Gait in Eight: Efficient On-Robot Learning for Omnidirectional Quadruped Locomotion
作者: Nico Bohlinger, Jonathan Kinzel, Daniel Palenicek, Lukasz Antczak, Jan Peters
分类: cs.RO, cs.LG
发布日期: 2025-03-11 (更新: 2025-08-12)
💡 一句话要点
提出CrossQ算法,实现四足机器人8分钟内高效学习全向运动
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 四足机器人 强化学习 机器人学习 全向运动 CrossQ算法
📋 核心要点
- 现有机器人强化学习方法计算量大,难以满足机器人实时学习的算力约束,限制了其在四足机器人运动控制中的应用。
- 论文提出基于CrossQ算法的强化学习框架,利用其样本高效性和低计算开销,实现在机器人上快速学习全向运动控制策略。
- 实验表明,该框架仅需8分钟的实时训练,即可使四足机器人在不同环境中实现鲁棒的全向运动控制。
📝 摘要(中文)
本文提出了一种在机器人上进行强化学习的框架,用于高效地学习四足机器人的运动控制策略。该框架利用新型离策略算法CrossQ的样本效率和极低的计算开销,仅需8分钟的原始实时训练即可完成。研究探索了两种控制架构:一种是预测关节目标位置,用于实现敏捷、高速的运动;另一种是使用中央模式发生器(CPG),用于实现稳定、自然的步态。与以往专注于学习简单前进步态的工作不同,本文将机器人上的学习扩展到全向运动。实验结果表明,该方法在不同的室内和室外环境中具有鲁棒性。
🔬 方法详解
问题定义:现有四足机器人运动控制的机器人强化学习方法,通常需要大量的训练样本和计算资源,难以在机器人平台上实时运行。尤其是在学习复杂的全向运动时,训练时间和计算成本会进一步增加,限制了其在实际场景中的应用。
核心思路:论文的核心思路是利用一种新型的离策略强化学习算法CrossQ,该算法具有很高的样本效率和极低的计算开销,能够在有限的计算资源下快速学习复杂的运动控制策略。通过优化算法和控制架构,实现在机器人上进行高效的全向运动学习。
技术框架:该框架主要包含以下几个模块:1)状态观测模块:从机器人传感器获取状态信息,例如关节角度、角速度等。2)动作生成模块:根据当前状态,利用强化学习策略生成控制指令,例如关节目标位置或CPG参数。3)环境交互模块:将控制指令发送给机器人,并接收机器人的反馈信息。4)策略更新模块:利用CrossQ算法,根据环境反馈信息更新强化学习策略。整体流程是在机器人上实时运行,通过不断与环境交互,优化运动控制策略。
关键创新:最重要的技术创新点是CrossQ算法在四足机器人运动控制中的应用。CrossQ是一种新型的离策略强化学习算法,它通过学习Q函数的交叉熵来提高样本效率和稳定性。与传统的强化学习算法相比,CrossQ算法能够在更少的训练样本下学习到更好的策略,并且具有更强的鲁棒性。
关键设计:论文中使用了两种控制架构:一种是直接预测关节目标位置,另一种是使用中央模式发生器(CPG)。对于关节目标位置控制,使用神经网络作为策略函数,输入是机器人的状态信息,输出是关节目标位置。对于CPG控制,使用神经网络作为CPG参数的调节器,输入是机器人的状态信息,输出是CPG的参数,例如频率、相位等。损失函数采用奖励函数的形式,根据机器人的运动速度、稳定性等指标进行设计。
🖼️ 关键图片

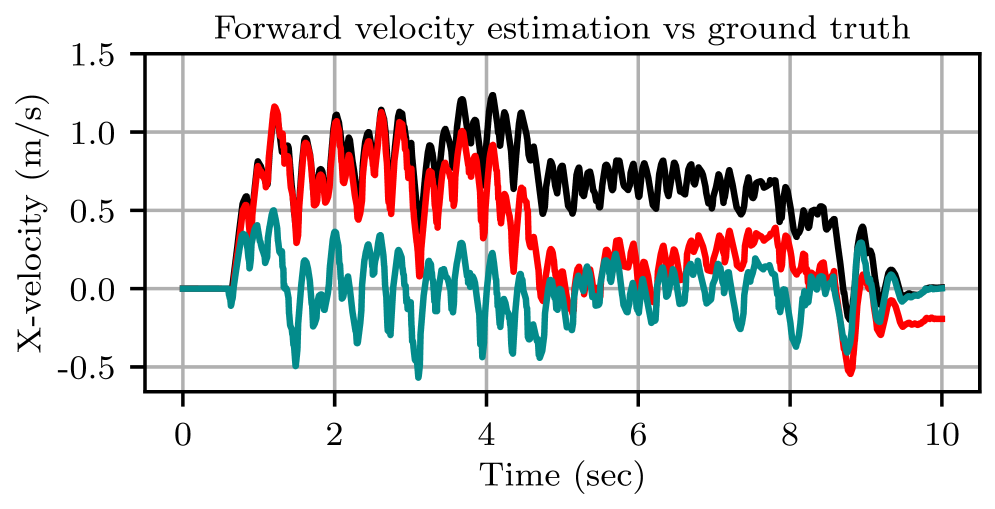
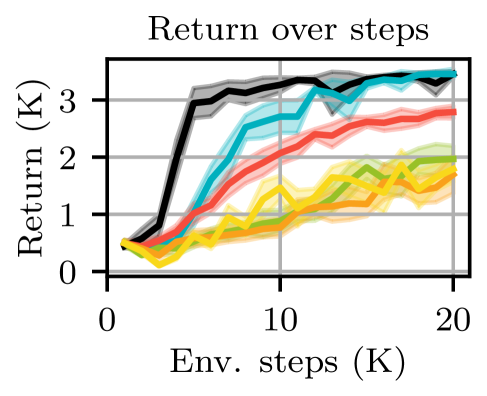
📊 实验亮点
实验结果表明,该框架仅需8分钟的实时训练,即可使四足机器人在不同的室内和室外环境中实现鲁棒的全向运动控制。与传统的强化学习算法相比,该方法能够显著提高样本效率和训练速度。此外,该方法还能够适应不同的控制架构,例如关节目标位置控制和CPG控制。
🎯 应用场景
该研究成果可应用于各种需要四足机器人进行全向运动的场景,例如搜救、巡检、物流等。通过在机器人上进行实时学习,可以使机器人能够适应不同的地形和环境,提高其运动能力和自主性。未来,该技术有望应用于更复杂的机器人任务,例如操作、导航等。
📄 摘要(原文)
On-robot Reinforcement Learning is a promising approach to train embodiment-aware policies for legged robots. However, the computational constraints of real-time learning on robots pose a significant challenge. We present a framework for efficiently learning quadruped locomotion in just 8 minutes of raw real-time training utilizing the sample efficiency and minimal computational overhead of the new off-policy algorithm CrossQ. We investigate two control architectures: Predicting joint target positions for agile, high-speed locomotion and Central Pattern Generators for stable, natural gaits. While prior work focused on learning simple forward gaits, our framework extends on-robot learning to omnidirectional locomotion. We demonstrate the robustness of our approach in different indoor and outdoor environments.