Kaiwu: A Multimodal Manipulation Dataset and Framework for Robot Learning and Human-Robot Interaction
作者: Shuo Jiang, Haonan Li, Ruochen Ren, Yanmin Zhou, Zhipeng Wang, Bin He
分类: cs.RO, cs.AI
发布日期: 2025-03-07 (更新: 2025-06-03)
备注: 8 pages, 5 figures, Submitted to IEEE Robotics and Automation Letters (RAL)
💡 一句话要点
Kaiwu:用于机器人学习和人机交互的多模态操作数据集与框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态数据集 机器人学习 人机交互 灵巧操作 装配任务 运动捕捉 细粒度标注
📋 核心要点
- 当前机器人学习技术,如基础模型和人类示教学习,对大规模高质量数据集有巨大需求,这成为通用智能机器人领域的瓶颈。
- Kaiwu数据集通过集成人类、环境和机器人数据,并进行细粒度标注,提供了一个解决复杂装配场景中多模态数据缺失问题的方案。
- 该数据集包含多种模态信息,如手部运动、操作压力、声音、多视角视频等,旨在促进机器人学习、人机交互等领域的研究。
📝 摘要(中文)
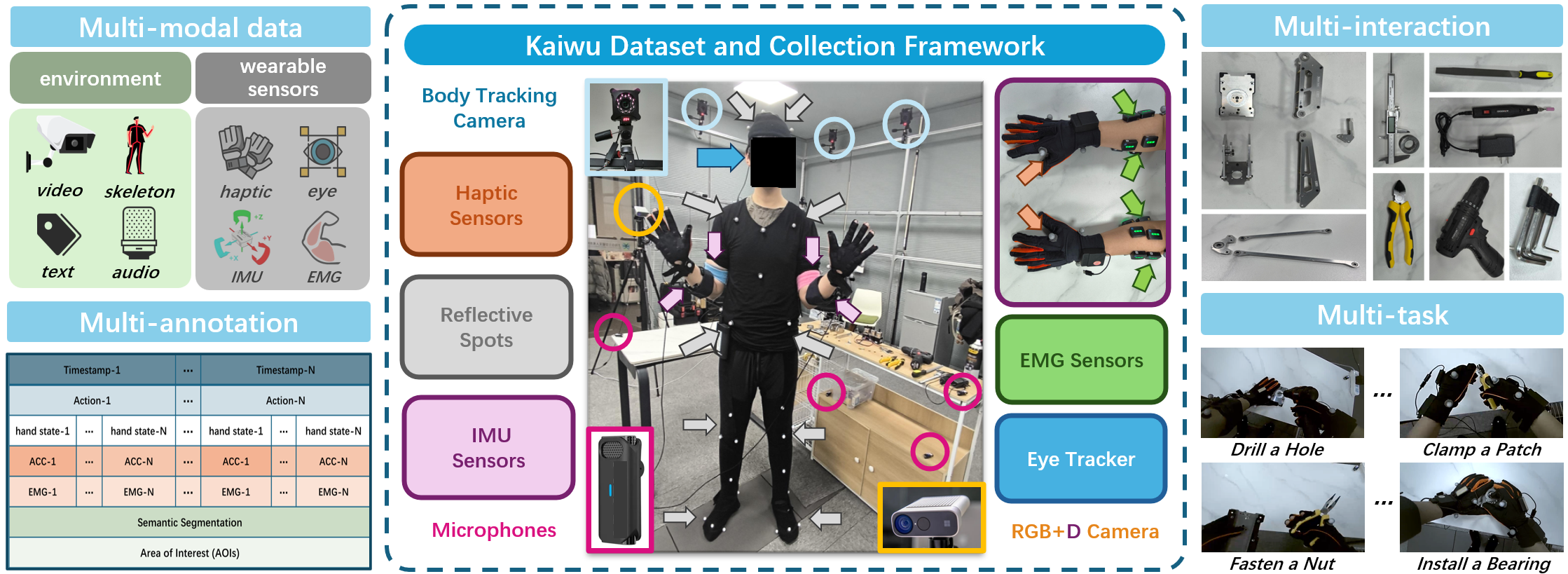
本文提出了Kaiwu多模态数据集,旨在解决复杂装配场景中真实世界同步多模态数据缺失的问题,尤其关注动力学信息和细粒度标注。该数据集提供了一个集成人类、环境和机器人数据收集的框架,包含20名受试者和30个交互对象,总计11664个集成动作实例。对于每个演示,记录了手部运动、操作压力、装配过程的声音、多视角视频、高精度运动捕捉信息、带有第一人称视频的眼动追踪、肌电信号。进行了基于绝对时间戳的细粒度多层次标注和语义分割标注。Kaiwu数据集旨在促进机器人学习、灵巧操作、人类意图研究和人机协作研究。
🔬 方法详解
问题定义:现有机器人学习方法,特别是模仿学习和基于基础模型的机器人控制,严重依赖于大规模、高质量的数据集。然而,在复杂的装配任务中,同步的多模态数据,尤其是包含动力学信息和细粒度标注的数据集非常稀缺,这限制了相关算法的性能和泛化能力。
核心思路:Kaiwu数据集的核心思路是构建一个全面的数据采集框架,能够同步记录人类在执行装配任务时的多种模态信息,包括视觉、触觉、听觉、运动捕捉和生理信号等。通过多模态数据的融合,可以更全面地理解人类的意图和行为,从而为机器人学习提供更丰富的训练信号。
技术框架:Kaiwu数据集的构建包含以下几个主要阶段:1) 数据采集框架搭建:设计能够同步采集多种模态数据的硬件和软件系统。2) 任务设计:选择具有代表性的复杂装配任务,例如螺丝拧紧、零件组装等。3) 数据采集:招募多名受试者,在数据采集框架下执行装配任务,记录各种模态的数据。4) 数据标注:对采集到的数据进行细粒度的标注,包括动作分割、语义标注、动力学信息标注等。
关键创新:Kaiwu数据集的关键创新在于其多模态数据的全面性和同步性,以及细粒度的标注。与现有的机器人数据集相比,Kaiwu数据集不仅包含视觉信息,还包含了触觉、听觉、运动捕捉和生理信号等多种模态的信息,可以更全面地反映人类在执行装配任务时的状态。此外,Kaiwu数据集还进行了细粒度的标注,可以为机器人学习提供更精确的训练信号。
关键设计:在数据采集方面,使用了多台同步相机进行多视角视频录制,使用力传感器记录操作压力,使用麦克风记录装配过程的声音,使用运动捕捉系统记录手部和身体的运动轨迹,使用眼动仪记录眼动信息,使用肌电传感器记录肌肉活动信号。在数据标注方面,采用了多层次的标注体系,包括动作分割、语义标注、动力学信息标注等。具体参数设置和损失函数等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
Kaiwu数据集包含11664个集成动作实例,涵盖20名受试者和30个交互对象。数据集提供了多种模态的信息,包括手部运动、操作压力、声音、多视角视频、高精度运动捕捉信息、眼动追踪和肌电信号。此外,数据集还进行了细粒度的多层次标注和语义分割标注。论文中没有提供具体的性能数据和对比基线,属于数据集发布,侧重数据收集和标注。
🎯 应用场景
Kaiwu数据集可广泛应用于机器人学习、灵巧操作、人机协作等领域。例如,可以利用该数据集训练机器人模仿人类的装配动作,提高机器人的灵巧性和适应性。此外,该数据集还可以用于研究人类的意图和行为,从而设计更智能、更自然的人机交互界面。未来,该数据集有望推动机器人技术在制造业、医疗保健等领域的应用。
📄 摘要(原文)
Cutting-edge robot learning techniques including foundation models and imitation learning from humans all pose huge demands on large-scale and high-quality datasets which constitute one of the bottleneck in the general intelligent robot fields. This paper presents the Kaiwu multimodal dataset to address the missing real-world synchronized multimodal data problems in the sophisticated assembling scenario,especially with dynamics information and its fine-grained labelling. The dataset first provides an integration of human,environment and robot data collection framework with 20 subjects and 30 interaction objects resulting in totally 11,664 instances of integrated actions. For each of the demonstration,hand motions,operation pressures,sounds of the assembling process,multi-view videos, high-precision motion capture information,eye gaze with first-person videos,electromyography signals are all recorded. Fine-grained multi-level annotation based on absolute timestamp,and semantic segmentation labelling are performed. Kaiwu dataset aims to facilitate robot learning,dexterous manipulation,human intention investigation and human-robot collaboration research.