EmbodiedVSR: Dynamic Scene Graph-Guided Chain-of-Thought Reasoning for Visual Spatial Tasks
作者: Yi Zhang, Qiang Zhang, Xiaozhu Ju, Zhaoyang Liu, Jilei Mao, Jingkai Sun, Jintao Wu, Shixiong Gao, Shihan Cai, Zhiyuan Qin, Linkai Liang, Jiaxu Wang, Yiqun Duan, Jiahang Cao, Renjing Xu, Jian Tang
分类: cs.RO, cs.AI, cs.CV
发布日期: 2025-03-14
备注: technical report
💡 一句话要点
提出EmbodiedVSR,利用动态场景图引导的CoT推理增强具身智能体的空间推理能力
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 空间推理 动态场景图 思维链 多模态大语言模型 长时程任务 零样本学习
📋 核心要点
- 现有MLLM在具身智能的空间推理方面存在不足,尤其是在长时程任务中,难以有效理解和利用空间关系。
- EmbodiedVSR通过构建动态场景图来表示环境信息,并结合CoT推理,使智能体能够逐步推理并与环境交互。
- 在eSpatial-Benchmark上的实验表明,EmbodiedVSR显著提升了空间推理的准确性和连贯性,尤其是在长时程任务中。
📝 摘要(中文)
多模态大型语言模型(MLLM)在具身智能领域取得了突破性进展,但在复杂长时程任务的空间推理方面仍面临重大挑战。为了解决这个问题,我们提出了EmbodiedVSR(Embodied Visual Spatial Reasoning),这是一个新颖的框架,它集成了动态场景图引导的思维链(CoT)推理,以增强具身智能体的空间理解能力。通过动态场景图显式地构建结构化知识表示,我们的方法能够实现零样本空间推理,而无需针对特定任务进行微调。这种方法不仅解耦了复杂的空间关系,而且使推理步骤与可操作的环境动态对齐。为了严格评估性能,我们引入了eSpatial-Benchmark,这是一个综合数据集,包括具有细粒度空间注释和自适应任务难度级别的真实具身场景。实验表明,我们的框架在准确性和推理连贯性方面显著优于现有的基于MLLM的方法,尤其是在需要迭代环境交互的长时程任务中。结果表明,当MLLM配备结构化、可解释的推理机制时,其在具身智能方面的潜力尚未完全开发,这为在真实空间应用中更可靠的部署铺平了道路。代码和数据集即将发布。
🔬 方法详解
问题定义:现有基于多模态大语言模型(MLLM)的具身智能体在处理需要复杂空间推理的长时程任务时表现不佳。它们难以有效地理解和利用环境中的空间关系,导致任务完成的准确性和效率降低。现有的方法通常缺乏对环境的结构化表示和可解释的推理过程,使得智能体难以进行有效的决策和规划。
核心思路:EmbodiedVSR的核心思路是利用动态场景图来显式地表示环境中的实体及其空间关系,并结合思维链(Chain-of-Thought, CoT)推理,引导智能体逐步推理并与环境交互。通过场景图,智能体可以获得环境的结构化知识,并通过CoT推理,逐步分解复杂任务,从而提高空间推理的准确性和连贯性。这种方法旨在弥合MLLM在空间理解和推理方面的差距,使其能够更好地适应复杂的具身任务。
技术框架:EmbodiedVSR框架主要包含以下几个模块:1) 环境感知模块:负责从环境中获取视觉信息,并将其转换为场景图表示。该模块可能使用目标检测、语义分割等技术来识别环境中的实体及其属性。2) 动态场景图构建模块:根据环境感知模块的输出,构建动态场景图,其中节点表示实体,边表示实体之间的空间关系。场景图会随着智能体与环境的交互而动态更新。3) CoT推理模块:利用场景图和任务描述,生成一系列推理步骤,指导智能体逐步完成任务。该模块使用MLLM作为推理引擎,并利用场景图提供的信息来约束推理过程。4) 动作执行模块:根据CoT推理模块的输出,执行相应的动作,与环境进行交互。
关键创新:EmbodiedVSR的关键创新在于将动态场景图和CoT推理相结合,用于增强具身智能体的空间推理能力。与现有方法相比,EmbodiedVSR能够显式地表示环境中的空间关系,并通过CoT推理实现可解释的决策过程。这种方法使得智能体能够更好地理解环境,并进行更有效的规划和执行。此外,EmbodiedVSR采用零样本学习的方式,无需针对特定任务进行微调,具有更好的泛化能力。
关键设计:动态场景图的构建是EmbodiedVSR的关键设计之一。场景图的节点表示环境中的实体,例如物体、房间等,节点属性包括实体的类别、位置、大小等信息。场景图的边表示实体之间的空间关系,例如“在…之上”、“在…旁边”等。CoT推理模块使用MLLM作为推理引擎,并利用场景图提供的信息来约束推理过程。推理过程可以表示为一个序列,每个步骤包括观察、推理和行动。损失函数的设计旨在鼓励智能体生成更准确的场景图和更合理的推理步骤。具体的参数设置和网络结构细节在论文中进行了详细描述(未知)。
🖼️ 关键图片
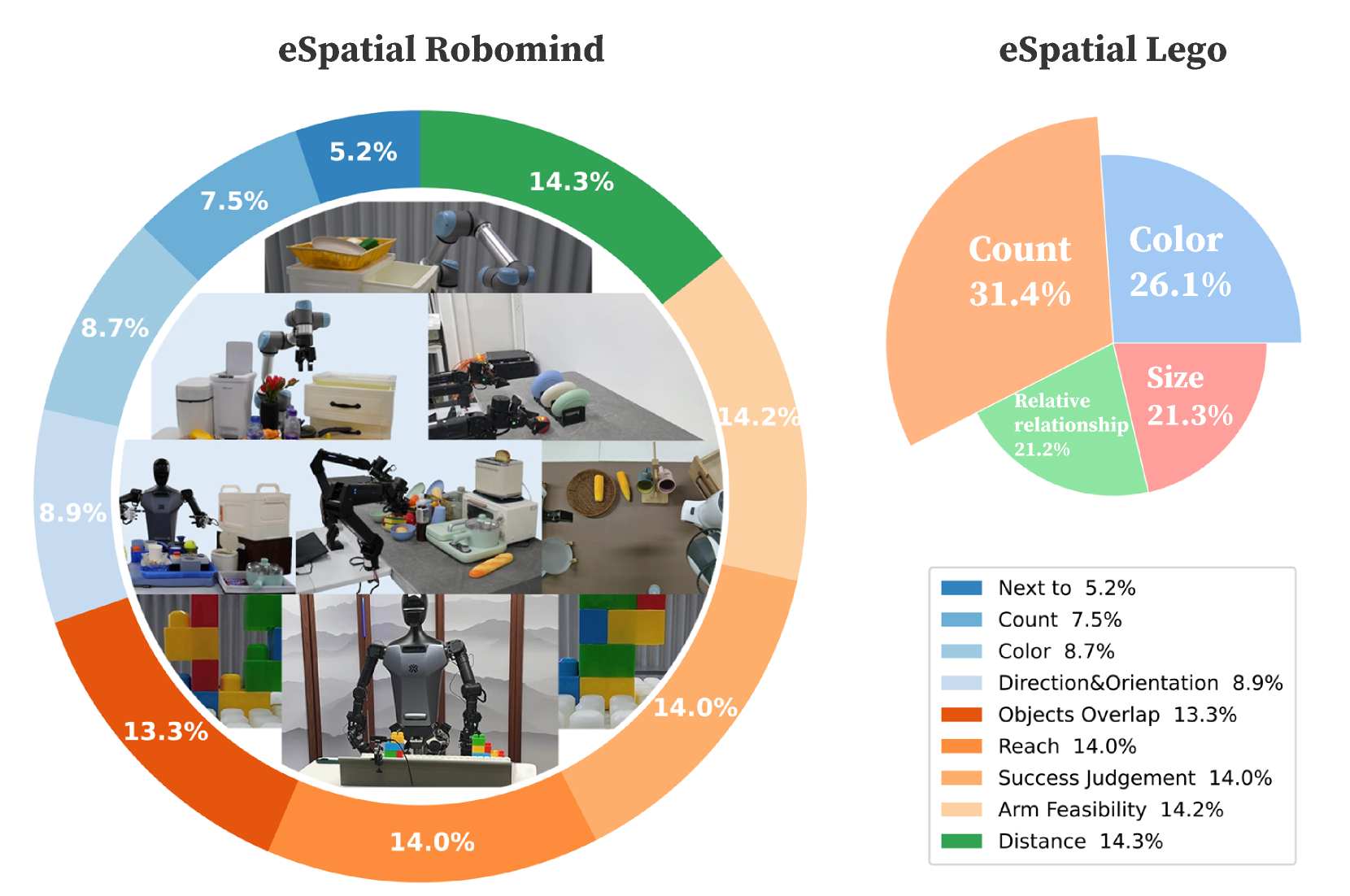
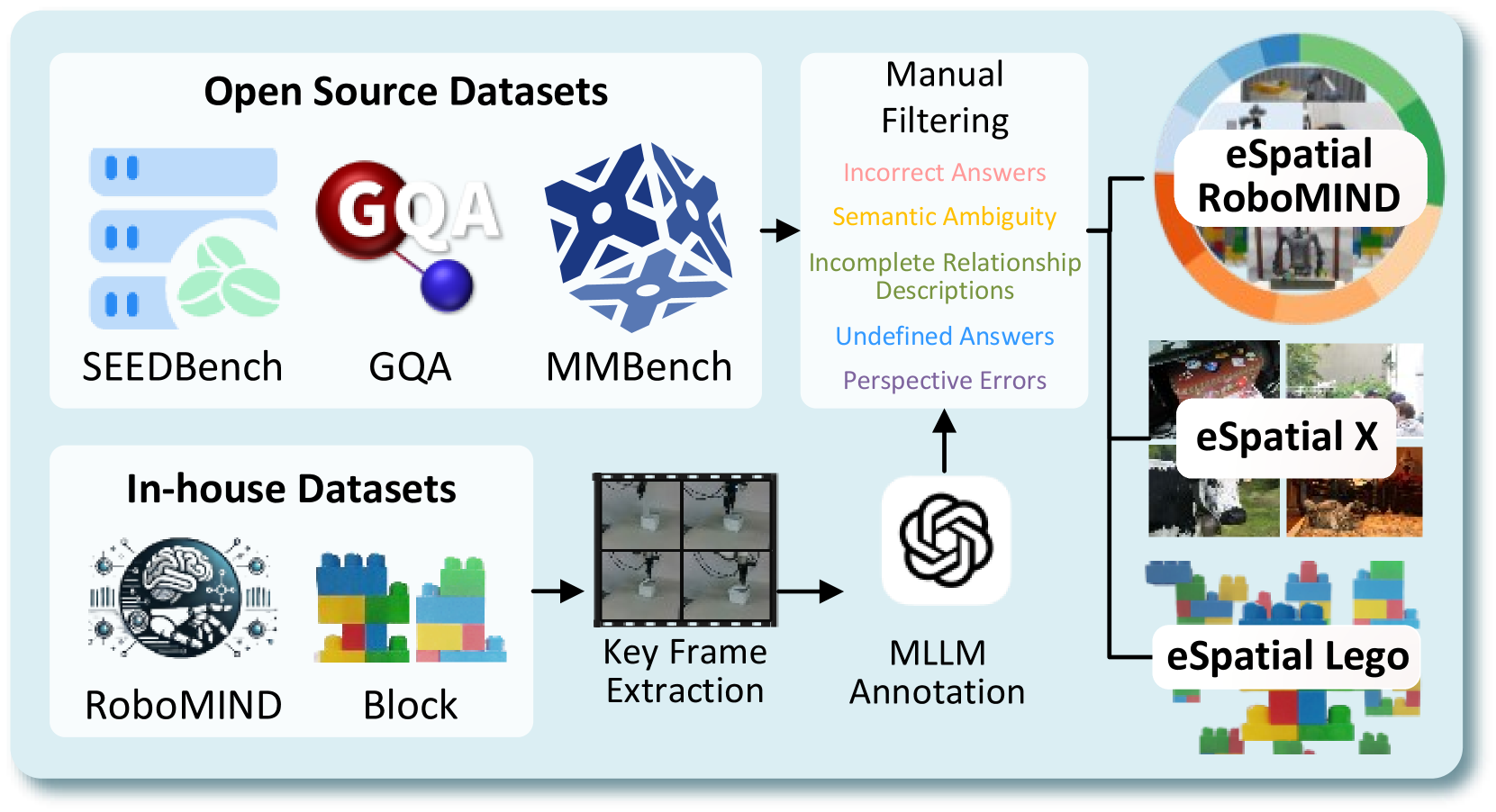
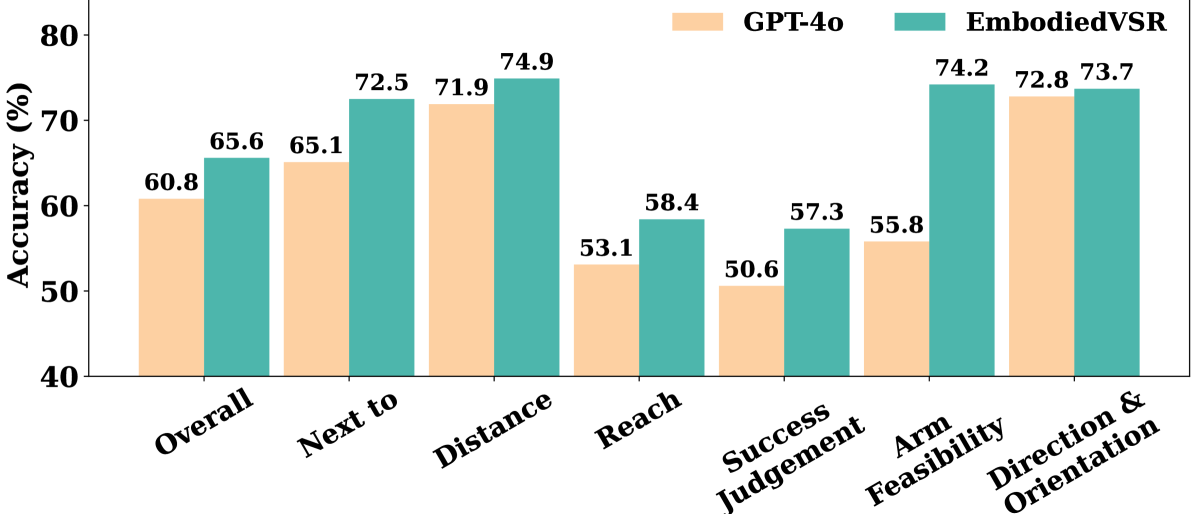
📊 实验亮点
实验结果表明,EmbodiedVSR在eSpatial-Benchmark上显著优于现有的基于MLLM的方法。在长时程任务中,EmbodiedVSR的准确率和推理连贯性得到了显著提升。具体的数据指标和对比基线在论文中进行了详细描述(未知),但总体而言,EmbodiedVSR证明了动态场景图引导的CoT推理在增强具身智能体空间推理能力方面的有效性。
🎯 应用场景
EmbodiedVSR具有广泛的应用前景,例如在家庭服务机器人、自动驾驶、虚拟现实等领域。它可以帮助机器人更好地理解和操作环境,完成各种复杂的任务,例如导航、物体操作、环境探索等。通过提高具身智能体的空间推理能力,EmbodiedVSR有望推动这些领域的发展,并为人们的生活带来便利。
📄 摘要(原文)
While multimodal large language models (MLLMs) have made groundbreaking progress in embodied intelligence, they still face significant challenges in spatial reasoning for complex long-horizon tasks. To address this gap, we propose EmbodiedVSR (Embodied Visual Spatial Reasoning), a novel framework that integrates dynamic scene graph-guided Chain-of-Thought (CoT) reasoning to enhance spatial understanding for embodied agents. By explicitly constructing structured knowledge representations through dynamic scene graphs, our method enables zero-shot spatial reasoning without task-specific fine-tuning. This approach not only disentangles intricate spatial relationships but also aligns reasoning steps with actionable environmental dynamics. To rigorously evaluate performance, we introduce the eSpatial-Benchmark, a comprehensive dataset including real-world embodied scenarios with fine-grained spatial annotations and adaptive task difficulty levels. Experiments demonstrate that our framework significantly outperforms existing MLLM-based methods in accuracy and reasoning coherence, particularly in long-horizon tasks requiring iterative environment interaction. The results reveal the untapped potential of MLLMs for embodied intelligence when equipped with structured, explainable reasoning mechanisms, paving the way for more reliable deployment in real-world spatial applications. The codes and datasets will be released soon.