A Benchmarking Study of Vision-based Robotic Grasping Algorithms
作者: Bharath K Rameshbabu, Sumukh S Balakrishna, Brian Flynn, Vinarak Kapoor, Adam Norton, Holly Yanco, Berk Calli
分类: cs.RO, cs.CV
发布日期: 2025-03-14 (更新: 2025-10-02)
备注: This work was intended as a replacement of arXiv:2307.11622. I will upload it as a replacement to arXiv:2307.11622 simultaneously
💡 一句话要点
对基于视觉的机器人抓取算法进行基准测试与对比分析,揭示不同算法在不同条件下的优劣。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 机器人抓取 视觉伺服 基准测试 机器学习 实验分析 机器人操作 性能评估
📋 核心要点
- 现有基于视觉的机器人抓取算法在不同环境和硬件条件下的性能表现缺乏系统性的对比分析。
- 通过构建包含多种实验条件(光照、背景、相机噪声、夹爪)的基准测试,全面评估不同算法的优劣。
- 在模拟和真实机器人上进行大量实验,并分析两者之间的差异,同时验证结果的可重复性。
📝 摘要(中文)
本文对基于视觉的机器人抓取算法进行了基准测试研究,并提供了对比分析。具体而言,我们使用文献中现有的基准测试协议,比较了两种基于机器学习的算法和两种解析算法,并确定了这些算法在不同实验条件下的优缺点。这些条件包括光照变化、背景纹理、具有不同噪声水平的相机和夹爪。我们还在模拟和真实机器人上进行了类似的实验,并展示了差异。一些实验也在两个不同的实验室中使用相同的协议进行,以进一步分析结果的可重复性。我们相信,这项包含5040个实验的研究,为机器人操作中系统实验的作用和挑战提供了重要的见解,并通过考虑可能影响性能的因素来指导新算法的开发。实验记录和我们的基准测试软件已公开。
🔬 方法详解
问题定义:论文旨在解决如何系统性地评估和比较不同的基于视觉的机器人抓取算法的问题。现有方法缺乏在不同实验条件下的全面评估,难以确定算法的适用性和鲁棒性。不同算法在真实环境中的性能差异也缺乏深入研究。
核心思路:论文的核心思路是构建一个全面的基准测试平台,包含多种实验条件(光照、背景、相机噪声、夹爪等),并使用统一的评估指标,对不同的抓取算法进行系统性的比较分析。通过在模拟和真实机器人上进行实验,揭示算法在不同环境下的性能差异,并分析影响性能的关键因素。
技术框架:该研究的技术框架主要包括以下几个部分:1) 选择具有代表性的基于视觉的机器人抓取算法,包括基于机器学习的方法和解析方法;2) 构建包含多种实验条件的基准测试平台,涵盖光照变化、背景纹理、相机噪声、夹爪类型等;3) 在模拟和真实机器人上进行大量实验,记录实验数据;4) 使用统一的评估指标(如抓取成功率)对实验结果进行分析和比较;5) 分析模拟和真实环境之间的差异,并探讨影响算法性能的关键因素。
关键创新:该研究的关键创新在于构建了一个全面的基准测试平台,并使用该平台对不同的基于视觉的机器人抓取算法进行了系统性的比较分析。该研究不仅揭示了不同算法在不同实验条件下的优缺点,还分析了模拟和真实环境之间的差异,为机器人抓取算法的开发和应用提供了重要的指导。
关键设计:实验设计中考虑了多种因素,包括:1) 光照条件:改变环境光照强度和方向;2) 背景纹理:使用不同的背景纹理,包括简单纹理和复杂纹理;3) 相机噪声:使用具有不同噪声水平的相机;4) 夹爪类型:使用不同的夹爪,包括平行夹爪和吸盘夹爪。此外,论文还使用了统一的评估指标(如抓取成功率)来评估算法的性能。在实验过程中,记录了大量的实验数据,并使用统计方法对数据进行分析。
🖼️ 关键图片
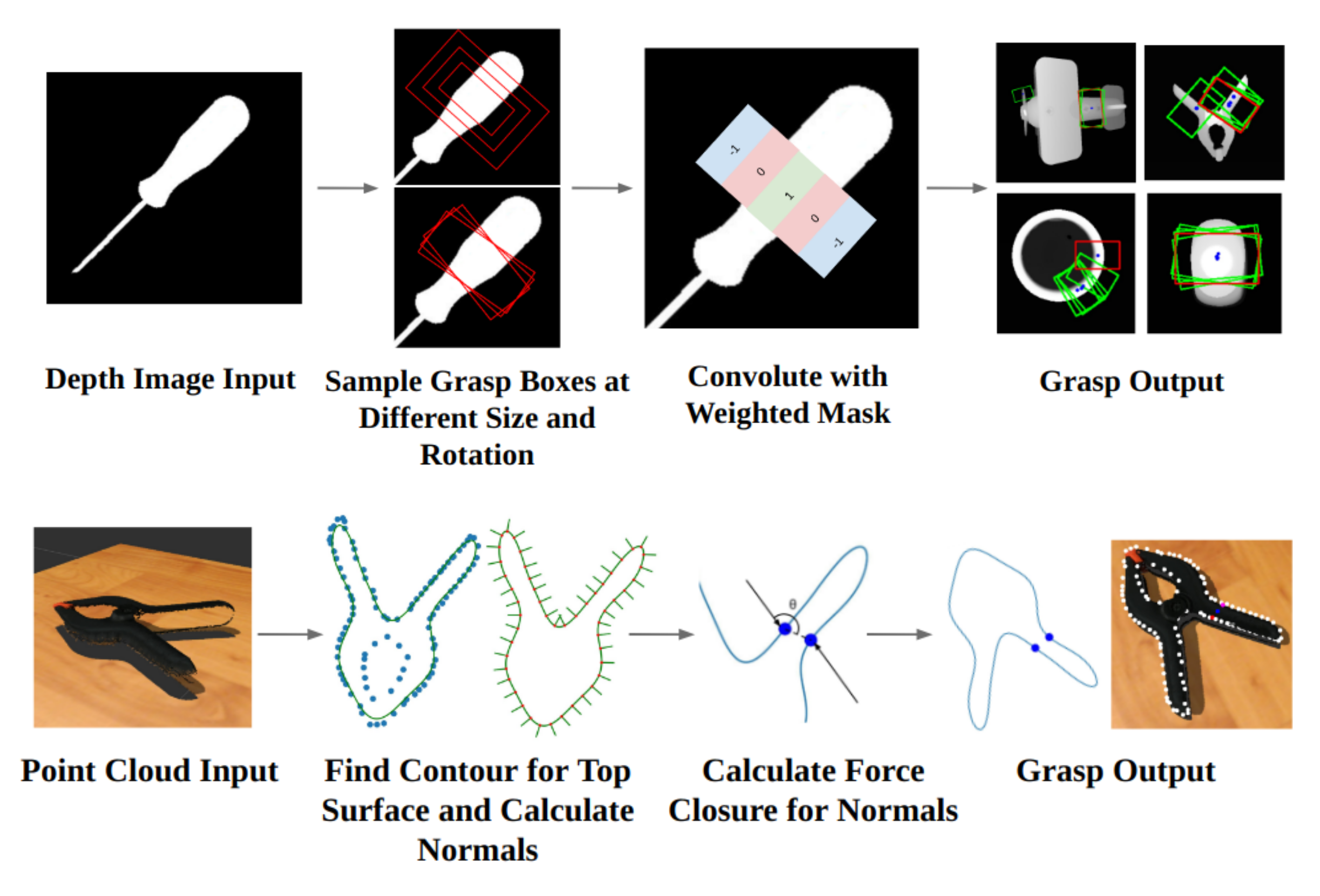
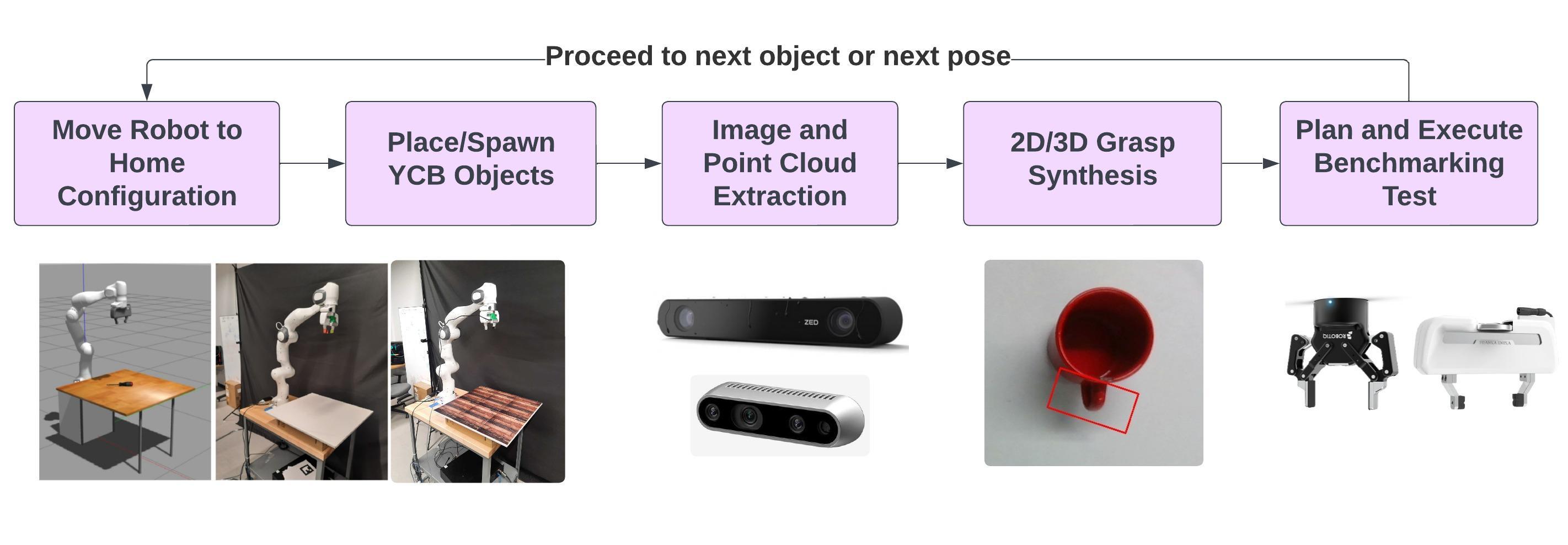

📊 实验亮点
该研究进行了5040次实验,对比了两种基于机器学习和两种解析的抓取算法。实验结果表明,不同算法在不同实验条件下表现出不同的优缺点。例如,某些算法在光照变化下表现出较好的鲁棒性,而另一些算法在复杂背景下表现更好。此外,研究还揭示了模拟和真实环境之间的差异,为算法在真实环境中的应用提供了重要的参考。
🎯 应用场景
该研究成果可应用于机器人自动化、智能制造、物流仓储等领域。通过基准测试,可以选择最适合特定应用场景的抓取算法,提高机器人操作的效率和可靠性。研究结果也有助于指导新型抓取算法的开发,提升机器人在复杂环境下的适应能力。
📄 摘要(原文)
We present a benchmarking study of vision-based robotic grasping algorithms with distinct approaches, and provide a comparative analysis. In particular, we compare two machine-learning-based and two analytical algorithms using an existing benchmarking protocol from the literature and determine the algorithm's strengths and weaknesses under different experimental conditions. These conditions include variations in lighting, background textures, cameras with different noise levels, and grippers. We also run analogous experiments in simulations and with real robots and present the discrepancies. Some experiments are also run in two different laboratories using same protocols to further analyze the repeatability of our results. We believe that this study, comprising 5040 experiments, provides important insights into the role and challenges of systematic experimentation in robotic manipulation, and guides the development of new algorithms by considering the factors that could impact the performance. The experiment recordings and our benchmarking software are publicly available.