LUMOS: Language-Conditioned Imitation Learning with World Models
作者: Iman Nematollahi, Branton DeMoss, Akshay L Chandra, Nick Hawes, Wolfram Burgard, Ingmar Posner
分类: cs.RO, cs.CV, cs.LG
发布日期: 2025-03-13
备注: Accepted at the 2025 IEEE International Conference on Robotics and Automation (ICRA)
💡 一句话要点
LUMOS:基于世界模型的语言条件模仿学习框架,实现机器人零样本迁移
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模仿学习 世界模型 语言条件 机器人控制 离线学习 长时程任务 零样本迁移 潜在空间
📋 核心要点
- 现有离线模仿学习方法易受策略诱导的分布偏移影响,限制了其在机器人长时程任务中的应用。
- LUMOS在世界模型的潜在空间中进行在线模仿学习,结合潜在规划和回溯目标重标记,缓解分布偏移。
- 在CALVIN基准测试中,LUMOS超越了现有方法,首次在离线世界模型中实现了真实机器人的语言条件连续控制。
📝 摘要(中文)
LUMOS是一个用于机器人的语言条件多任务模仿学习框架。它通过在学习到的世界模型的潜在空间中进行多次长时程的实践来学习技能,并将这些技能零样本迁移到真实的机器人上。通过在学习到的世界模型的潜在空间中进行在线学习,该算法缓解了策略诱导的分布偏移,而这正是大多数离线模仿学习方法所面临的问题。LUMOS从非结构化的play数据中学习,仅使用不到1%的回溯语言标注,但在测试时可以通过语言命令进行引导。通过结合潜在规划、基于图像和语言的回溯目标重标记以及优化世界模型潜在空间中的内在奖励,LUMOS实现了连贯的长时程性能,有效减少了协变量偏移。在具有挑战性的长时程CALVIN基准测试中,LUMOS优于先前的基于学习的方法,并在链式多任务评估中取得了可比的结果。据我们所知,我们是第一个在离线世界模型中学习用于真实世界机器人的语言条件连续视觉运动控制的。
🔬 方法详解
问题定义:论文旨在解决机器人领域中,如何利用离线数据进行语言条件下的长时程多任务模仿学习问题。现有离线模仿学习方法容易受到策略诱导的分布偏移的影响,导致学习到的策略在真实环境中表现不佳,难以泛化到新的任务。此外,如何有效地利用稀疏的语言标注信息也是一个挑战。
核心思路:LUMOS的核心思路是在学习到的世界模型的潜在空间中进行模仿学习。通过在潜在空间中进行规划和学习,可以有效地缓解策略诱导的分布偏移。同时,利用图像和语言的回溯目标重标记技术,可以更有效地利用稀疏的语言标注信息,提高学习效率。此外,通过优化世界模型潜在空间中的内在奖励,可以进一步减少协变量偏移,提高策略的鲁棒性。
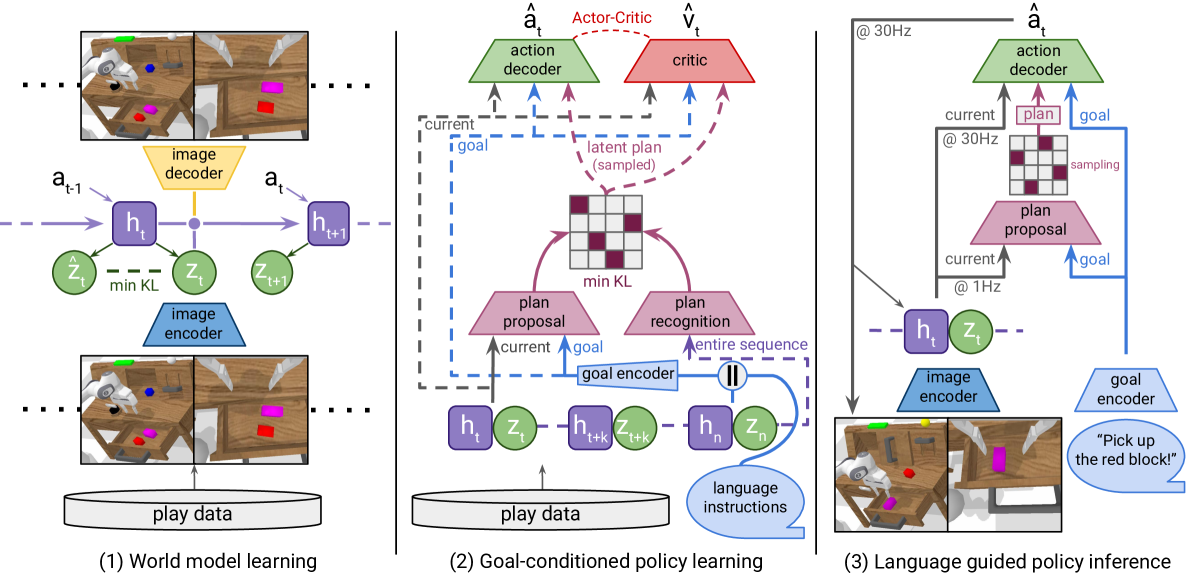
技术框架:LUMOS的整体框架包括以下几个主要模块:1) 世界模型:用于学习环境的动态模型,将高维的图像输入编码到低维的潜在空间中。2) 策略网络:在世界模型的潜在空间中学习控制策略,根据语言指令和当前状态输出动作。3) 潜在规划器:用于在潜在空间中进行长时程规划,生成一系列的中间目标。4) 回溯目标重标记模块:利用图像和语言信息,对训练数据进行目标重标记,提高学习效率。5) 内在奖励模块:定义在世界模型潜在空间中的奖励函数,用于鼓励策略探索未知的状态空间。
关键创新:LUMOS的关键创新在于:1) 在离线世界模型中进行语言条件下的连续视觉运动控制,实现了真实机器人的零样本迁移。2) 结合潜在规划和回溯目标重标记技术,有效地缓解了策略诱导的分布偏移,提高了学习效率。3) 提出了在世界模型潜在空间中定义内在奖励的方法,进一步提高了策略的鲁棒性。
关键设计:LUMOS的关键设计包括:1) 世界模型采用变分自编码器(VAE)结构,用于学习环境的潜在表示。2) 策略网络采用Transformer结构,用于处理语言指令和状态信息。3) 回溯目标重标记模块利用图像和语言的相似度信息,对训练数据进行目标重标记。4) 内在奖励函数基于世界模型预测的状态和实际状态之间的差异进行定义。
🖼️ 关键图片


📊 实验亮点
LUMOS在CALVIN基准测试中取得了显著的成果,超越了现有的基于学习的方法。在链式多任务评估中,LUMOS取得了与现有方法相当的结果,并且首次实现了在离线世界模型中学习用于真实世界机器人的语言条件连续视觉运动控制。实验结果表明,LUMOS能够有效地缓解策略诱导的分布偏移,提高学习效率和策略的鲁棒性。
🎯 应用场景
LUMOS具有广泛的应用前景,例如可以应用于家庭服务机器人、工业机器人等领域。通过学习大量的离线数据,机器人可以掌握各种技能,并根据用户的语言指令完成复杂的任务。此外,LUMOS还可以应用于自动驾驶领域,帮助车辆理解驾驶员的意图,提高驾驶安全性。未来,LUMOS有望成为实现通用机器人和智能体的关键技术。
📄 摘要(原文)
We introduce LUMOS, a language-conditioned multi-task imitation learning framework for robotics. LUMOS learns skills by practicing them over many long-horizon rollouts in the latent space of a learned world model and transfers these skills zero-shot to a real robot. By learning on-policy in the latent space of the learned world model, our algorithm mitigates policy-induced distribution shift which most offline imitation learning methods suffer from. LUMOS learns from unstructured play data with fewer than 1% hindsight language annotations but is steerable with language commands at test time. We achieve this coherent long-horizon performance by combining latent planning with both image- and language-based hindsight goal relabeling during training, and by optimizing an intrinsic reward defined in the latent space of the world model over multiple time steps, effectively reducing covariate shift. In experiments on the difficult long-horizon CALVIN benchmark, LUMOS outperforms prior learning-based methods with comparable approaches on chained multi-task evaluations. To the best of our knowledge, we are the first to learn a language-conditioned continuous visuomotor control for a real-world robot within an offline world model. Videos, dataset and code are available at http://lumos.cs.uni-freiburg.de.