PointVLA: Injecting the 3D World into Vision-Language-Action Models
作者: Chengmeng Li, Junjie Wen, Yan Peng, Yaxin Peng, Feifei Feng, Yichen Zhu
分类: cs.RO, cs.CV, cs.LG
发布日期: 2025-03-10
💡 一句话要点
PointVLA:将3D世界注入视觉-语言-动作模型,无需重训练。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 机器人操作 点云处理 模仿学习 3D感知 少样本学习 多任务学习
📋 核心要点
- 现有VLA模型依赖RGB图像,缺乏对真实世界交互至关重要的空间推理能力,且重新训练成本高昂。
- PointVLA通过轻量级模块化块向预训练VLA模型注入3D点云特征,无需重新训练,保留了2D预训练的优势。
- 实验表明,PointVLA在少样本多任务、真实与照片区分、高度适应性以及长时程任务中均优于现有2D方法。
📝 摘要(中文)
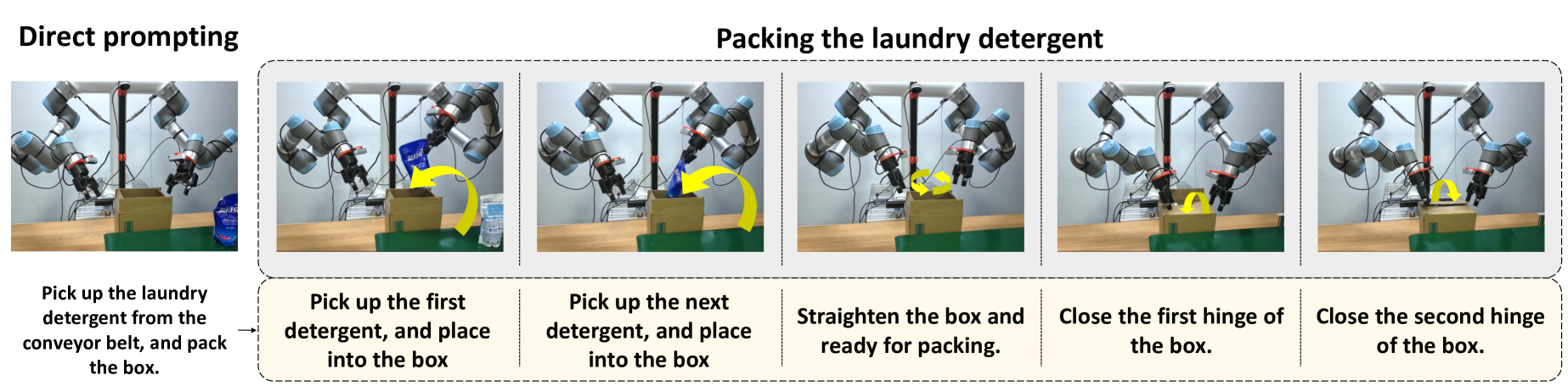
视觉-语言-动作(VLA)模型通过利用大规模2D视觉-语言预训练在机器人任务中表现出色,但它们对RGB图像的依赖限制了对现实世界交互至关重要的空间推理。使用3D数据重新训练这些模型在计算上是禁止的,而丢弃现有的2D数据集会浪费宝贵的资源。为了弥合这一差距,我们提出了PointVLA,一个增强预训练VLA模型并使其能够处理点云输入的框架,且无需重新训练。我们的方法冻结了原始的动作专家,并通过一个轻量级的模块化块注入3D特征。为了确定整合点云表示的最有效方式,我们进行了一项跳跃块分析,以查明原始动作专家中不太有用的块,确保3D特征仅注入到这些块中,从而最大限度地减少对预训练表示的破坏。大量的实验表明,PointVLA在模拟和真实世界的机器人任务中都优于最先进的2D模仿学习方法,如OpenVLA、Diffusion Policy和DexVLA。我们特别强调了PointVLA通过点云集成实现的几个关键优势:(1)少样本多任务,PointVLA仅使用20个演示就能成功执行四个不同的任务;(2)真实与照片的区分,PointVLA能够区分真实物体及其图像,利用3D世界知识来提高安全性和可靠性;(3)高度适应性,与传统的2D模仿学习方法不同,PointVLA使机器人能够适应训练数据中未见的不同桌子高度的物体。此外,PointVLA在长时程任务中表现出色,例如从移动的传送带上拾取和包装物体,展示了其在复杂、动态环境中泛化的能力。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型主要依赖于2D图像信息,这限制了它们在需要精确空间推理的机器人任务中的应用。重新训练这些模型以适应3D数据计算成本过高,而直接抛弃已有的2D预训练模型又会浪费大量资源。因此,如何在不进行大规模重新训练的前提下,有效地将3D信息融入到现有的VLA模型中,是一个亟待解决的问题。
核心思路:PointVLA的核心思路是在已有的预训练VLA模型基础上,通过一个轻量级的模块化结构注入3D点云信息。关键在于,该方法避免了对整个VLA模型进行重新训练,而是选择性地更新模型中对2D信息依赖较弱的部分,从而在利用现有2D预训练知识的同时,增强模型对3D环境的感知能力。
技术框架:PointVLA框架主要包含以下几个关键模块:1) 预训练的2D VLA模型(作为基础);2) 点云特征提取模块(将3D点云转换为特征向量);3) 轻量级3D特征注入模块(将点云特征融入到VLA模型中);4) 动作专家(根据融合后的特征生成动作指令)。整体流程是:首先,点云数据经过特征提取模块得到3D特征;然后,这些特征通过注入模块选择性地融入到预训练的VLA模型中;最后,融合了2D和3D信息的模型输出动作指令。
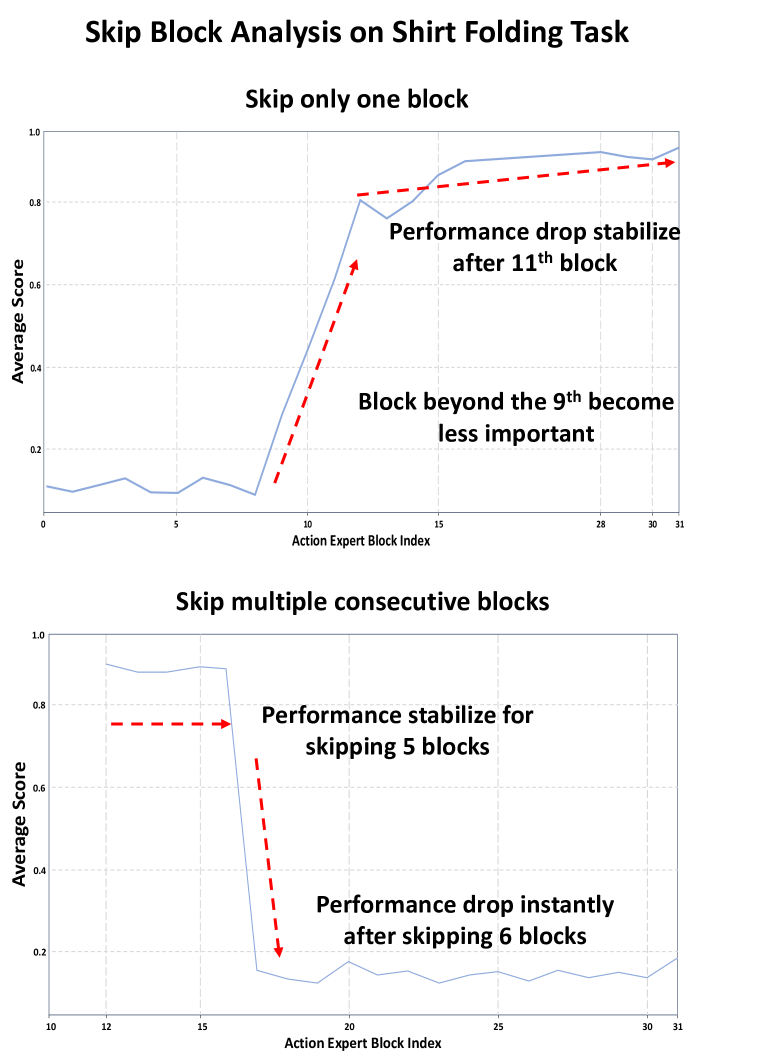
关键创新:PointVLA最重要的创新在于其“选择性注入”策略。通过“跳跃块分析”,论文识别出VLA模型中对2D信息依赖程度较低的模块(即“不太有用的块”),并将3D特征专门注入到这些模块中。这种方法最大限度地减少了对预训练模型原有知识的破坏,同时有效地提升了模型对3D环境的感知能力。与直接重新训练整个模型或盲目地将3D特征添加到所有模块相比,PointVLA的方法更加高效和有效。
关键设计:PointVLA的关键设计包括:1) 轻量级的3D特征注入模块,该模块的设计目标是在尽可能减少计算开销的同时,有效地融合3D特征;2) “跳跃块分析”方法,用于确定VLA模型中适合注入3D特征的模块。具体实现细节(如模块的具体网络结构、损失函数等)在论文中可能有所描述,但摘要中未明确提及。
🖼️ 关键图片

📊 实验亮点
PointVLA在多个机器人任务中取得了显著的性能提升。例如,在少样本多任务学习中,仅使用20个演示就能成功执行四个不同的任务。此外,PointVLA还能够区分真实物体及其照片,并适应不同高度的物体,这些都是传统2D模仿学习方法难以实现的。在长时程任务中,PointVLA也表现出了良好的泛化能力。
🎯 应用场景
PointVLA在机器人操作领域具有广泛的应用前景,例如:智能仓储、自动驾驶、家庭服务机器人等。通过增强机器人对3D环境的感知能力,可以提高其在复杂环境中的操作精度和鲁棒性。此外,该方法还可以应用于虚拟现实、增强现实等领域,提升用户与虚拟环境的交互体验。
📄 摘要(原文)
Vision-Language-Action (VLA) models excel at robotic tasks by leveraging large-scale 2D vision-language pretraining, but their reliance on RGB images limits spatial reasoning critical for real-world interaction. Retraining these models with 3D data is computationally prohibitive, while discarding existing 2D datasets wastes valuable resources. To bridge this gap, we propose PointVLA, a framework that enhances pre-trained VLAs with point cloud inputs without requiring retraining. Our method freezes the vanilla action expert and injects 3D features via a lightweight modular block. To identify the most effective way of integrating point cloud representations, we conduct a skip-block analysis to pinpoint less useful blocks in the vanilla action expert, ensuring that 3D features are injected only into these blocks--minimizing disruption to pre-trained representations. Extensive experiments demonstrate that PointVLA outperforms state-of-the-art 2D imitation learning methods, such as OpenVLA, Diffusion Policy and DexVLA, across both simulated and real-world robotic tasks. Specifically, we highlight several key advantages of PointVLA enabled by point cloud integration: (1) Few-shot multi-tasking, where PointVLA successfully performs four different tasks using only 20 demonstrations each; (2) Real-vs-photo discrimination, where PointVLA distinguishes real objects from their images, leveraging 3D world knowledge to improve safety and reliability; (3) Height adaptability, Unlike conventional 2D imitation learning methods, PointVLA enables robots to adapt to objects at varying table height that unseen in train data. Furthermore, PointVLA achieves strong performance in long-horizon tasks, such as picking and packing objects from a moving conveyor belt, showcasing its ability to generalize across complex, dynamic environments.