Refined Policy Distillation: From VLA Generalists to RL Experts
作者: Tobias Jülg, Wolfram Burgard, Florian Walter
分类: cs.RO, cs.LG
发布日期: 2025-03-06 (更新: 2025-08-04)
备注: accepted for publication at IROS 2026
💡 一句话要点
提出精炼策略蒸馏(RPD),提升VLA模型在机器人操作任务中的性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 策略蒸馏 强化学习 视觉语言动作模型 机器人操作 行为克隆
📋 核心要点
- VLA模型虽然具有良好的泛化性,但在机器人操作任务中的成功率低于专家策略,且对环境变化敏感。
- RPD方法结合在线强化学习和行为克隆,利用VLA教师策略指导学生策略探索,实现策略的精炼和性能提升。
- 实验表明,RPD方法能够使学生策略超越教师VLA,在不同奖励设置和视角下均表现出更快的收敛速度和更好的泛化能力。
📝 摘要(中文)
视觉-语言-动作模型(VLA)在真实世界实验中展现了卓越的泛化能力。然而,它们的成功率通常不如专家策略,并且在设置改变时需要微调。本文提出了一种新的基于强化学习(RL)的策略精炼方法,即精炼策略蒸馏(RPD),它通过结合在线RL与行为克隆来弥合这一性能差距。RPD的核心思想是通过使用教师VLA的动作来指导学生策略在RL探索期间的行为,从而将VLA提炼和精炼为紧凑、高性能的专家策略,从而提高样本效率并加快收敛速度。我们通过ManiSkill3的微调版本Octo和OpenVLA来补充我们的方法,以在模拟中评估RPD。虽然这是应用RL的关键要求,但它也产生了超越现有VLA在真实世界环境中性能研究的新见解。在各种操作任务中的实验结果表明,RPD使RL学生能够学习在密集和稀疏奖励设置中都优于VLA教师的专家策略,同时实现比RL基线更快的收敛速度。我们的方法甚至对相机视角的改变具有鲁棒性,并且可以推广到底层VLA无法解决的任务变体。我们的代码、数据集、VLA检查点和视频可在https://refined-policy-distillation.github.io获得。
🔬 方法详解
问题定义:论文旨在解决视觉-语言-动作模型(VLA)在机器人操作任务中,虽然具备良好的泛化能力,但性能与专家策略存在差距,且对环境变化适应性较弱的问题。现有方法难以充分利用VLA的先验知识,导致强化学习训练效率低下。
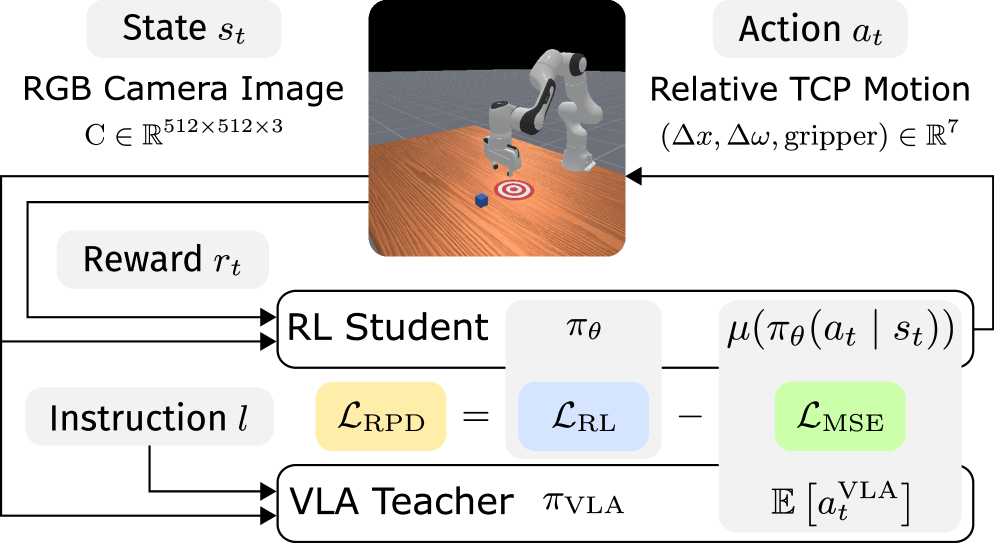
核心思路:论文的核心思路是利用精炼策略蒸馏(RPD)方法,将VLA模型作为教师策略,指导强化学习训练的学生策略。通过行为克隆初始化学生策略,并利用教师策略的动作分布引导学生策略的探索方向,从而提高样本效率和收敛速度。
技术框架:RPD方法包含两个主要部分:VLA教师策略和RL学生策略。首先,使用VLA模型作为教师策略,提供动作指导。然后,使用行为克隆初始化RL学生策略,使其具备一定的先验知识。在强化学习训练过程中,学生策略根据环境状态选择动作,并与教师策略的动作进行比较,计算损失函数,从而引导学生策略学习教师策略的优点。
关键创新:RPD的关键创新在于将VLA模型的泛化能力与强化学习的优化能力相结合。通过行为克隆和动作分布引导,有效地利用了VLA模型的先验知识,加速了强化学习的训练过程,并最终超越了VLA教师策略的性能。
关键设计:RPD的关键设计包括:1) 使用行为克隆初始化学生策略;2) 设计合适的损失函数,例如KL散度,用于衡量学生策略和教师策略动作分布的差异;3) 调整强化学习算法的探索策略,例如使用ε-greedy策略,并根据教师策略的指导进行调整;4) 仔细选择合适的强化学习算法,例如PPO或SAC,并调整其超参数。
🖼️ 关键图片
📊 实验亮点
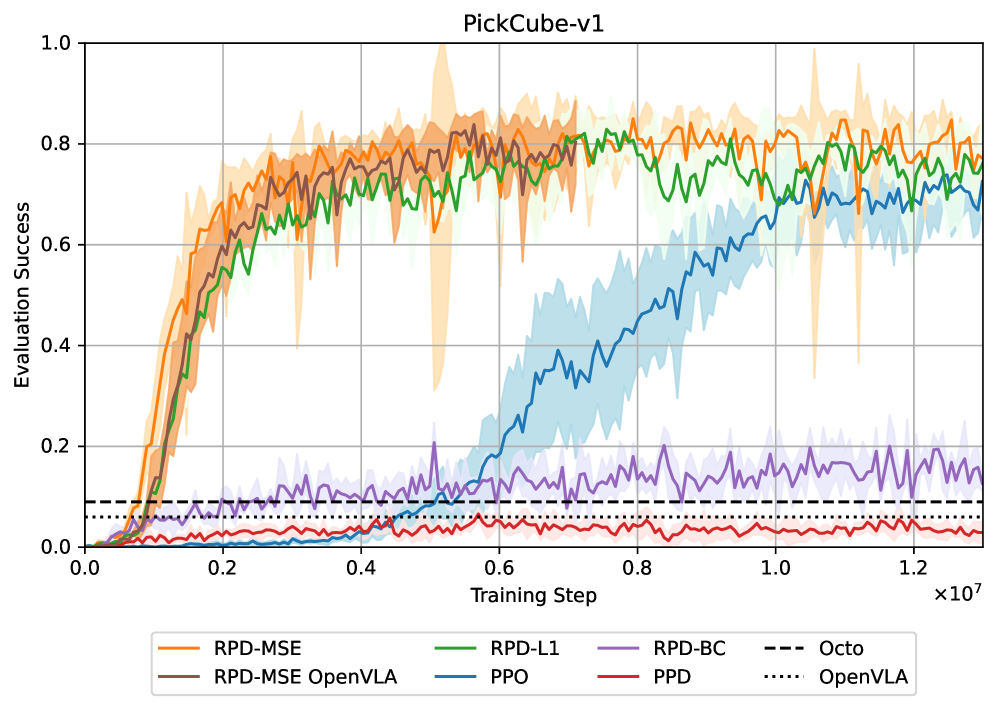
实验结果表明,RPD方法在ManiSkill3模拟环境中,能够使RL学生策略在多个操作任务中超越VLA教师策略,并且比纯RL基线方法收敛速度更快。例如,在特定任务中,RPD方法可以将成功率提高10%-20%,同时将训练时间缩短30%-50%。此外,RPD方法还表现出对相机视角变化的鲁棒性,并能够泛化到VLA无法解决的任务变体。
🎯 应用场景
该研究成果可应用于各种机器人操作任务,例如物体抓取、装配、导航等。通过利用预训练的VLA模型,可以快速训练出高性能的机器人控制策略,降低开发成本,提高机器人智能化水平。此外,该方法还可以推广到其他领域,例如自动驾驶、游戏AI等。
📄 摘要(原文)
Vision-Language-Action Models (VLAs) have demonstrated remarkable generalization capabilities in real-world experiments. However, their success rates are often not on par with expert policies, and they require fine-tuning when the setup changes. In this work, we introduce Refined Policy Distillation (RPD), a novel Reinforcement Learning (RL)-based policy refinement method that bridges this performance gap through a combination of on-policy RL with behavioral cloning. The core idea of RPD is to distill and refine VLAs into compact, high-performing expert policies by guiding the student policy during RL exploration using the actions of a teacher VLA, resulting in increased sample efficiency and faster convergence. We complement our method by fine-tuned versions of Octo and OpenVLA for ManiSkill3 to evaluate RPD in simulation. While this is a key requirement for applying RL, it also yields new insights beyond existing studies on VLA performance in real-world settings. Our experimental results across various manipulation tasks show that RPD enables the RL student to learn expert policies that outperform the VLA teacher in both dense and sparse reward settings, while also achieving faster convergence than the RL baseline. Our approach is even robust to changes in camera perspective and can generalize to task variations that the underlying VLA cannot solve. Our code, dataset, VLA checkpoints, and videos are available at https://refined-policy-distillation.github.io