基于Transformer的策略网络与目标选择机制,使机器人能够自适应地确定目标优先级并安全地进行协同。实验结果表明,TERL在围捕成功率和任务完成时间方面优于现有的基于强化学习的方法,同时在大规模场景中保持良好的性能。值得注意的是,TERL在小规模场景(15个追捕者,4个目标)下训练后,无需重新训练即可有效地泛化到大规模场景(80个追捕者,20个目标),并实现了100%的成功率。代码和演示视频可在https://github.com/ApricityZ/TERL获取。
🔬 方法详解
问题定义:论文旨在解决大规模多目标围捕问题,即在多机器人系统中,如何控制多个追捕者有效地围捕多个目标。现有方法的痛点在于难以处理大规模场景下的复杂交互和目标选择问题,尤其是在目标数量增加时,协同效率显著下降。
核心思路:论文的核心思路是利用Transformer网络学习目标之间的关系,并将其融入强化学习策略中,从而使追捕者能够更好地理解全局环境,自适应地选择目标,并进行协同围捕。Transformer的自注意力机制能够有效地捕捉目标之间的依赖关系,指导追捕者进行更有效的决策。
技术框架:TERL框架包含以下主要模块:1) 环境建模:将环境信息(包括追捕者和目标的位置)编码成状态表示;2) 基于Transformer的策略网络:利用Transformer网络学习状态表示,并输出每个追捕者的动作概率分布;3) 目标选择机制:根据策略网络的输出,选择当前追捕者应该围捕的目标;4) 强化学习训练:使用强化学习算法(如PPO)训练策略网络,使其能够最大化围捕成功率。
关键创新:该论文最重要的技术创新点在于将Transformer网络引入到多目标围捕的强化学习框架中。与传统的基于卷积神经网络或循环神经网络的方法相比,Transformer网络能够更好地捕捉目标之间的全局依赖关系,从而提高围捕效率和成功率。此外,目标选择机制也起到了关键作用,它能够引导追捕者选择合适的围捕目标,避免资源浪费和冲突。
关键设计:在Transformer网络的设计上,论文采用了多头自注意力机制,以捕捉不同角度的目标关系。损失函数方面,论文采用了PPO算法中的裁剪损失函数,以保证训练的稳定性。目标选择机制采用了一种基于策略网络输出的概率选择方法,使得追捕者能够根据当前状态选择最有利的目标。
🖼️ 关键图片

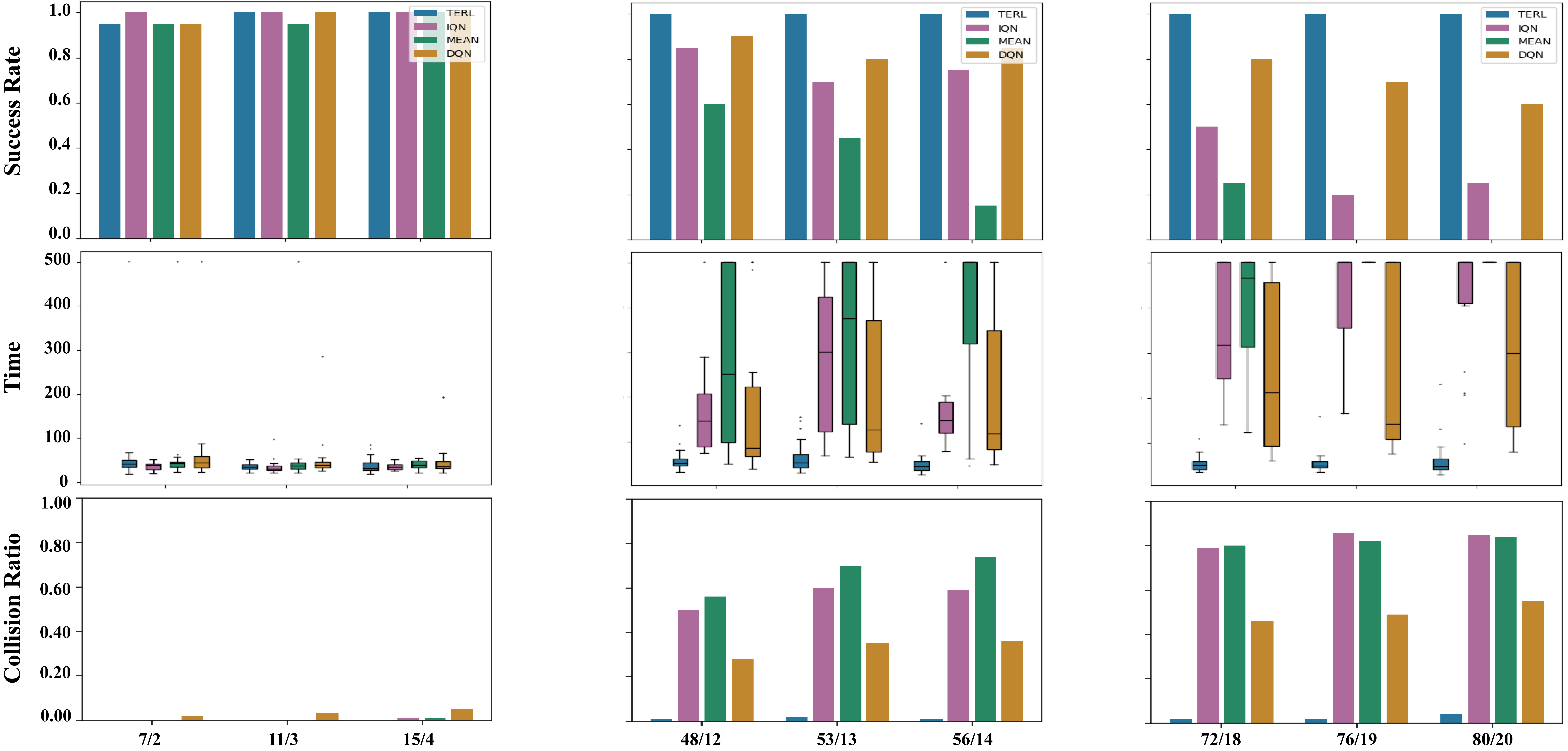
📊 实验亮点
实验结果表明,TERL在围捕成功率和任务完成时间方面显著优于现有的基于强化学习的方法。在小规模场景(15个追捕者,4个目标)下训练的TERL模型,无需重新训练即可有效地泛化到大规模场景(80个追捕者,20个目标),并实现了100%的成功率。这表明TERL具有良好的泛化能力和可扩展性。
🎯 应用场景
该研究具有广泛的应用前景,例如在安防监控领域,可以用于控制无人机群对入侵者进行围捕;在智能交通领域,可以用于控制车辆对违规车辆进行拦截;在机器人足球比赛中,可以用于控制机器人团队对敌方球员进行包围。此外,该方法还可以应用于其他多智能体协同任务中,例如资源分配、任务调度等。
📄 摘要(原文)
Pursuit-evasion (PE) problem is a critical challenge in multi-robot systems (MRS). While reinforcement learning (RL) has shown its promise in addressing PE tasks, research has primarily focused on single-target pursuit, with limited exploration of multi-target encirclement, particularly in large-scale settings. This paper proposes a Transformer-Enhanced Reinforcement Learning (TERL) framework for large-scale multi-target encirclement. By integrating a transformer-based policy network with target selection, TERL enables robots to adaptively prioritize targets and safely coordinate robots. Results show that TERL outperforms existing RL-based methods in terms of encirclement success rate and task completion time, while maintaining good performance in large-scale scenarios. Notably, TERL, trained on small-scale scenarios (15 pursuers, 4 targets), generalizes effectively to large-scale settings (80 pursuers, 20 targets) without retraining, achieving a 100% success rate. The code and demonstration video are available at https://github.com/ApricityZ/TERL.