Discrete Contrastive Learning for Diffusion Policies in Autonomous Driving
作者: Kalle Kujanpää, Daulet Baimukashev, Farzeen Munir, Shoaib Azam, Tomasz Piotr Kucner, Joni Pajarinen, Ville Kyrki
分类: cs.RO, cs.AI
发布日期: 2025-03-07
💡 一句话要点
提出基于离散对比学习的扩散策略,用于自动驾驶中模拟多样化人类驾驶行为。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自动驾驶 驾驶行为模拟 对比学习 扩散模型 条件生成
📋 核心要点
- 人类驾驶行为的多样性和差异性给自动驾驶车辆测试中准确模拟人类驾驶行为带来了挑战。
- 该论文利用对比学习提取驾驶风格字典,并使用量化离散化,进而学习条件扩散策略。
- 实验结果表明,该方法生成的驾驶行为比现有机器学习方法更安全,更接近人类驾驶风格。
📝 摘要(中文)
本文提出了一种新颖的方法,利用对比学习从现有人类驾驶数据中提取驾驶风格字典,从而应对自动驾驶车辆测试中模拟准确且丰富的人类驾驶行为的挑战。通过量化离散化这些风格,并将其用于学习条件扩散策略,以模拟人类驾驶员。经验评估表明,该方法生成的行为比基于机器学习的基线方法更安全、更像人类。我们相信这有潜力实现更高的真实感和更有效的技术,以评估和提高自动驾驶车辆的性能。
🔬 方法详解
问题定义:论文旨在解决自动驾驶车辆测试中,难以准确且真实地模拟人类驾驶行为的问题。现有方法难以捕捉人类驾驶风格的多样性和差异性,导致模拟结果不够真实,影响自动驾驶系统的测试效果。
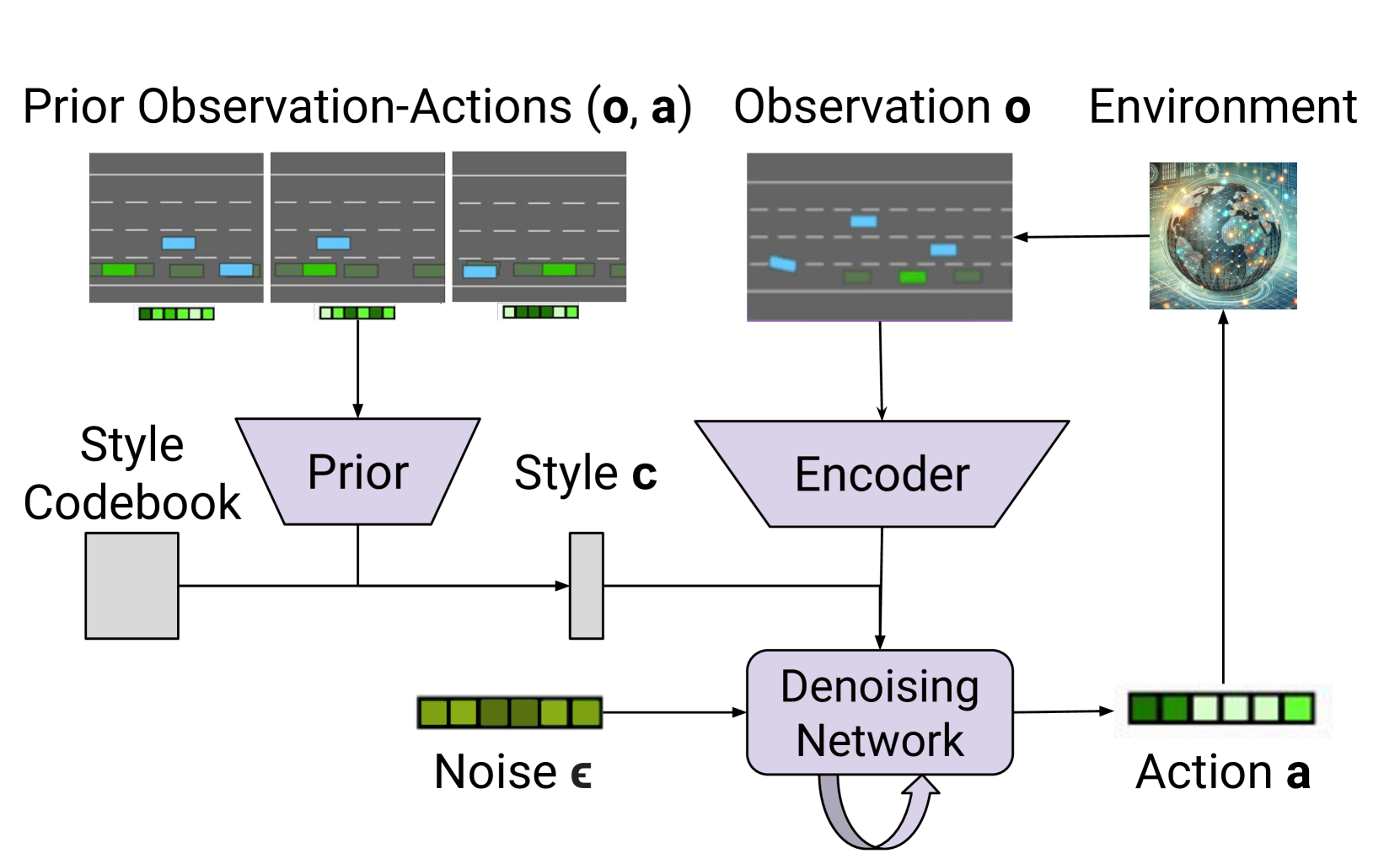
核心思路:论文的核心思路是利用对比学习从大量人类驾驶数据中提取出具有代表性的驾驶风格,并将其离散化为可控的风格编码。然后,使用这些风格编码作为条件,训练一个扩散模型,从而生成具有不同风格的人类驾驶行为。这样,可以通过控制风格编码来模拟不同驾驶员的行为,提高模拟的真实性和多样性。
技术框架:整体框架包含以下几个主要阶段:1) 数据收集与预处理:收集大量人类驾驶数据,并进行清洗和格式化。2) 对比学习:使用对比学习方法,从驾驶数据中学习驾驶风格的嵌入表示。3) 风格离散化:使用量化方法将连续的风格嵌入离散化为有限个风格编码。4) 条件扩散策略学习:使用离散化的风格编码作为条件,训练一个扩散模型,用于生成驾驶行为。
关键创新:最重要的技术创新点在于将对比学习和扩散模型结合起来,用于模拟人类驾驶行为。对比学习用于提取驾驶风格,扩散模型用于生成驾驶行为。这种结合可以有效地捕捉人类驾驶行为的多样性和复杂性。此外,将连续的驾驶风格嵌入离散化,使得风格控制更加方便和直观。
关键设计:论文中一些关键的设计包括:1) 使用Triplet Loss进行对比学习,以学习驾驶风格的嵌入表示。2) 使用K-means聚类对风格嵌入进行量化,得到离散的风格编码。3) 使用条件扩散模型,以风格编码作为条件,生成驾驶行为。4) 损失函数包括行为预测损失和风格一致性损失,以保证生成行为的准确性和风格的真实性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法生成的驾驶行为在安全性和类人程度上均优于现有基于机器学习的基线方法。具体而言,该方法生成的驾驶行为与真实人类驾驶行为的相似度更高,且发生碰撞的概率更低。这些结果验证了该方法在模拟人类驾驶行为方面的有效性。
🎯 应用场景
该研究成果可应用于自动驾驶系统的仿真测试与验证,通过模拟更真实、多样的人类驾驶行为,提高自动驾驶系统在复杂交通环境下的安全性和可靠性。此外,该方法还可用于生成对抗样本,评估自动驾驶系统的鲁棒性,并为自动驾驶策略的改进提供数据支持。
📄 摘要(原文)
Learning to perform accurate and rich simulations of human driving behaviors from data for autonomous vehicle testing remains challenging due to human driving styles' high diversity and variance. We address this challenge by proposing a novel approach that leverages contrastive learning to extract a dictionary of driving styles from pre-existing human driving data. We discretize these styles with quantization, and the styles are used to learn a conditional diffusion policy for simulating human drivers. Our empirical evaluation confirms that the behaviors generated by our approach are both safer and more human-like than those of the machine-learning-based baseline methods. We believe this has the potential to enable higher realism and more effective techniques for evaluating and improving the performance of autonomous vehicles.