Is Your Imitation Learning Policy Better than Mine? Policy Comparison with Near-Optimal Stopping
作者: David Snyder, Asher James Hancock, Apurva Badithela, Emma Dixon, Patrick Miller, Rares Andrei Ambrus, Anirudha Majumdar, Masha Itkina, Haruki Nishimura
分类: cs.RO, stat.ML
发布日期: 2025-03-14 (更新: 2025-06-06)
备注: 14 + 5 pages, 10 figures, 4 tables. Accepted to RSS 2025
💡 一句话要点
提出一种基于近优停止的策略比较方法,提升模仿学习策略评估效率。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 模仿学习 策略比较 序贯假设检验 近优停止 机器人操作
📋 核心要点
- 模仿学习策略评估受限于小样本量,传统批量测试方法缺乏灵活性,且易受p值操纵影响。
- 提出一种序贯统计测试框架,根据中间结果自适应调整试验次数,实现近优停止。
- 实验表明,该方法在保持统计功效的同时,显著减少评估试验次数,尤其在复杂场景下优势明显。
📝 摘要(中文)
模仿学习使得机器人能够在复杂的灵巧操作环境中执行长时程任务。随着新方法的不断涌现,必须通过重复的评估试验,严格地评估这些方法并与相应的基线进行比较。然而,由于大量的人工干预和策略有限的推理吞吐量,策略比较从根本上受到小可行样本量的限制(例如,10或50)。本文提出了一种新的统计框架,用于在小样本量的情况下严格比较两种策略。先前在统计策略比较方面的工作依赖于批量测试,这需要固定、预先确定的试验次数,并且缺乏根据观察到的评估数据调整样本大小的灵活性。此外,通过额外的试验来扩展测试可能会导致无意的p值操纵,从而破坏统计保证。相比之下,我们提出的统计测试是顺序的,允许研究人员根据中间结果决定是否运行更多试验。这种方法自适应地调整试验次数以适应底层比较的难度,从而节省大量时间和精力,而不会牺牲概率正确性。大量的数值模拟和真实世界的机器人操作实验表明,我们的测试实现了近优停止,使研究人员能够在接近最小的试验次数中停止评估并做出决策。具体而言,与最先进的基线相比,它减少了高达32%的评估试验次数,同时保持了比较的概率正确性和统计功效。此外,我们的方法在最具挑战性的比较实例(需要最多的评估试验)中表现最强;在多任务比较场景中,我们为评估者节省了超过160次模拟rollout。
🔬 方法详解
问题定义:论文旨在解决模仿学习中策略比较效率低下的问题。现有方法通常采用批量测试,需要预先确定试验次数,无法根据实际情况调整,导致在简单情况下浪费资源,在复杂情况下可能样本不足。此外,为了获得显著性结果而增加试验次数会引入p-hacking的风险,影响评估的可靠性。
核心思路:论文的核心思路是采用序贯假设检验,允许根据已有的评估结果动态地决定是否需要进行更多的试验。这种方法能够自适应地调整样本量,在保证统计功效的前提下,尽可能减少试验次数,从而提高策略比较的效率。
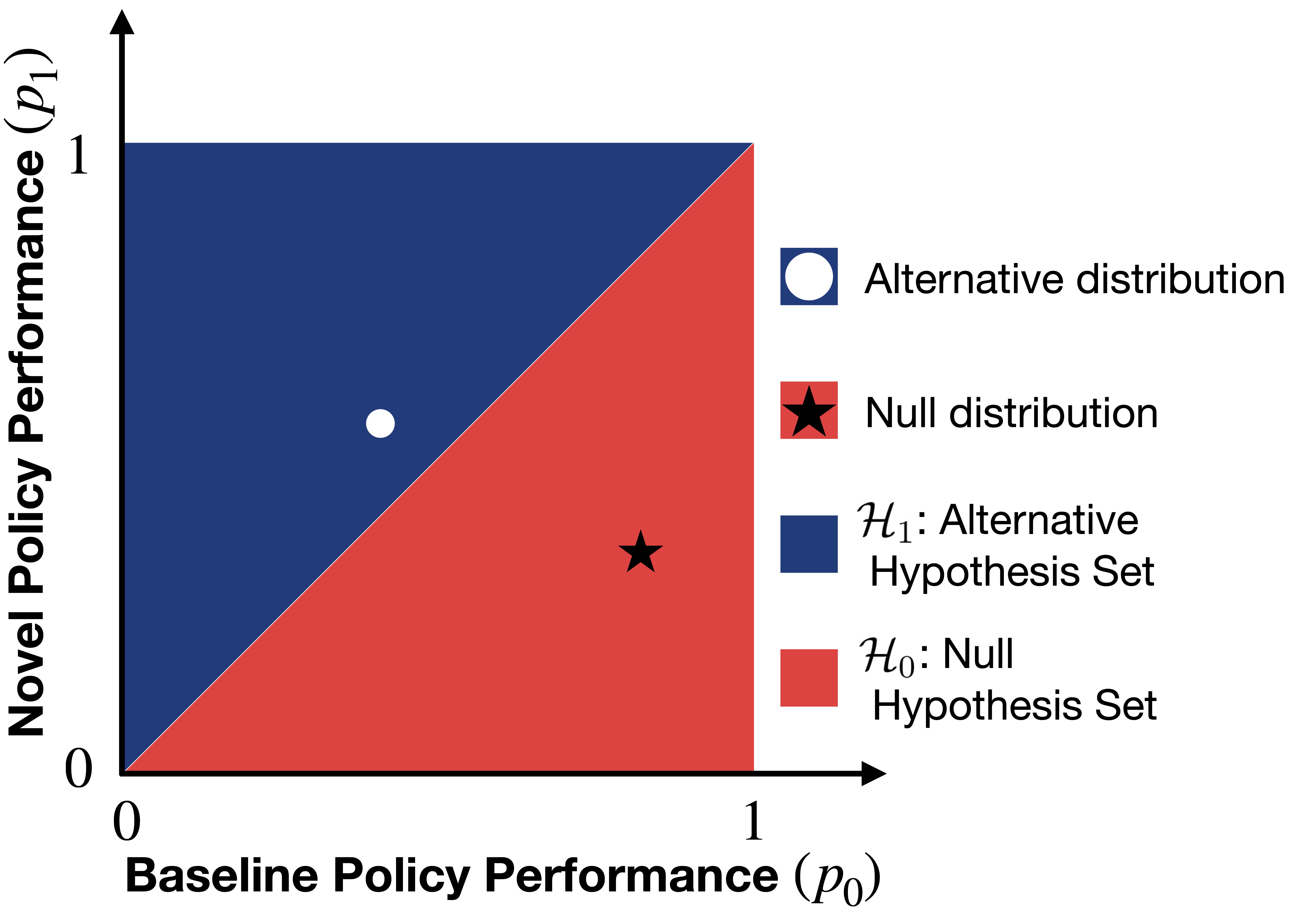
技术框架:该方法的核心是一个序贯概率比检验(Sequential Probability Ratio Test, SPRT)。首先,定义两个策略的性能差异的零假设和备择假设。然后,根据每次试验的结果,计算似然比,并将其与预先设定的阈值进行比较。如果似然比超过上限阈值,则接受备择假设,认为两个策略存在显著差异;如果似然比低于下限阈值,则接受零假设,认为两个策略没有显著差异;否则,继续进行试验。
关键创新:该方法最重要的创新在于将序贯假设检验应用于模仿学习策略比较,实现了近优停止。与传统的批量测试相比,该方法能够根据实际情况自适应地调整样本量,从而在保证统计功效的前提下,显著减少评估试验次数。此外,序贯检验天然地避免了p-hacking的风险,提高了评估的可靠性。
关键设计:关键设计包括:1) 似然比的计算方式,需要根据具体的性能指标进行选择;2) 上下限阈值的设定,需要根据期望的显著性水平和统计功效进行调整;3) 停止规则的设计,需要考虑试验成本和评估精度之间的权衡。论文中具体使用了基于reward的性能指标,并采用理论分析和实验验证相结合的方式来确定合适的参数。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在数值模拟和真实机器人操作实验中均表现出色。与最先进的基线方法相比,该方法能够减少高达32%的评估试验次数,同时保持了比较的概率正确性和统计功效。在多任务比较场景中,该方法为评估者节省了超过160次模拟rollout,显著提升了评估效率。
🎯 应用场景
该研究成果可广泛应用于机器人模仿学习、强化学习等领域,加速策略迭代和算法验证过程。通过更高效的策略比较,可以更快地筛选出优秀的策略,提升机器人学习效率,降低开发成本。此外,该方法也适用于其他需要进行策略或算法比较的场景,例如游戏AI、自动驾驶等。
📄 摘要(原文)
Imitation learning has enabled robots to perform complex, long-horizon tasks in challenging dexterous manipulation settings. As new methods are developed, they must be rigorously evaluated and compared against corresponding baselines through repeated evaluation trials. However, policy comparison is fundamentally constrained by a small feasible sample size (e.g., 10 or 50) due to significant human effort and limited inference throughput of policies. This paper proposes a novel statistical framework for rigorously comparing two policies in the small sample size regime. Prior work in statistical policy comparison relies on batch testing, which requires a fixed, pre-determined number of trials and lacks flexibility in adapting the sample size to the observed evaluation data. Furthermore, extending the test with additional trials risks inducing inadvertent p-hacking, undermining statistical assurances. In contrast, our proposed statistical test is sequential, allowing researchers to decide whether or not to run more trials based on intermediate results. This adaptively tailors the number of trials to the difficulty of the underlying comparison, saving significant time and effort without sacrificing probabilistic correctness. Extensive numerical simulation and real-world robot manipulation experiments show that our test achieves near-optimal stopping, letting researchers stop evaluation and make a decision in a near-minimal number of trials. Specifically, it reduces the number of evaluation trials by up to 32% as compared to state-of-the-art baselines, while preserving the probabilistic correctness and statistical power of the comparison. Moreover, our method is strongest in the most challenging comparison instances (requiring the most evaluation trials); in a multi-task comparison scenario, we save the evaluator more than 160 simulation rollouts.