Data-Efficient Learning from Human Interventions for Mobile Robots
作者: Zhenghao Peng, Zhizheng Liu, Bolei Zhou
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-03-06
备注: ICRA 2025. Webpage: https://metadriverse.github.io/pvp4real/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
PVP4Real:一种基于在线人工干预的移动机器人高效学习方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人机协同学习 移动机器人 模仿学习 强化学习 在线学习 数据效率 人工干预
📋 核心要点
- 传统模仿学习和强化学习方法在移动机器人任务中面临数据需求大、奖励函数设计难和仿真到现实差距等挑战。
- PVP4Real结合模仿学习和强化学习,通过在线人工干预和演示,实现高效的实时策略学习,无需预训练或奖励函数。
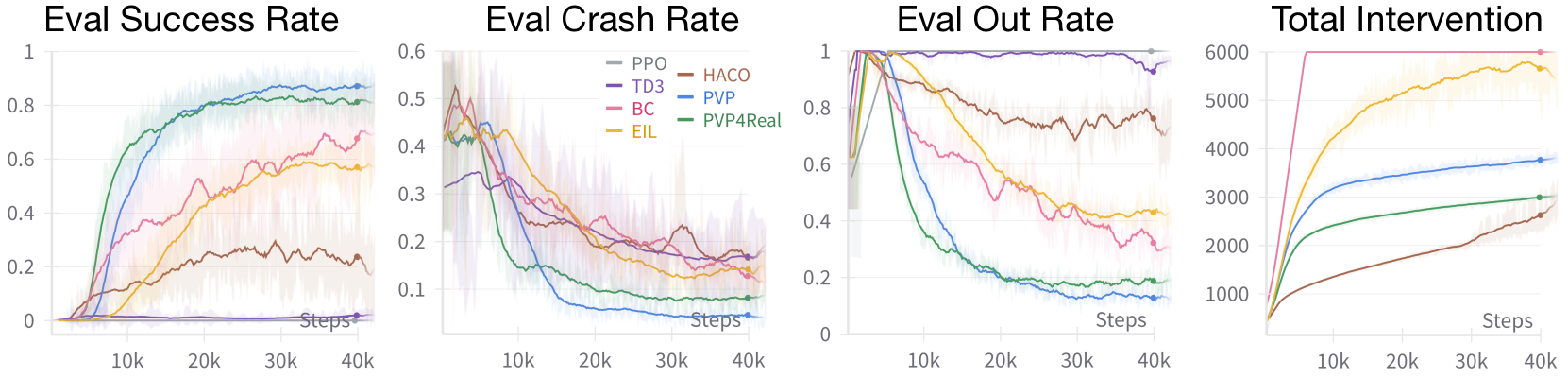
- 实验结果表明,PVP4Real能够在15分钟内完成两种不同机器人的训练,验证了人机协同学习在提高数据效率方面的潜力。
📝 摘要(中文)
移动机器人在自主配送和酒店服务等应用中至关重要。由于其鲁棒性和泛化性,应用基于学习的方法来解决移动机器人任务越来越受欢迎。传统的模仿学习(IL)和强化学习(RL)方法虽然具有适应性,但需要大量数据集、精心设计的奖励函数,并面临着从仿真到现实的差距,这使得它们在高效和安全的实际部署中面临挑战。我们提出了一种在线人机协同学习方法PVP4Real,它结合了IL和RL来解决这些问题。PVP4Real能够从在线人工干预和演示中进行高效的实时策略学习,无需奖励或任何预训练,从而显著提高数据效率和训练安全性。我们通过在两个不同的机器人(一个腿式四足机器人和一个轮式配送机器人)上训练两个移动机器人任务来验证我们的方法,其中一个任务甚至使用原始RGBD图像作为观察。训练在15分钟内完成。我们的实验表明,人机协同学习在解决现实机器人任务中的数据效率问题方面具有广阔的前景。
🔬 方法详解
问题定义:论文旨在解决移动机器人学习中数据效率低下的问题。传统的模仿学习和强化学习方法需要大量数据,且在实际部署中面临仿真到现实的差距。此外,强化学习需要精心设计的奖励函数,这在复杂的机器人任务中非常困难。这些问题限制了学习方法在真实机器人应用中的可行性。
核心思路:论文的核心思路是利用在线人工干预和演示来指导机器人的学习过程。通过让人类专家在机器人执行任务时提供实时的干预和示范,机器人可以从这些高质量的交互数据中学习到有效的策略。这种方法结合了模仿学习和强化学习的优点,可以在少量数据下快速学习到鲁棒的策略。
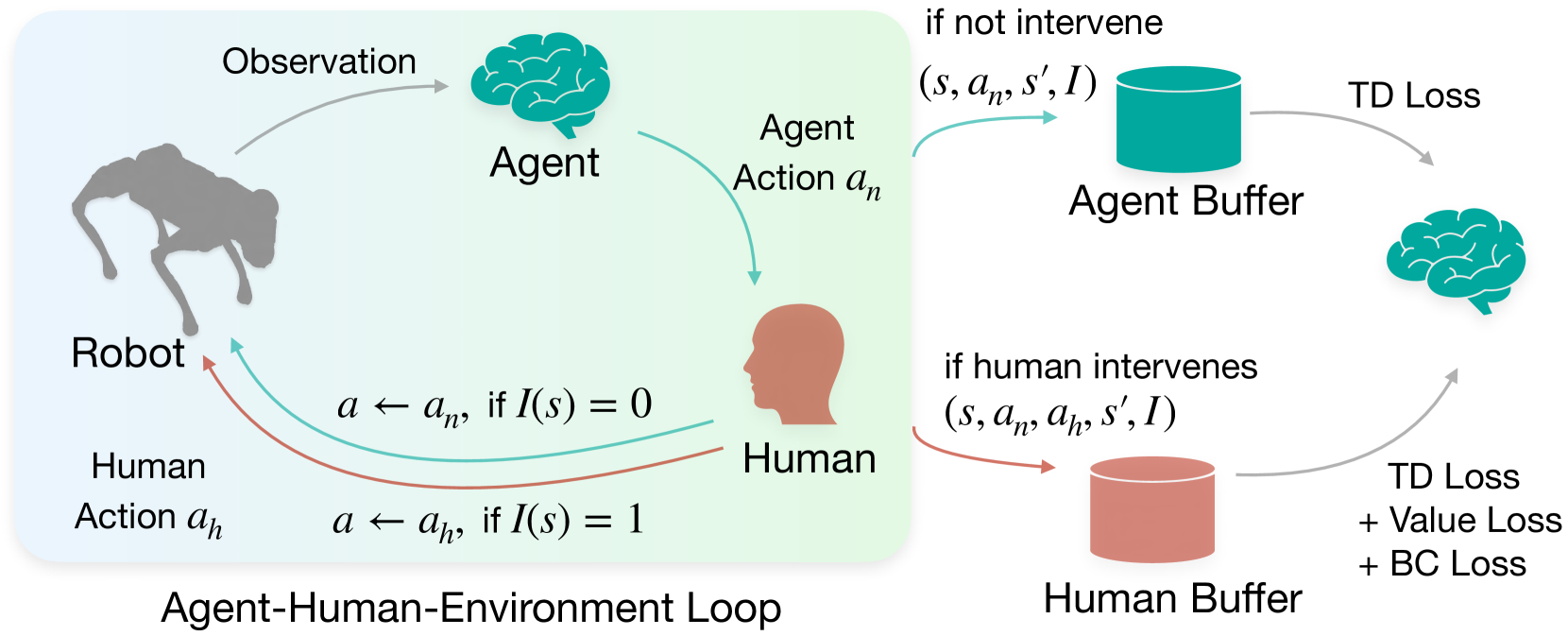
技术框架:PVP4Real的技术框架主要包含以下几个模块:1) 机器人环境交互模块:机器人与真实环境进行交互,获取状态信息。2) 人工干预模块:人类操作员监控机器人的行为,并在必要时进行干预,提供示范动作。3) 策略学习模块:该模块基于模仿学习和强化学习算法,利用机器人自身经验和人类干预数据来更新策略。4) 策略执行模块:机器人根据学习到的策略执行动作。整个流程是一个在线循环,机器人不断与环境交互,接受人类干预,并更新策略。
关键创新:PVP4Real的关键创新在于其在线人机协同学习的方式。与传统的离线学习方法不同,PVP4Real允许人类专家在机器人执行任务的过程中实时提供指导,从而使机器人能够更快地适应环境变化并学习到更有效的策略。此外,该方法无需预训练或奖励函数,降低了学习的复杂性。
关键设计:PVP4Real的具体技术细节包括:1) 状态表示:论文中使用了RGBD图像作为机器人的状态输入,这使得机器人能够感知周围环境。2) 动作空间:根据不同的机器人任务,定义了不同的动作空间。3) 策略学习算法:论文中使用了模仿学习和强化学习相结合的算法,具体算法细节未知。4) 人工干预策略:人类操作员根据机器人的行为和任务目标,决定何时进行干预以及如何进行干预。具体的干预策略未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PVP4Real能够在15分钟内完成两种不同机器人的训练,包括一个腿式四足机器人和一个轮式配送机器人。其中一个任务甚至使用原始RGBD图像作为观察。与传统的离线学习方法相比,PVP4Real显著提高了数据效率和训练安全性,验证了人机协同学习在解决现实机器人任务中的潜力。
🎯 应用场景
该研究成果可广泛应用于各种移动机器人应用场景,例如自主配送、物流搬运、家庭服务、安防巡逻等。通过人机协同学习,可以降低机器人部署的成本和难度,提高机器人的适应性和智能化水平。未来,该方法有望应用于更复杂的机器人任务,例如灾难救援、医疗辅助等。
📄 摘要(原文)
Mobile robots are essential in applications such as autonomous delivery and hospitality services. Applying learning-based methods to address mobile robot tasks has gained popularity due to its robustness and generalizability. Traditional methods such as Imitation Learning (IL) and Reinforcement Learning (RL) offer adaptability but require large datasets, carefully crafted reward functions, and face sim-to-real gaps, making them challenging for efficient and safe real-world deployment. We propose an online human-in-the-loop learning method PVP4Real that combines IL and RL to address these issues. PVP4Real enables efficient real-time policy learning from online human intervention and demonstration, without reward or any pretraining, significantly improving data efficiency and training safety. We validate our method by training two different robots -- a legged quadruped, and a wheeled delivery robot -- in two mobile robot tasks, one of which even uses raw RGBD image as observation. The training finishes within 15 minutes. Our experiments show the promising future of human-in-the-loop learning in addressing the data efficiency issue in real-world robotic tasks. More information is available at: https://metadriverse.github.io/pvp4real/