HIPPO-MAT: Decentralized Task Allocation Using GraphSAGE and Multi-Agent Deep Reinforcement Learning
作者: Lavanya Ratnabala, Robinroy Peter, Aleksey Fedoseev, Dzmitry Tsetserukou
分类: cs.MA, cs.RO
发布日期: 2025-03-08
备注: arXiv admin note: text overlap with arXiv:2502.02311
💡 一句话要点
HIPPO-MAT:基于图神经网络和多智能体深度强化学习的去中心化任务分配框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体系统 任务分配 图神经网络 深度强化学习 去中心化 GraphSAGE IPPO
📋 核心要点
- 现有去中心化任务分配方法难以在异构多智能体系统中实现动态、成本优化和冲突感知的任务分配,尤其是在复杂环境中。
- HIPPO-MAT框架结合图神经网络和多智能体深度强化学习,通过智能体间的信息共享和独立决策,实现高效的任务分配。
- 实验结果表明,该方法在无冲突成功率和可扩展性方面表现出色,并在真实机器人平台上进行了初步验证。
📝 摘要(中文)
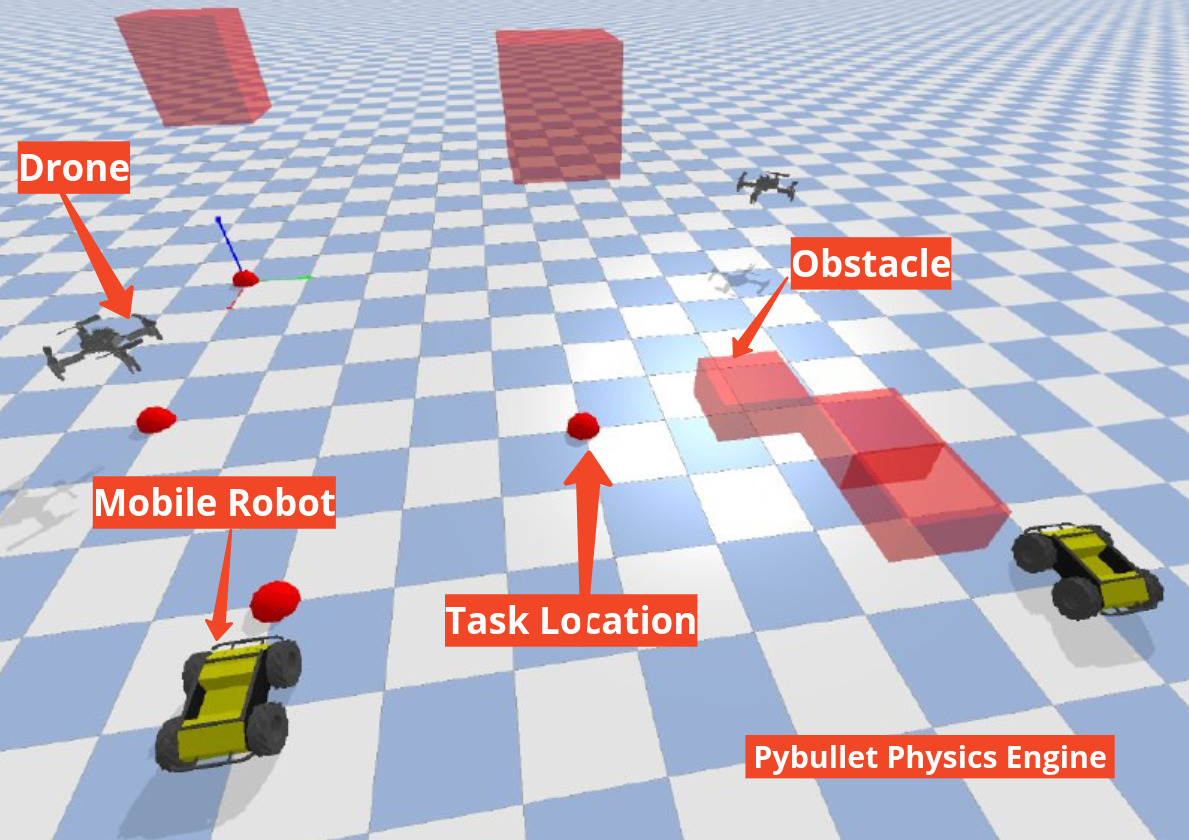
本文提出了一种名为HIPPO-MAT的框架,用于解决异构多智能体系统中去中心化的连续任务分配问题。该框架结合了图神经网络(GNN),利用GraphSAGE架构在每个智能体上计算独立的嵌入,以及用于多智能体深度强化学习的独立近端策略优化(IPPO)方法。在我们的系统中,无人机(UAV)和无人地面车辆(UGV)通过通信信道共享聚合的观测数据,同时独立处理这些输入以生成丰富的状态嵌入。这种设计实现了在3D网格环境中动态、成本优化、冲突感知的任务分配,而无需集中协调。集成了改进的A*路径规划器,以实现高效的路由和避碰。仿真实验证明了该方法在多达30个智能体时的可扩展性,并在JetBot ROS AI机器人上进行了初步的真实世界验证,每个机器人都在Jetson Nano上运行其模型,并通过ESP32-S3使用ESP-NOW协议进行通信,这证实了包含同步定位和建图(SLAM)的该方法的实际可行性。实验结果表明,我们的方法实现了高达92.5%的无冲突成功率,与集中式匈牙利方法相比,仅有16.49%的性能差距,同时优于基于贪婪方法的启发式去中心化基线。此外,该框架在多达30个智能体时表现出可扩展性,分配处理时间为0.32个模拟步长,并且能够稳健地响应动态生成的任务。
🔬 方法详解
问题定义:论文旨在解决异构多智能体系统(如无人机和无人车协同)中,如何在去中心化的环境下进行连续的任务分配。现有方法要么依赖集中式控制,要么采用启发式规则,难以在动态变化的环境中实现成本优化和冲突避免。
核心思路:核心思路是让每个智能体通过图神经网络学习其他智能体的状态信息,从而在局部做出更明智的决策。同时,利用多智能体强化学习训练智能体的策略,使其能够适应不同的任务和环境,最终实现全局的任务分配优化。
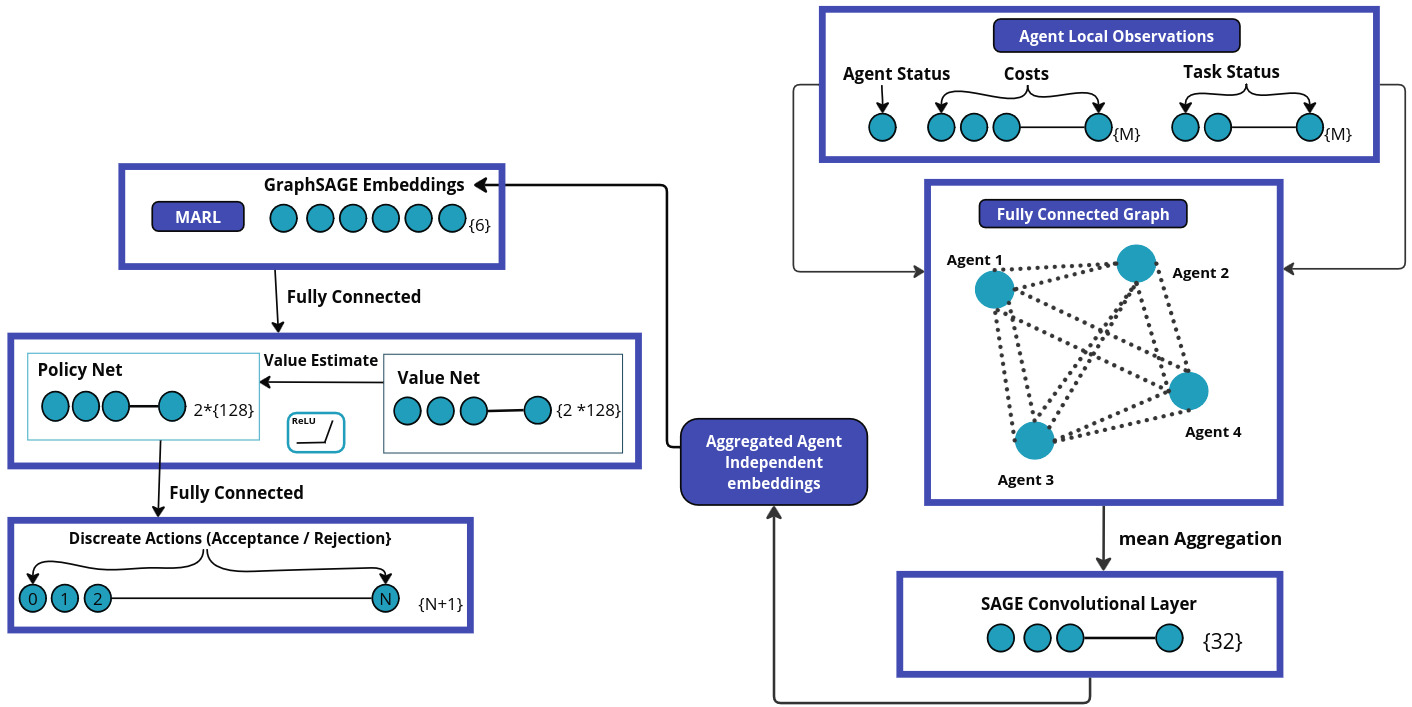
技术框架:HIPPO-MAT框架主要包含三个模块:1) 基于GraphSAGE的图神经网络,用于学习智能体之间的关系和状态信息;2) 基于IPPO(Independent Proximal Policy Optimization)的多智能体强化学习算法,用于训练每个智能体的策略;3) 改进的A*路径规划器,用于实现高效的路径规划和避碰。智能体通过通信信道共享观测数据,然后独立处理这些数据,生成状态嵌入,并使用IPPO进行策略学习。
关键创新:最重要的创新点在于将图神经网络和多智能体强化学习相结合,实现了去中心化的任务分配。GraphSAGE能够有效地提取智能体之间的关系信息,IPPO能够训练智能体在复杂环境中的策略。这种结合使得智能体能够在局部信息的基础上做出全局最优的决策。
关键设计:GraphSAGE用于聚合邻居节点的信息,生成每个智能体的嵌入表示。IPPO使用独立的策略网络和价值网络,每个智能体独立进行策略更新。A*路径规划器进行了修改,以适应动态环境和多智能体的协同。损失函数包括策略梯度损失和价值函数损失,用于优化智能体的策略和价值估计。
🖼️ 关键图片

📊 实验亮点
实验结果表明,HIPPO-MAT框架在无冲突成功率方面达到了92.5%,与集中式匈牙利方法相比,性能差距仅为16.49%,并且优于基于贪婪方法的启发式去中心化基线。此外,该框架在多达30个智能体时表现出良好的可扩展性,分配处理时间为0.32个模拟步长。真实机器人实验也验证了该方法的可行性。
🎯 应用场景
该研究成果可应用于多种领域,例如:灾后救援、环境监测、物流配送、智能交通等。在这些场景中,多个智能体需要协同完成任务,而集中式控制难以应对动态变化的环境。HIPPO-MAT框架提供了一种去中心化的解决方案,可以提高任务分配的效率和鲁棒性,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
This paper tackles decentralized continuous task allocation in heterogeneous multi-agent systems. We present a novel framework HIPPO-MAT that integrates graph neural networks (GNN) employing a GraphSAGE architecture to compute independent embeddings on each agent with an Independent Proximal Policy Optimization (IPPO) approach for multi-agent deep reinforcement learning. In our system, unmanned aerial vehicles (UAVs) and unmanned ground vehicles (UGVs) share aggregated observation data via communication channels while independently processing these inputs to generate enriched state embeddings. This design enables dynamic, cost-optimal, conflict-aware task allocation in a 3D grid environment without the need for centralized coordination. A modified A* path planner is incorporated for efficient routing and collision avoidance. Simulation experiments demonstrate scalability with up to 30 agents and preliminary real-world validation on JetBot ROS AI Robots, each running its model on a Jetson Nano and communicating through an ESP-NOW protocol using ESP32-S3, which confirms the practical viability of the approach that incorporates simultaneous localization and mapping (SLAM). Experimental results revealed that our method achieves a high 92.5% conflict-free success rate, with only a 16.49% performance gap compared to the centralized Hungarian method, while outperforming the heuristic decentralized baseline based on greedy approach. Additionally, the framework exhibits scalability with up to 30 agents with allocation processing of 0.32 simulation step time and robustness in responding to dynamically generated tasks.