MoE-Loco: Mixture of Experts for Multitask Locomotion
作者: Runhan Huang, Shaoting Zhu, Yilun Du, Hang Zhao
分类: cs.RO, cs.AI
发布日期: 2025-03-11 (更新: 2025-05-21)
备注: 9 pages, 10 figures
💡 一句话要点
MoE-Loco:面向多任务运动的混合专家模型,提升腿式机器人泛化性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 腿式机器人 多任务学习 混合专家模型 强化学习 运动控制 地形适应 步态控制
📋 核心要点
- 多任务强化学习在腿式机器人运动控制中面临梯度冲突问题,导致训练困难和性能下降。
- MoE-Loco利用混合专家模型,使不同专家专注于特定运动行为,从而缓解梯度冲突,提升训练效率。
- 实验结果表明,MoE-Loco在多种地形和步态下表现出良好的鲁棒性和适应性,并在真实机器人上验证了其有效性。
📝 摘要(中文)
本文提出了MoE-Loco,一个用于腿式机器人多任务运动的混合专家(MoE)框架。我们的方法使单个策略能够处理各种地形,包括栏杆、坑洼、楼梯、斜坡和障碍物,同时支持四足和双足步态。通过使用MoE,我们缓解了多任务强化学习中通常出现的梯度冲突,从而提高了训练效率和性能。实验表明,不同的专家自然地专注于不同的运动行为,这可以用于任务迁移和技能组合。我们进一步在仿真和真实环境中验证了我们的方法,展示了其鲁棒性和适应性。
🔬 方法详解
问题定义:现有的多任务强化学习方法在控制腿式机器人进行复杂地形运动时,由于不同任务之间的梯度冲突,导致训练不稳定,难以收敛,并且泛化能力较差。尤其是在需要同时支持多种步态和地形时,问题更加突出。
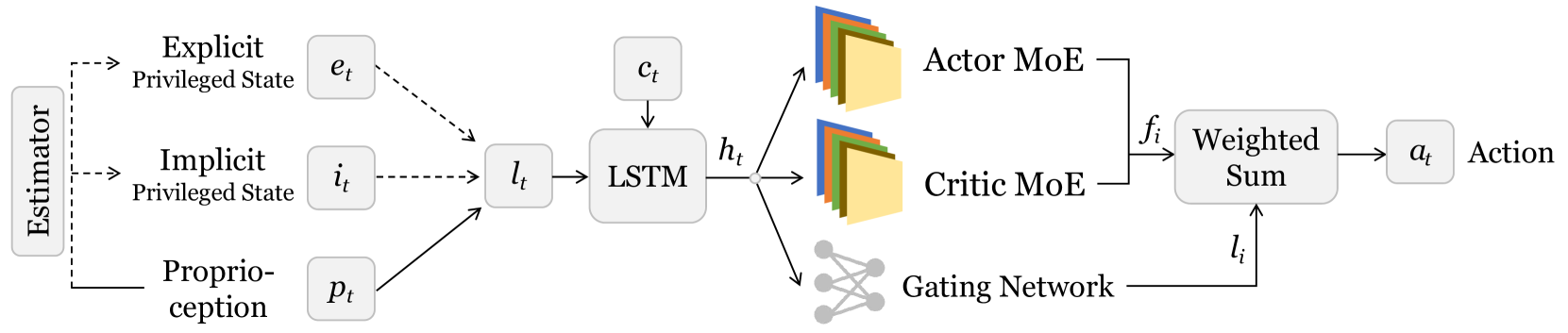
核心思路:MoE-Loco的核心思路是利用混合专家模型(Mixture of Experts, MoE)将复杂的运动控制任务分解为多个子任务,每个专家专注于学习特定的运动技能或适应特定的地形。通过门控网络动态地选择合适的专家组合,从而实现对不同任务的灵活控制和高效学习。这种方法可以有效地缓解梯度冲突,提高训练效率和泛化能力。
技术框架:MoE-Loco框架主要包含以下几个模块:1) 多个专家网络,每个专家网络负责学习一种特定的运动技能或适应特定的地形;2) 一个门控网络,根据当前的状态信息,动态地选择合适的专家组合;3) 一个奖励函数,用于指导专家网络的学习。整体流程是:首先,机器人根据当前状态,通过门控网络选择合适的专家组合;然后,选定的专家网络输出动作指令;最后,机器人执行动作并获得奖励,用于更新专家网络和门控网络的参数。
关键创新:MoE-Loco的关键创新在于将混合专家模型应用于腿式机器人的多任务运动控制。与传统的单策略方法相比,MoE-Loco能够更好地处理不同任务之间的梯度冲突,提高训练效率和泛化能力。此外,MoE-Loco还能够实现任务迁移和技能组合,从而进一步提高机器人的适应性。
关键设计:MoE-Loco的关键设计包括:1) 专家网络的结构,可以使用不同的神经网络结构,例如多层感知机或循环神经网络;2) 门控网络的结构,可以使用softmax函数或Gumbel-Softmax函数来选择专家组合;3) 奖励函数的设计,需要根据具体的任务进行调整,以鼓励机器人学习期望的运动行为。具体参数设置未知,论文中可能包含更多细节。
🖼️ 关键图片


📊 实验亮点
MoE-Loco在仿真和真实环境中都取得了显著的成果。在仿真实验中,MoE-Loco能够成功控制四足和双足机器人穿越各种复杂地形,例如栏杆、坑洼、楼梯和斜坡。在真实环境实验中,MoE-Loco也表现出良好的鲁棒性和适应性,能够成功控制机器人完成各种运动任务。具体性能数据未知,需要参考论文原文。
🎯 应用场景
MoE-Loco技术可应用于各种腿式机器人,使其能够在复杂和未知的环境中执行任务,例如搜救、勘探、物流和巡检。该技术可以提高机器人的自主性和适应性,使其能够更好地服务于人类社会。未来,该技术有望应用于更广泛的机器人领域,例如人形机器人和医疗机器人。
📄 摘要(原文)
We present MoE-Loco, a Mixture of Experts (MoE) framework for multitask locomotion for legged robots. Our method enables a single policy to handle diverse terrains, including bars, pits, stairs, slopes, and baffles, while supporting quadrupedal and bipedal gaits. Using MoE, we mitigate the gradient conflicts that typically arise in multitask reinforcement learning, improving both training efficiency and performance. Our experiments demonstrate that different experts naturally specialize in distinct locomotion behaviors, which can be leveraged for task migration and skill composition. We further validate our approach in both simulation and real-world deployment, showcasing its robustness and adaptability.